 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Caption Preference Optimization for Diffusion Models
Feb 09, 2025


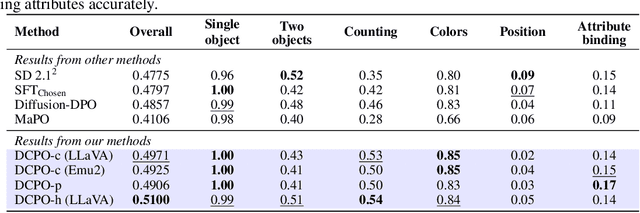
Recent advancements in human preference optimization, originally developed for Large Language Models (LLMs), have shown significant potential in improving text-to-image diffusion models. These methods aim to learn the distribution of preferred samples while distinguishing them from less preferred ones. However, existing preference datasets often exhibit overlap between these distributions, leading to a conflict distribution. Additionally, we identified that input prompts contain irrelevant information for less preferred images, limiting the denoising network's ability to accurately predict noise in preference optimization methods, known as the irrelevant prompt issue. To address these challenges, we propose Dual Caption Preference Optimization (DCPO), a novel approach that utilizes two distinct captions to mitigate irrelevant prompts. To tackle conflict distribution, we introduce the Pick-Double Caption dataset, a modified version of Pick-a-Pic v2 with separate captions for preferred and less preferred images. We further propose three different strategies for generating distinct captions: captioning, perturbation, and hybrid methods. Our experiments show that DCPO significantly improves image quality and relevance to prompts, outperforming Stable Diffusion (SD) 2.1, SFT_Chosen, Diffusion-DPO, and MaPO across multiple metrics, including Pickscore, HPSv2.1, GenEval, CLIPscore, and ImageReward, fine-tuned on SD 2.1 as the backbone.
Investigating the Shortcomings of LLMs in Step-by-Step Legal Reasoning
Feb 08, 2025



Reasoning abilities of LLMs have been a key focus in recent years. One challenging reasoning domain with interesting nuances is legal reasoning, which requires careful application of rules, and precedents while balancing deductive and analogical reasoning, and conflicts between rules. Although there have been a few works on using LLMs for legal reasoning, their focus has been on overall accuracy. In this paper, we dig deeper to do a step-by-step analysis and figure out where they commit errors. We use the college-level Multiple Choice Question-Answering (MCQA) task from the \textit{Civil Procedure} dataset and propose a new error taxonomy derived from initial manual analysis of reasoning chains with respect to several LLMs, including two objective measures: soundness and correctness scores. We then develop an LLM-based automated evaluation framework to identify reasoning errors and evaluate the performance of LLMs. The computation of soundness and correctness on the dataset using the auto-evaluator framework reveals several interesting insights. Furthermore, we show that incorporating the error taxonomy as feedback in popular prompting techniques marginally increases LLM performance. Our work will also serve as an evaluation framework that can be used in detailed error analysis of reasoning chains for logic-intensive complex tasks.
ExpressivityArena: Can LLMs Express Information Implicitly?
Nov 12, 2024While Large Language Models (LLMs) have demonstrated remarkable performance in certain dimensions, their ability to express implicit language cues that human use for effective communication remains unclear. This paper presents ExpressivityArena, a Python library for measuring the implicit communication abilities of LLMs. We provide a comprehensive framework to evaluate expressivity of arbitrary LLMs and explore its practical implications. To this end, we refine the definition and measurements of ``expressivity,'' and use our framework in a set of small experiments. These experiments test LLMs in creative and logical tasks such as poetry, coding, and emotion-based responses. They are then evaluated by an automated grader, through ExpressivityArena, which we verify to be the most pragmatic for testing expressivity. Building on these experiments, we deepen our understanding of the expressivity of LLMs by assessing their ability to remain expressive in conversations. Our findings indicate that LLMs are capable of generating and understanding expressive content, however, with some limitations. These insights will inform the future development and deployment of expressive LLMs. We provide the code for ExpressivityArena alongside our paper.
Fairness in Autonomous Driving: Towards Understanding Confounding Factors in Object Detection under Challenging Weather
May 31, 2024The deployment of autonomous vehicles (AVs) is rapidly expanding to numerous cities. At the heart of AVs, the object detection module assumes a paramount role, directly influencing all downstream decision-making tasks by considering the presence of nearby pedestrians, vehicles, and more. Despite high accuracy of pedestrians detected on held-out datasets, the potential presence of algorithmic bias in such object detectors, particularly in challenging weather conditions, remains unclear. This study provides a comprehensive empirical analysis of fairness in detecting pedestrians in a state-of-the-art transformer-based object detector. In addition to classical metrics, we introduce novel probability-based metrics to measure various intricate properties of object detection. Leveraging the state-of-the-art FACET dataset and the Carla high-fidelity vehicle simulator, our analysis explores the effect of protected attributes such as gender, skin tone, and body size on object detection performance in varying environmental conditions such as ambient darkness and fog. Our quantitative analysis reveals how the previously overlooked yet intuitive factors, such as the distribution of demographic groups in the scene, the severity of weather, the pedestrians' proximity to the AV, among others, affect object detection performance. Our code is available at https://github.com/bimsarapathiraja/fair-AV.
Multiclass Confidence and Localization Calibration for Object Detection
Jun 14, 2023



Albeit achieving high predictive accuracy across many challenging computer vision problems, recent studies suggest that deep neural networks (DNNs) tend to make overconfident predictions, rendering them poorly calibrated. Most of the existing attempts for improving DNN calibration are limited to classification tasks and restricted to calibrating in-domain predictions. Surprisingly, very little to no attempts have been made in studying the calibration of object detection methods, which occupy a pivotal space in vision-based security-sensitive, and safety-critical applications. In this paper, we propose a new train-time technique for calibrating modern object detection methods. It is capable of jointly calibrating multiclass confidence and box localization by leveraging their predictive uncertainties. We perform extensive experiments on several in-domain and out-of-domain detection benchmarks. Results demonstrate that our proposed train-time calibration method consistently outperforms several baselines in reducing calibration error for both in-domain and out-of-domain predictions. Our code and models are available at https://github.com/bimsarapathiraja/MCCL.