 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACING: Actor-Critic for Instruction Learning in Black-Box Large Language Models
Paper and Code
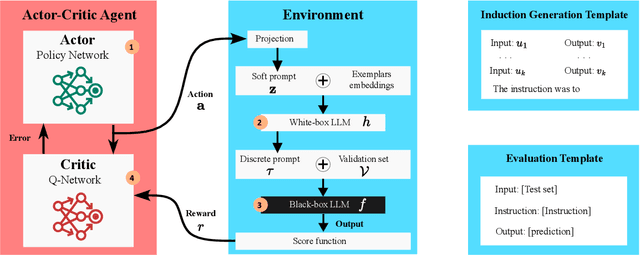

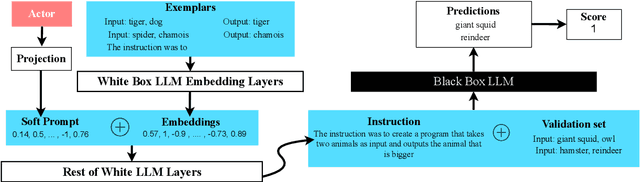
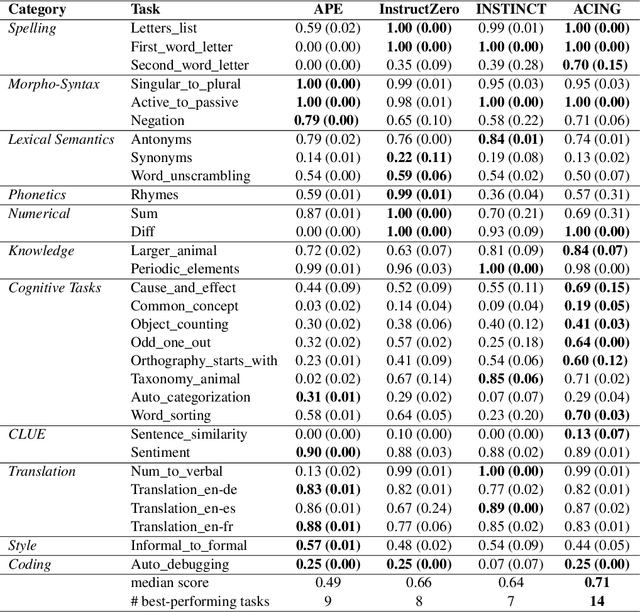
The effectiveness of Large Language Models (LLMs) in solving tasks vastly depends on the quality of the instructions, which often require fine-tuning through extensive human effort. This highlights the need for automated instruction optimization; however, this optimization is particularly challenging when dealing with black-box LLMs, where model parameters and gradients remain inaccessible. We propose ACING, a task-specific prompt optimization approach framed as a stateless continuous-action Reinforcement Learning (RL) problem, known as the continuum bandit setting. ACING leverages an actor-critic-based method to optimize prompts, learning from non-differentiable reward signals. We validate ACING by optimizing prompts for ChatGPT on 30 instruction-based tasks. ACING consistently outperforms baseline methods, achieving a median score improvement of 10 percentage points. Furthermore, ACING not only recovers but also surpasses human-crafted expert instructions, achieving up to a 39 percentage point improvement against human benchmarks.