 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tree-structure Convolutional Neural Network for Temporal Features Exaction on Sensor-based Multi-resident Activity Recognition
Nov 05, 2020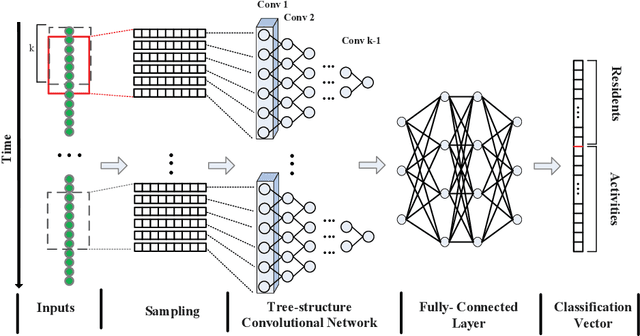

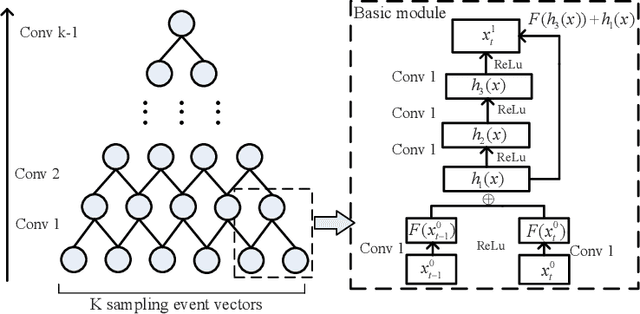

With the propagation of sensor devices applied in smart home, activity recognition has ignited huge interest and most existing works assume that there is only one habitant. While in reality, there are generally multiple residents at home, which brings greater challenge to recognize activities. In addition, many conventional approaches rely on manual time series data segmentation ignoring the inherent characteristics of events and their heuristic hand-crafted feature generation algorithms are difficult to exploit distinctive features to accurately classify different activities. To address these issues, we propose an end-to-end Tree-Structure Convolutional neural network based framework for Multi-Resident Activity Recognition (TSC-MRAR). First, we treat each sample as an event and obtain the current event embedding through the previous sensor readings in the sliding window without splitting the time series data. Then, in order to automatically generate the temporal features, a tree-structure network is designed to derive the temporal dependence of nearby readings. The extracted features are fed into the fully connected layer, which can jointly learn the residents labels and the activity labels simultaneously. Finally, experiments on CASAS datasets demonstrate the high performance in multi-resident activity recognition of our model compared to state-of-the-art techniques.
* 12 pages, 4 figures
A Boosting Method to Face Image Super-resolution
May 04, 2018

Recently sparse representation has gained great success in face image super-resolution. The conventional sparsity-based methods enforce sparse coding on face image patches and the representation fidelity is measured by $\ell_{2}$-norm. Such a sparse coding model regularizes all facial patches equally, which however ignores distinct natures of different facial patches for image reconstruction. In this paper, we propose a new weighted-patch super-resolution method based on AdaBoost. Specifically, in each iteration of the AdaBoost operation, each facial patch is weighted automatically according to the performance of the model on it, so as to highlight those patches that are more critical for improving the reconstruction power in next step. In this way, through the AdaBoost training procedure, we can focus more on the patches (face regions) with richer information. Various experimental results on standard face database show that our proposed method outperforms state-of-the-art methods in terms of both objective metrics and visual quality.