 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT is Not the Chain of Truth: An Empirical Internal Analysis of Reasoning LLMs for Fake News Generation
Feb 05, 2026From generating headlines to fabricating news, the Large Language Models (LLMs) are typically assessed by their final outputs, under the safety assumption that a refusal response signifies safe reasoning throughout the entire process. Challenging this assumption, our study reveals that during fake news generation, even when a model rejects a harmful request, its Chain-of-Thought (CoT) reasoning may still internally contain and propagate unsafe narratives. To analyze this phenomenon, we introduce a unified safety-analysis framework that systematically deconstructs CoT generation across model layers and evaluates the role of individual attention heads through Jacobian-based spectral metrics. Within this framework, we introduce three interpretable measures: stability, geometry, and energy to quantify how specific attention heads respond or embed deceptive reasoning patterns. Extensive experiments on multiple reasoning-oriented LLMs show that the generation risk rise significantly when the thinking mode is activated, where the critical routing decisions concentrated in only a few contiguous mid-depth layers. By precisely identifying the attention heads responsible for this divergence, our work challenges the assumption that refusal implies safety and provides a new understanding perspective for mitigating latent reasoning risks.
LRA-GNN: Latent Relation-Aware Graph Neural Network with Initial and Dynamic Residual for Facial Age Estimation
Feb 08, 2025Face information is mainly concentrated among facial key points, and frontier research has begun to use graph neural networks to segment faces into patches as nodes to model complex face representations. However, these methods construct node-to-node relations based on similarity thresholds, so there is a problem that some latent relations are missing. These latent relations are crucial for deep semantic representation of face aging. In this novel, we propose a new Latent Relation-Aware Graph Neural Network with Initial and Dynamic Residual (LRA-GNN) to achieve robust and comprehensive facial representation. Specifically, we first construct an initial graph utilizing facial key points as prior knowledge, and then a random walk strategy is employed to the initial graph for obtaining the global structure, both of which together guide the subsequent effective exploration and comprehensive representation. Then LRA-GNN leverages the multi-attention mechanism to capture the latent relations and generates a set of fully connected graphs containing rich facial information and complete structure based on the aforementioned guidance. To avoid over-smoothing issues for deep feature extraction on the fully connected graphs, the deep residual graph convolutional networks are carefully designed, which fuse adaptive initial residuals and dynamic developmental residuals to ensure the consistency and diversity of information. Finally, to improve the estimation accuracy and generalization ability, progressive reinforcement learning is proposed to optimize the ensemble classification regressor. Our proposed framework surpasses the state-of-the-art baselines on several age estimation benchmarks, demonstrating its strength and effectiveness.
GroupFace: Imbalanced Age Estimation Based on Multi-hop Attention Graph Convolutional Network and Group-aware Margin Optimization
Dec 16, 2024

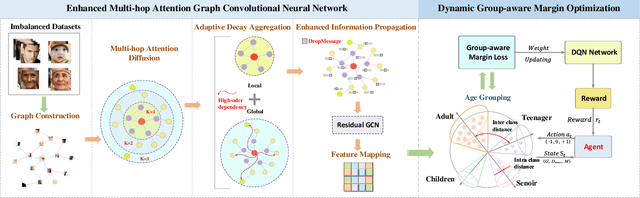
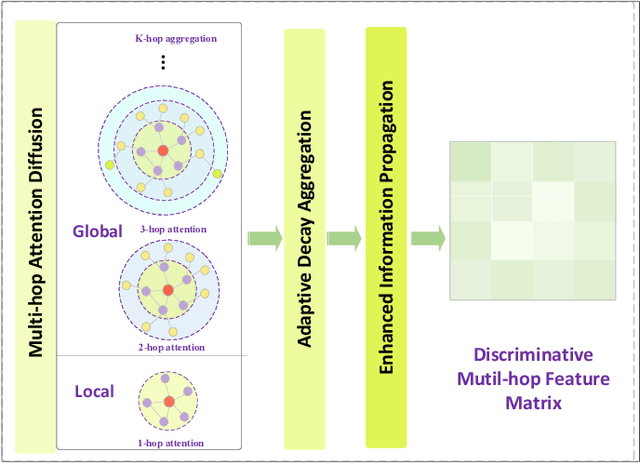
With the recent advances in computer vision, age estimation has significantly improved in overall accuracy. However, owing to the most common methods do not take into account the class imbalance problem in age estimation datasets, they suffer from a large bias in recognizing long-tailed groups. To achieve high-quality imbalanced learning in long-tailed groups, the dominant solution lies in that the feature extractor learns the discriminative features of different groups and the classifier is able to provide appropriate and unbiased margins for different groups by the discriminative features. Therefore, in this novel, we propose an innovative collaborative learning framework (GroupFace) that integrates a multi-hop attention graph convolutional network and a dynamic group-aware margin strategy based on reinforcement learning. Specifically, to extract the discriminative features of different groups, we design an enhanced multi-hop attention graph convolutional network. This network is capable of capturing the interactions of neighboring nodes at different distances, fusing local and global information to model facial deep aging, and exploring diverse representations of different groups. In addition, to further address the class imbalance problem, we design a dynamic group-aware margin strategy based on reinforcement learning to provide appropriate and unbiased margins for different groups. The strategy divides the sample into four age groups and considers identifying the optimum margins for various age groups by employing a Markov decision process. Under the guidance of the agent, the feature representation bias and the classification margin deviation between different groups can be reduced simultaneously, balancing inter-class separability and intra-class proximity. After joint optimization, our architecture achieves excellent performance on several age estimation benchmark datasets.
A Multi-view Mask Contrastive Learning Graph Convolutional Neural Network for Age Estimation
Jul 23, 2024The age estimation task aims to use facial features to predict the age of people and is widely used in public security, marketing, identification, and other fields. However, the features are mainly concentrated in facial keypoints, and existing CNN and Transformer-based methods have inflexibility and redundancy for modeling complex irregular structures. Therefore, this paper proposes a Multi-view Mask Contrastive Learning Graph Convolutional Neural Network (MMCL-GCN) for age estimation. Specifically, the overall structure of the MMCL-GCN network contains a feature extraction stage and an age estimation stage. In the feature extraction stage, we introduce a graph structure to construct face images as input and then design a Multi-view Mask Contrastive Learning (MMCL) mechanism to learn complex structural and semantic information about face images. The learning mechanism employs an asymmetric siamese network architecture, which utilizes an online encoder-decoder structure to reconstruct the missing information from the original graph and utilizes the target encoder to learn latent representations for contrastive learning. Furthermore, to promote the two learning mechanisms better compatible and complementary, we adopt two augmentation strategies and optimize the joint losses. In the age estimation stage, we design a Multi-layer Extreme Learning Machine (ML-IELM) with identity mapping to fully use the features extracted by the online encoder. Then, a classifier and a regressor were constructed based on ML-IELM, which were used to identify the age grouping interval and accurately estimate the final age. Extensive experiments show that MMCL-GCN can effectively reduce the error of age estimation on benchmark datasets such as Adience, MORPH-II, and LAP-2016.
A Boosting Method to Face Image Super-resolution
May 04, 2018

Recently sparse representation has gained great success in face image super-resolution. The conventional sparsity-based methods enforce sparse coding on face image patches and the representation fidelity is measured by $\ell_{2}$-norm. Such a sparse coding model regularizes all facial patches equally, which however ignores distinct natures of different facial patches for image reconstruction. In this paper, we propose a new weighted-patch super-resolution method based on AdaBoost. Specifically, in each iteration of the AdaBoost operation, each facial patch is weighted automatically according to the performance of the model on it, so as to highlight those patches that are more critical for improving the reconstruction power in next step. In this way, through the AdaBoost training procedure, we can focus more on the patches (face regions) with richer information. Various experimental results on standard face database show that our proposed method outperforms state-of-the-art methods in terms of both objective metrics and visual quality.