 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWFR-FM: Simulation-Free Dynamic Unbalanced Optimal Transport
Jan 11, 2026The Wasserstein-Fisher-Rao (WFR) metric extends dynamic optimal transport (OT) by coupling displacement with change of mass, providing a principled geometry for modeling unbalanced snapshot dynamics. Existing WFR solvers, however, are often unstable, computationally expensive, and difficult to scale. Here we introduce WFR Flow Matching (WFR-FM), a simulation-free training algorithm that unifies flow matching with dynamic unbalanced OT. Unlike classical flow matching which regresses only a transport vector field, WFR-FM simultaneously regresses a vector field for displacement and a scalar growth rate function for birth-death dynamics, yielding continuous flows under the WFR geometry. Theoretically, we show that minimizing the WFR-FM loss exactly recovers WFR geodesics. Empirically, WFR-FM yields more accurate and robust trajectory inference in single-cell biology, reconstructing consistent dynamics with proliferation and apoptosis, estimating time-varying growth fields, and applying to generative dynamics under imbalanced data. It outperforms state-of-the-art baselines in efficiency, stability, and reconstruction accuracy. Overall, WFR-FM establishes a unified and efficient paradigm for learning dynamical systems from unbalanced snapshots, where not only states but also mass evolve over time.
Optimal Transport for Latent Integration with An Application to Heterogeneous Neuronal Activity Data
Jun 27, 2024



Detecting dynamic patterns of task-specific responses shared across heterogeneous datasets is an essential and challenging problem in many scientific applications in medical science and neuroscience. In our motivating example of rodent electrophysiological data, identifying the dynamical patterns in neuronal activity associated with ongoing cognitive demands and behavior is key to uncovering the neural mechanisms of memory. One of the greatest challenges in investigating a cross-subject biological process is that the systematic heterogeneity across individuals could significantly undermine the power of existing machine learning methods to identify the underlying biological dynamics. In addition, many technically challenging neurobiological experiments are conducted on only a handful of subjects where rich longitudinal data are available for each subject. The low sample sizes of such experiments could further reduce the power to detect common dynamic patterns among subjects. In this paper, we propose a novel heterogeneous data integration framework based on optimal transport to extract shared patterns in complex biological processes. The key advantages of the proposed method are that it can increase discriminating power in identifying common patterns by reducing heterogeneity unrelated to the signal by aligning the extracted latent spatiotemporal information across subjects. Our approach is effective even with a small number of subjects, and does not require auxiliary matching information for the alignment. In particular, our method can align longitudinal data across heterogeneous subjects in a common latent space to capture the dynamics of shared patterns while utilizing temporal dependency within subjects.
AVIDA: Alternating method for Visualizing and Integrating Data
May 31, 2022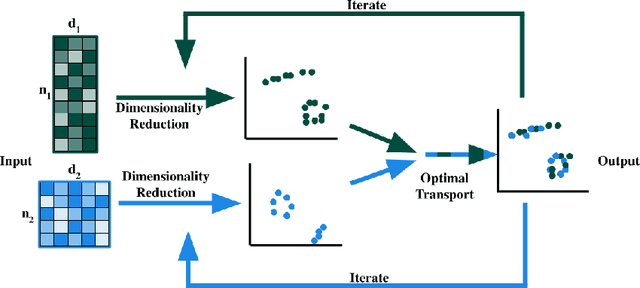
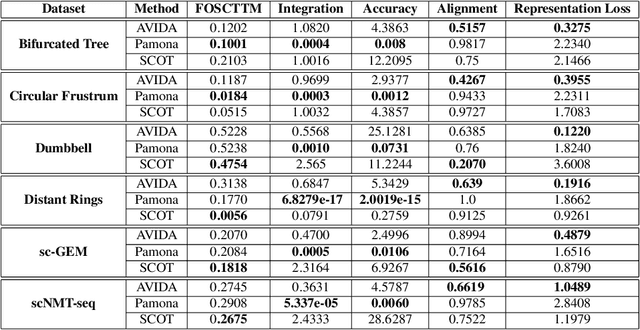
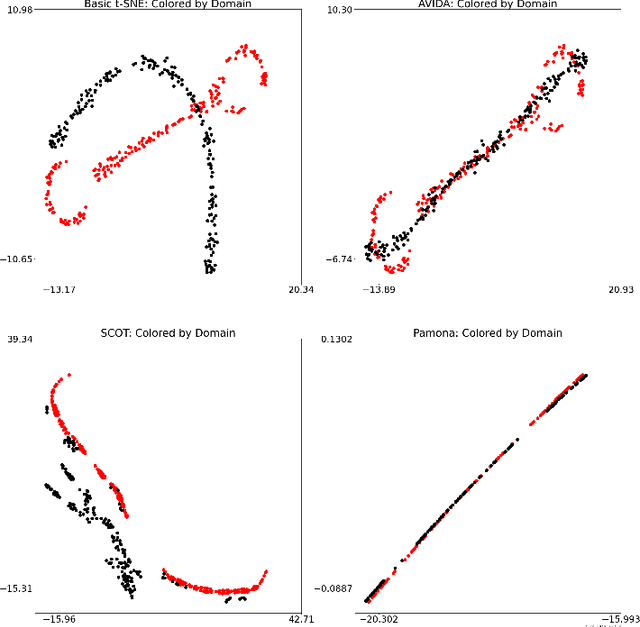
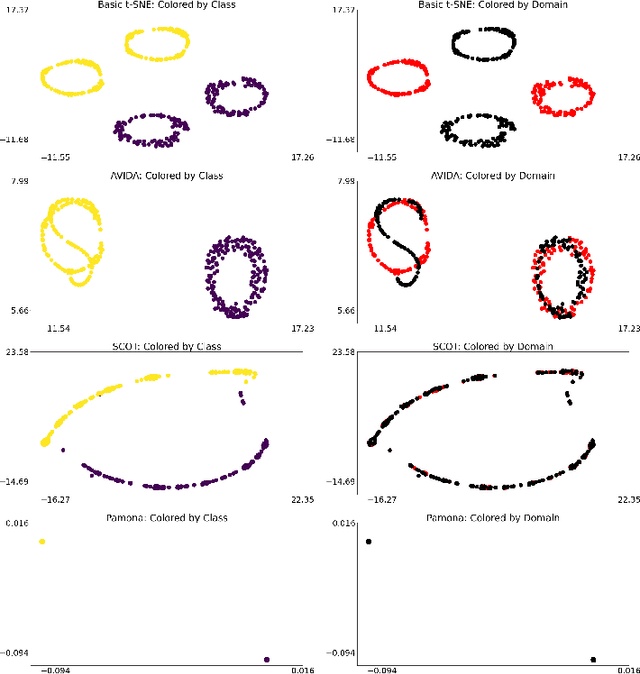
High-dimensional multimodal data arises in many scientific fields. The integration of multimodal data becomes challenging when there is no known correspondence between the samples and the features of different datasets. To tackle this challenge, we introduce AVIDA, a framework for simultaneously performing data alignment and dimension reduction. In the numerical experiments, Gromov-Wasserstein optimal transport and t-distributed stochastic neighbor embedding are used as the alignment and dimension reduction modules respectively. We show that AVIDA correctly aligns high-dimensional datasets without common features with four synthesized datasets and two real multimodal single-cell datasets. Compared to several existing methods, we demonstrate that AVIDA better preserves structures of individual datasets, especially distinct local structures in the joint low-dimensional visualization, while achieving comparable alignment performance. Such a property is important in multimodal single-cell data analysis as some biological processes are uniquely captured by one of the datasets. In general applications, other methods can be used for the alignment and dimension reduction modules.