 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEv-Trust: A Strategy Equilibrium Trust Mechanism for Evolutionary Games in LLM-Based Multi-Agent Services
Dec 18, 2025The rapid evolution of the Web toward an agent-centric paradigm, driven by large language models (LLMs), has enabled autonomous agents to reason, plan, and interact in complex decentralized environments. However, the openness and heterogeneity of LLM-based multi-agent systems also amplify the risks of deception, fraud, and misinformation, posing severe challenges to trust establishment and system robustness. To address this issue, we propose Ev-Trust, a strategy-equilibrium trust mechanism grounded in evolutionary game theory. This mechanism integrates direct trust, indirect trust, and expected revenue into a dynamic feedback structure that guides agents' behavioral evolution toward equilibria. Within a decentralized "Request-Response-Payment-Evaluation" service framework, Ev-Trust enables agents to adaptively adjust strategies, naturally excluding malicious participants while reinforcing high-quality collaboration. Furthermore, our theoretical derivation based on replicator dynamics equations proves the existence and stability of local evolutionary equilibria. Experimental results indicate that our approach effectively reflects agent trustworthiness in LLM-driven open service interaction scenarios, reduces malicious strategies, and increases collective revenue. We hope Ev-Trust can provide a new perspective on trust modeling for the agentic service web in group evolutionary game scenarios.
SSCL-BW: Sample-Specific Clean-Label Backdoor Watermarking for Dataset Ownership Verification
Oct 30, 2025The rapid advancement of deep neural networks (DNNs) heavily relies on large-scale, high-quality datasets. However, unauthorized commercial use of these datasets severely violates the intellectual property rights of dataset owners. Existing backdoor-based dataset ownership verification methods suffer from inherent limitations: poison-label watermarks are easily detectable due to label inconsistencies, while clean-label watermarks face high technical complexity and failure on high-resolution images. Moreover, both approaches employ static watermark patterns that are vulnerable to detection and removal. To address these issues, this paper proposes a sample-specific clean-label backdoor watermarking (i.e., SSCL-BW). By training a U-Net-based watermarked sample generator, this method generates unique watermarks for each sample, fundamentally overcoming the vulnerability of static watermark patterns. The core innovation lies in designing a composite loss function with three components: target sample loss ensures watermark effectiveness, non-target sample loss guarantees trigger reliability, and perceptual similarity loss maintains visual imperceptibility. During ownership verification, black-box testing is employed to check whether suspicious models exhibit predefined backdoor behaviors. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed method and its robustness against potential watermark removal attacks.
CertDW: Towards Certified Dataset Ownership Verification via Conformal Prediction
Jun 16, 2025



Deep neural networks (DNNs) rely heavily on high-quality open-source datasets (e.g., ImageNet) for their success, making dataset ownership verification (DOV) crucial for protecting public dataset copyrights. In this paper, we find existing DOV methods (implicitly) assume that the verification process is faithful, where the suspicious model will directly verify ownership by using the verification samples as input and returning their results. However, this assumption may not necessarily hold in practice and their performance may degrade sharply when subjected to intentional or unintentional perturbations. To address this limitation, we propose the first certified dataset watermark (i.e., CertDW) and CertDW-based certified dataset ownership verification method that ensures reliable verification even under malicious attacks, under certain conditions (e.g., constrained pixel-level perturbation). Specifically, inspired by conformal prediction, we introduce two statistical measures, including principal probability (PP) and watermark robustness (WR), to assess model prediction stability on benign and watermarked samples under noise perturbations. We prove there exists a provable lower bound between PP and WR, enabling ownership verification when a suspicious model's WR value significantly exceeds the PP values of multiple benign models trained on watermark-free datasets. If the number of PP values smaller than WR exceeds a threshold, the suspicious model is regarded as having been trained on the protected dataset. Extensive experiments on benchmark datasets verify the effectiveness of our CertDW method and its resistance to potential adaptive attacks. Our codes are at \href{https://github.com/NcepuQiaoTing/CertDW}{GitHub}.
SE-GCL: An Event-Based Simple and Effective Graph Contrastive Learning for Text Representation
Dec 16, 2024



Text representation learning is significant as the cornerstone of natural language processing. In recent years, graph contrastive learning (GCL) has been widely used in text representation learning due to its ability to represent and capture complex text information in a self-supervised setting. However, current mainstream graph contrastive learning methods often require the incorporation of domain knowledge or cumbersome computations to guide the data augmentation process, which significantly limits the application efficiency and scope of GCL. Additionally, many methods learn text representations only by constructing word-document relationships, which overlooks the rich contextual semantic information in the text. To address these issues and exploit representative textual semantics, we present an event-based, simple, and effective graph contrastive learning (SE-GCL) for text representation. Precisely, we extract event blocks from text and construct internal relation graphs to represent inter-semantic interconnections, which can ensure that the most critical semantic information is preserved. Then, we devise a streamlined, unsupervised graph contrastive learning framework to leverage the complementary nature of the event semantic and structural information for intricate feature data capture. In particular, we introduce the concept of an event skeleton for core representation semantics and simplify the typically complex data augmentation techniques found in existing graph contrastive learning to boost algorithmic efficiency. We employ multiple loss functions to prompt diverse embeddings to converge or diverge within a confined distance in the vector space, ultimately achieving a harmonious equilibrium. We conducted experiments on the proposed SE-GCL on four standard data sets (AG News, 20NG, SougouNews, and THUCNews) to verify its effectiveness in text representation learning.
Contrastive Multi-graph Learning with Neighbor Hierarchical Sifting for Semi-supervised Text Classification
Nov 25, 2024
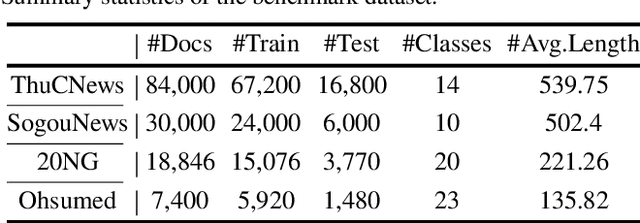
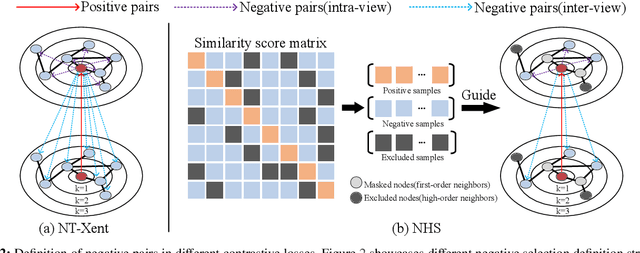
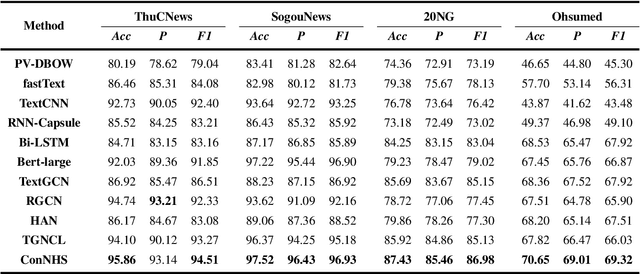
Graph contrastive learning has been successfully applied in text classification due to its remarkable ability for self-supervised node representation learning. However, explicit graph augmentations may lead to a loss of semantics in the contrastive views. Secondly, existing methods tend to overlook edge features and the varying significance of node features during multi-graph learning. Moreover, the contrastive loss suffer from false negatives. To address these limitations, we propose a novel method of contrastive multi-graph learning with neighbor hierarchical sifting for semi-supervised text classification, namely ConNHS. Specifically, we exploit core features to form a multi-relational text graph, enhancing semantic connections among texts. By separating text graphs, we provide diverse views for contrastive learning. Our approach ensures optimal preservation of the graph information, minimizing data loss and distortion. Then, we separately execute relation-aware propagation and cross-graph attention propagation, which effectively leverages the varying correlations between nodes and edge features while harmonising the information fusion across graphs. Subsequently, we present the neighbor hierarchical sifting loss (NHS) to refine the negative selection. For one thing, following the homophily assumption, NHS masks first-order neighbors of the anchor and positives from being negatives. For another, NHS excludes the high-order neighbors analogous to the anchor based on their similarities. Consequently, it effectively reduces the occurrence of false negatives, preventing the expansion of the distance between similar samples in the embedding space. Our experiments on ThuCNews, SogouNews, 20 Newsgroups, and Ohsumed datasets achieved 95.86\%, 97.52\%, 87.43\%, and 70.65\%, which demonstrates competitive results in semi-supervised text classification.
SEG:Seeds-Enhanced Iterative Refinement Graph Neural Network for Entity Alignment
Oct 28, 2024



Entity alignment is crucial for merging knowledge across knowledge graphs, as it matches entities with identical semantics. The standard method matches these entities based on their embedding similarities using semi-supervised learning. However, diverse data sources lead to non-isomorphic neighborhood structures for aligned entities, complicating alignment, especially for less common and sparsely connected entities. This paper presents a soft label propagation framework that integrates multi-source data and iterative seed enhancement, addressing scalability challenges in handling extensive datasets where scale computing excels. The framework uses seeds for anchoring and selects optimal relationship pairs to create soft labels rich in neighborhood features and semantic relationship data. A bidirectional weighted joint loss function is implemented, which reduces the distance between positive samples and differentially processes negative samples, taking into account the non-isomorphic neighborhood structures. Our method outperforms existing semi-supervised approaches, as evidenced by superior results on multiple datasets, significantly improving the quality of entity alignment.
Graph Contrastive Learning via Cluster-refined Negative Sampling for Semi-supervised Text Classification
Oct 18, 2024

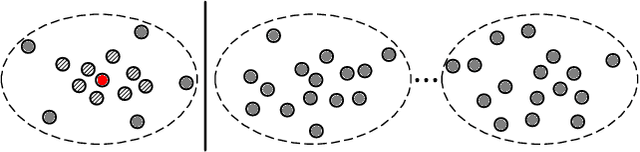

Graph contrastive learning (GCL) has been widely applied to text classification tasks due to its ability to generate self-supervised signals from unlabeled data, thus facilitating model training. However, existing GCL-based text classification methods often suffer from negative sampling bias, where similar nodes are incorrectly paired as negative pairs. This can lead to over-clustering, where instances of the same class are divided into different clusters. To address the over-clustering issue, we propose an innovative GCL-based method of graph contrastive learning via cluster-refined negative sampling for semi-supervised text classification, namely ClusterText. Firstly, we combine the pre-trained model Bert with graph neural networks to learn text representations. Secondly, we introduce a clustering refinement strategy, which clusters the learned text representations to obtain pseudo labels. For each text node, its negative sample set is drawn from different clusters. Additionally, we propose a self-correction mechanism to mitigate the loss of true negative samples caused by clustering inconsistency. By calculating the Euclidean distance between each text node and other nodes within the same cluster, distant nodes are still selected as negative samples. Our proposed ClusterText demonstrates good scalable computing, as it can effectively extract important information from from a large amount of data. Experimental results demonstrate the superiority of ClusterText in text classification tasks.