 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Shortcuts in Language Models with Soft Label Encoding
Paper and Code
Sep 17, 2023
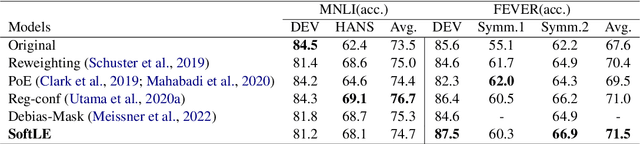
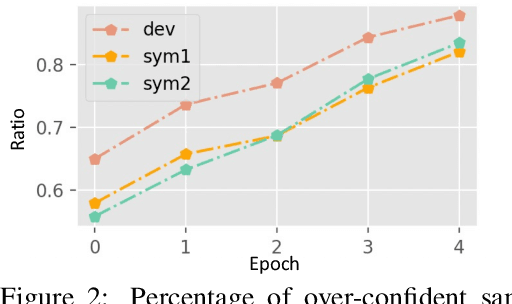

Recent research has shown that large language models rely on spurious correlations in the data for natural language understanding (NLU) tasks. In this work, we aim to answer the following research question: Can we reduce spurious correlations by modifying the ground truth labels of the training data? Specifically, we propose a simple yet effective debiasing framework, named Soft Label Encoding (SoftLE). We first train a teacher model with hard labels to determine each sample's degree of relying on shortcuts. We then add one dummy class to encode the shortcut degree, which is used to smooth other dimensions in the ground truth label to generate soft labels. This new ground truth label is used to train a more robust student model. Extensive experiments on two NLU benchmark tasks demonstrate that SoftLE significantly improves out-of-distribution generalization while maintaining satisfactory in-distribution accuracy.