 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTripleFDS: Triple Feature Disentanglement and Synthesis for Scene Text Editing
Nov 17, 2025Scene Text Editing (STE) aims to naturally modify text in images while preserving visual consistency, the decisive factors of which can be divided into three parts, i.e., text style, text content, and background. Previous methods have struggled with incomplete disentanglement of editable attributes, typically addressing only one aspect - such as editing text content - thus limiting controllability and visual consistency. To overcome these limitations, we propose TripleFDS, a novel framework for STE with disentangled modular attributes, and an accompanying dataset called SCB Synthesis. SCB Synthesis provides robust training data for triple feature disentanglement by utilizing the "SCB Group", a novel construct that combines three attributes per image to generate diverse, disentangled training groups. Leveraging this construct as a basic training unit, TripleFDS first disentangles triple features, ensuring semantic accuracy through inter-group contrastive regularization and reducing redundancy through intra-sample multi-feature orthogonality. In the synthesis phase, TripleFDS performs feature remapping to prevent "shortcut" phenomena during reconstruction and mitigate potential feature leakage. Trained on 125,000 SCB Groups, TripleFDS achieves state-of-the-art image fidelity (SSIM of 44.54) and text accuracy (ACC of 93.58%) on the mainstream STE benchmarks. Besides superior performance, the more flexible editing of TripleFDS supports new operations such as style replacement and background transfer. Code: https://github.com/yusenbao01/TripleFDS
The best performance in the CARE 2025 -- Liver Task (LiSeg-Contrast): Contrast-Aware Semi-Supervised Segmentation with Domain Generalization and Test-Time Adaptation
Oct 05, 2025



Accurate liver segmentation from contrast-enhanced MRI is essential for diagnosis, treatment planning, and disease monitoring. However, it remains challenging due to limited annotated data, heterogeneous enhancement protocols, and significant domain shifts across scanners and institutions. Traditional image-to-image translation frameworks have made great progress in domain generalization, but their application is not straightforward. For example, Pix2Pix requires image registration, and cycle-GAN cannot be integrated seamlessly into segmentation pipelines. Meanwhile, these methods are originally used to deal with cross-modality scenarios, and often introduce structural distortions and suffer from unstable training, which may pose drawbacks in our single-modality scenario. To address these challenges, we propose CoSSeg-TTA, a compact segmentation framework for the GED4 (Gd-EOB-DTPA enhanced hepatobiliary phase MRI) modality built upon nnU-Netv2 and enhanced with a semi-supervised mean teacher scheme to exploit large amounts of unlabeled volumes. A domain adaptation module, incorporating a randomized histogram-based style appearance transfer function and a trainable contrast-aware network, enriches domain diversity and mitigates cross-center variability. Furthermore, a continual test-time adaptation strategy is employed to improve robustness during inference. Extensive experiments demonstrate that our framework consistently outperforms the nnU-Netv2 baseline, achieving superior Dice score and Hausdorff Distance while exhibiting strong generalization to unseen domains under low-annotation conditions.
Unsupervised Part Discovery via Descriptor-Based Masked Image Restoration with Optimized Constraints
Jul 16, 2025Part-level features are crucial for image understanding, but few studies focus on them because of the lack of fine-grained labels. Although unsupervised part discovery can eliminate the reliance on labels, most of them cannot maintain robustness across various categories and scenarios, which restricts their application range. To overcome this limitation, we present a more effective paradigm for unsupervised part discovery, named Masked Part Autoencoder (MPAE). It first learns part descriptors as well as a feature map from the inputs and produces patch features from a masked version of the original images. Then, the masked regions are filled with the learned part descriptors based on the similarity between the local features and descriptors. By restoring these masked patches using the part descriptors, they become better aligned with their part shapes, guided by appearance features from unmasked patches. Finally, MPAE robustly discovers meaningful parts that closely match the actual object shapes, even in complex scenarios. Moreover, several looser yet more effective constraints are proposed to enable MPAE to identify the presence of parts across various scenarios and categories in an unsupervised manner. This provides the foundation for addressing challenges posed by occlusion and for exploring part similarity across multiple categories. Extensive experiments demonstrate that our method robustly discovers meaningful parts across various categories and scenarios. The code is available at the project https://github.com/Jiahao-UTS/MPAE.
Cross-DINO: Cross the Deep MLP and Transformer for Small Object Detection
May 28, 2025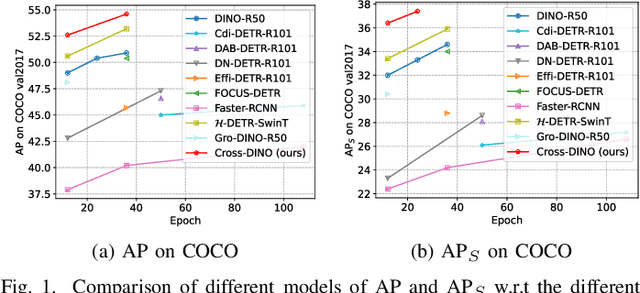



Small Object Detection (SOD) poses significant challenges due to limited information and the model's low class prediction score. While Transformer-based detectors have shown promising performance, their potential for SOD remains largely unexplored. In typical DETR-like frameworks, the CNN backbone network, specialized in aggregating local information, struggles to capture the necessary contextual information for SOD. The multiple attention layers in the Transformer Encoder face difficulties in effectively attending to small objects and can also lead to blurring of features. Furthermore, the model's lower class prediction score of small objects compared to large objects further increases the difficulty of SOD. To address these challenges, we introduce a novel approach called Cross-DINO. This approach incorporates the deep MLP network to aggregate initial feature representations with both short and long range information for SOD. Then, a new Cross Coding Twice Module (CCTM) is applied to integrate these initial representations to the Transformer Encoder feature, enhancing the details of small objects. Additionally, we introduce a new kind of soft label named Category-Size (CS), integrating the Category and Size of objects. By treating CS as new ground truth, we propose a new loss function called Boost Loss to improve the class prediction score of the model. Extensive experimental results on COCO, WiderPerson, VisDrone, AI-TOD, and SODA-D datasets demonstrate that Cross-DINO efficiently improves the performance of DETR-like models on SOD. Specifically, our model achieves 36.4% APs on COCO for SOD with only 45M parameters, outperforming the DINO by +4.4% APS (36.4% vs. 32.0%) with fewer parameters and FLOPs, under 12 epochs training setting. The source codes will be available at https://github.com/Med-Process/Cross-DINO.
Open-Det: An Efficient Learning Framework for Open-Ended Detection
May 27, 2025Open-Ended object Detection (OED) is a novel and challenging task that detects objects and generates their category names in a free-form manner, without requiring additional vocabularies during inference. However, the existing OED models, such as GenerateU, require large-scale datasets for training, suffer from slow convergence, and exhibit limited performance. To address these issues, we present a novel and efficient Open-Det framework, consisting of four collaborative parts. Specifically, Open-Det accelerates model training in both the bounding box and object name generation process by reconstructing the Object Detector and the Object Name Generator. To bridge the semantic gap between Vision and Language modalities, we propose a Vision-Language Aligner with V-to-L and L-to-V alignment mechanisms, incorporating with the Prompts Distiller to transfer knowledge from the VLM into VL-prompts, enabling accurate object name generation for the LLM. In addition, we design a Masked Alignment Loss to eliminate contradictory supervision and introduce a Joint Loss to enhance classification, resulting in more efficient training. Compared to GenerateU, Open-Det, using only 1.5% of the training data (0.077M vs. 5.077M), 20.8% of the training epochs (31 vs. 149), and fewer GPU resources (4 V100 vs. 16 A100), achieves even higher performance (+1.0% in APr). The source codes are available at: https://github.com/Med-Process/Open-Det.
Mitigating Knowledge Discrepancies among Multiple Datasets for Task-agnostic Unified Face Alignment
Mar 28, 2025


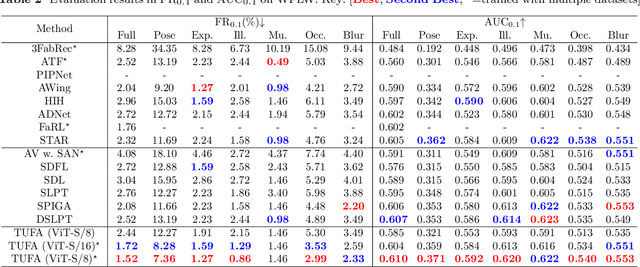
Despite the similar structures of human faces, existing face alignment methods cannot learn unified knowledge from multiple datasets with different landmark annotations. The limited training samples in a single dataset commonly result in fragile robustness in this field. To mitigate knowledge discrepancies among different datasets and train a task-agnostic unified face alignment (TUFA) framework, this paper presents a strategy to unify knowledge from multiple datasets. Specifically, we calculate a mean face shape for each dataset. To explicitly align these mean shapes on an interpretable plane based on their semantics, each shape is then incorporated with a group of semantic alignment embeddings. The 2D coordinates of these aligned shapes can be viewed as the anchors of the plane. By encoding them into structure prompts and further regressing the corresponding facial landmarks using image features, a mapping from the plane to the target faces is finally established, which unifies the learning target of different datasets. Consequently, multiple datasets can be utilized to boost the generalization ability of the model. The successful mitigation of discrepancies also enhances the efficiency of knowledge transferring to a novel dataset, significantly boosts the performance of few-shot face alignment. Additionally, the interpretable plane endows TUFA with a task-agnostic characteristic, enabling it to locate landmarks unseen during training in a zero-shot manner. Extensive experiments are carried on seven benchmarks and the results demonstrate an impressive improvement in face alignment brought by knowledge discrepancies mitigation.
Continual Learning for Segment Anything Model Adaptation
Dec 09, 2024Although the current different types of SAM adaptation methods have achieved promising performance for various downstream tasks, such as prompt-based ones and adapter-based ones, most of them belong to the one-step adaptation paradigm. In real-world scenarios, we are generally confronted with the dynamic scenario where the data comes in a streaming manner. Driven by the practical need, in this paper, we first propose a novel Continual SAM adaptation (CoSAM) benchmark with 8 different task domains and carefully analyze the limitations of the existing SAM one-step adaptation methods in the continual segmentation scenario. Then we propose a novel simple-yet-effective Mixture of Domain Adapters (MoDA) algorithm which utilizes the Global Feature Tokens (GFT) and Global Assistant Tokens (GAT) modules to help the SAM encoder extract well-separated features for different task domains, and then provide the accurate task-specific information for continual learning. Extensive experiments demonstrate that our proposed MoDA obviously surpasses the existing classic continual learning methods, as well as prompt-based and adapter-based approaches for continual segmentation. Moreover, after sequential learning on the CoSAM benchmark with diverse data distributions, our MoDA maintains highly competitive results in the natural image domain, approaching the zero-shot performance of the original SAM, demonstrating its superior capability in knowledge preservation. Notably, the proposed MoDA can be seamlessly integrated into various one-step adaptation methods of SAM, which can consistently bring obvious performance gains. Code is available at \url{https://github.com/yangjl1215/CoSAM}
Unsupervised Part Discovery via Dual Representation Alignment
Aug 15, 2024



Object parts serve as crucial intermediate representations in various downstream tasks, but part-level representation learning still has not received as much attention as other vision tasks. Previous research has established that Vision Transformer can learn instance-level attention without labels, extracting high-quality instance-level representations for boosting downstream tasks. In this paper, we achieve unsupervised part-specific attention learning using a novel paradigm and further employ the part representations to improve part discovery performance. Specifically, paired images are generated from the same image with different geometric transformations, and multiple part representations are extracted from these paired images using a novel module, named PartFormer. These part representations from the paired images are then exchanged to improve geometric transformation invariance. Subsequently, the part representations are aligned with the feature map extracted by a feature map encoder, achieving high similarity with the pixel representations of the corresponding part regions and low similarity in irrelevant regions. Finally, the geometric and semantic constraints are applied to the part representations through the intermediate results in alignment for part-specific attention learning, encouraging the PartFormer to focus locally and the part representations to explicitly include the information of the corresponding parts. Moreover, the aligned part representations can further serve as a series of reliable detectors in the testing phase, predicting pixel masks for part discovery. Extensive experiments are carried out on four widely used datasets, and our results demonstrate that the proposed method achieves competitive performance and robustness due to its part-specific attention.
Cross Contrasting Feature Perturbation for Domain Generalization
Aug 16, 2023Domain generalization (DG) aims to learn a robust model from source domains that generalize well on unseen target domains. Recent studies focus on generating novel domain samples or features to diversify distributions complementary to source domains. Yet, these approaches can hardly deal with the restriction that the samples synthesized from various domains can cause semantic distortion. In this paper, we propose an online one-stage Cross Contrasting Feature Perturbation (CCFP) framework to simulate domain shift by generating perturbed features in the latent space while regularizing the model prediction against domain shift. Different from the previous fixed synthesizing strategy, we design modules with learnable feature perturbations and semantic consistency constraints. In contrast to prior work, our method does not use any generative-based models or domain labels. We conduct extensive experiments on a standard DomainBed benchmark with a strict evaluation protocol for a fair comparison. Comprehensive experiments show that our method outperforms the previous state-of-the-art, and quantitative analyses illustrate that our approach can alleviate the domain shift problem in out-of-distribution (OOD) scenarios.
Strip-MLP: Efficient Token Interaction for Vision MLP
Jul 21, 2023



Token interaction operation is one of the core modules in MLP-based models to exchange and aggregate information between different spatial locations. However, the power of token interaction on the spatial dimension is highly dependent on the spatial resolution of the feature maps, which limits the model's expressive ability, especially in deep layers where the feature are down-sampled to a small spatial size. To address this issue, we present a novel method called \textbf{Strip-MLP} to enrich the token interaction power in three ways. Firstly, we introduce a new MLP paradigm called Strip MLP layer that allows the token to interact with other tokens in a cross-strip manner, enabling the tokens in a row (or column) to contribute to the information aggregations in adjacent but different strips of rows (or columns). Secondly, a \textbf{C}ascade \textbf{G}roup \textbf{S}trip \textbf{M}ixing \textbf{M}odule (CGSMM) is proposed to overcome the performance degradation caused by small spatial feature size. The module allows tokens to interact more effectively in the manners of within-patch and cross-patch, which is independent to the feature spatial size. Finally, based on the Strip MLP layer, we propose a novel \textbf{L}ocal \textbf{S}trip \textbf{M}ixing \textbf{M}odule (LSMM) to boost the token interaction power in the local region. Extensive experiments demonstrate that Strip-MLP significantly improves the performance of MLP-based models on small datasets and obtains comparable or even better results on ImageNet. In particular, Strip-MLP models achieve higher average Top-1 accuracy than existing MLP-based models by +2.44\% on Caltech-101 and +2.16\% on CIFAR-100. The source codes will be available at~\href{https://github.com/Med-Process/Strip_MLP{https://github.com/Med-Process/Strip\_MLP}.