Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Adaptive Document-Level Neural Machine Translation
Paper and Code
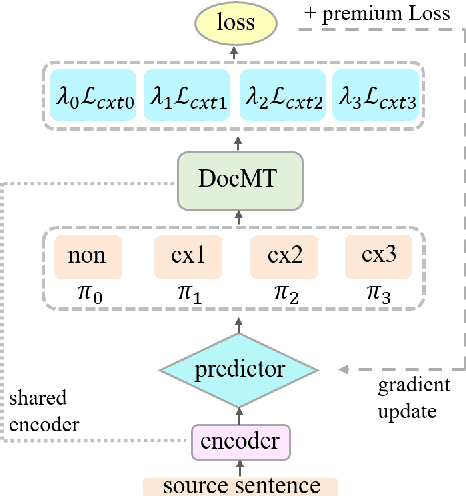
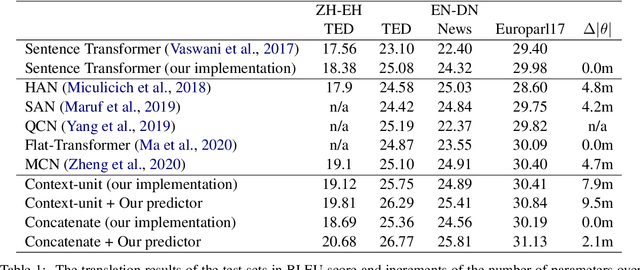
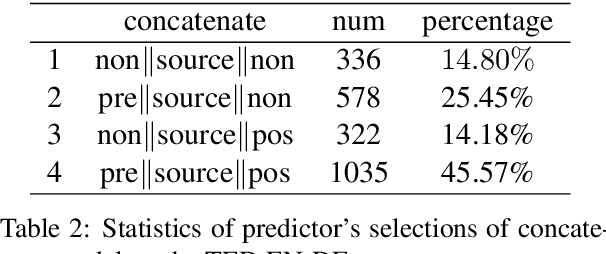
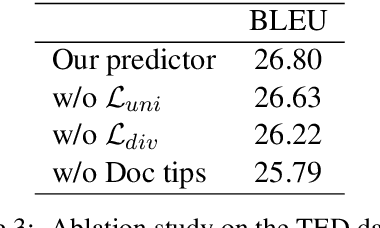
Most existing document-level neural machine translation (NMT) models leverage a fixed number of the previous or all global source sentences to handle the context-independent problem in standard NMT. However, the translating of each source sentence benefits from various sizes of context, and inappropriate context may harm the translation performance. In this work, we introduce a data-adaptive method that enables the model to adopt the necessary and useful context. Specifically, we introduce a light predictor into two document-level translation models to select the explicit context. Experiments demonstrate the proposed approach can significantly improve the performance over the previous methods with a gain up to 1.99 BLEU points.
View paper on