 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning
Paper and Code
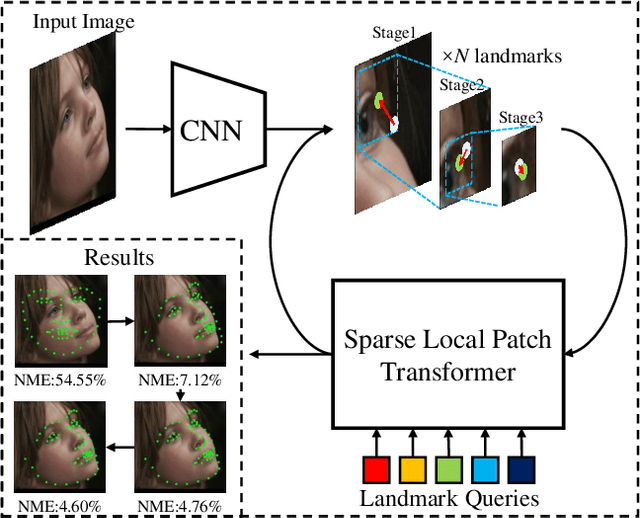
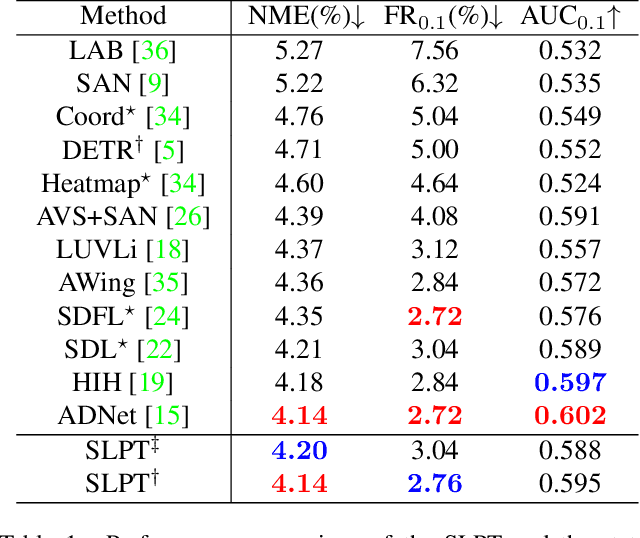

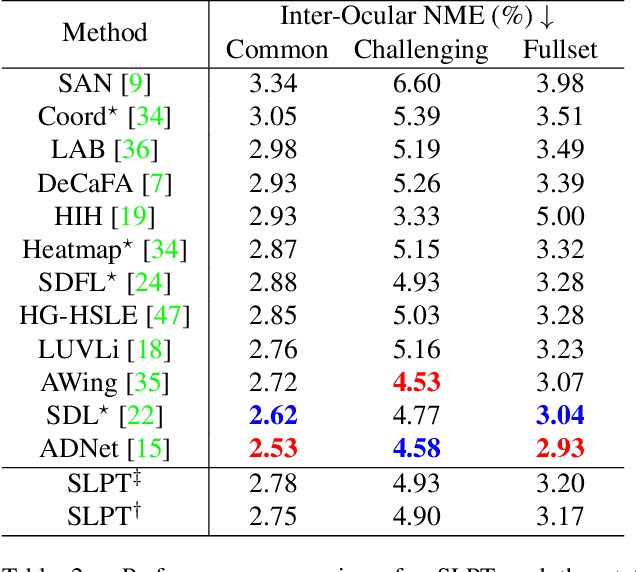
Heatmap regression methods have dominated face alignment area in recent years while they ignore the inherent relation between different landmarks. In this paper, we propose a Sparse Local Patch Transformer (SLPT) for learning the inherent relation. The SLPT generates the representation of each single landmark from a local patch and aggregates them by an adaptive inherent relation based on the attention mechanism. The subpixel coordinate of each landmark is predicted independently based on the aggregated feature. Moreover, a coarse-to-fine framework is further introduced to incorporate with the SLPT, which enables the initial landmarks to gradually converge to the target facial landmarks using fine-grained features from dynamically resized local patches. Extensive experiments carried out on three popular benchmarks, including WFLW, 300W and COFW, demonstrate that the proposed method works at the state-of-the-art level with much less computational complexity by learning the inherent relation between facial landmarks. The code is available at the project website.