 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Transport for Latent Integration with An Application to Heterogeneous Neuronal Activity Data
Jun 27, 2024



Detecting dynamic patterns of task-specific responses shared across heterogeneous datasets is an essential and challenging problem in many scientific applications in medical science and neuroscience. In our motivating example of rodent electrophysiological data, identifying the dynamical patterns in neuronal activity associated with ongoing cognitive demands and behavior is key to uncovering the neural mechanisms of memory. One of the greatest challenges in investigating a cross-subject biological process is that the systematic heterogeneity across individuals could significantly undermine the power of existing machine learning methods to identify the underlying biological dynamics. In addition, many technically challenging neurobiological experiments are conducted on only a handful of subjects where rich longitudinal data are available for each subject. The low sample sizes of such experiments could further reduce the power to detect common dynamic patterns among subjects. In this paper, we propose a novel heterogeneous data integration framework based on optimal transport to extract shared patterns in complex biological processes. The key advantages of the proposed method are that it can increase discriminating power in identifying common patterns by reducing heterogeneity unrelated to the signal by aligning the extracted latent spatiotemporal information across subjects. Our approach is effective even with a small number of subjects, and does not require auxiliary matching information for the alignment. In particular, our method can align longitudinal data across heterogeneous subjects in a common latent space to capture the dynamics of shared patterns while utilizing temporal dependency within subjects.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021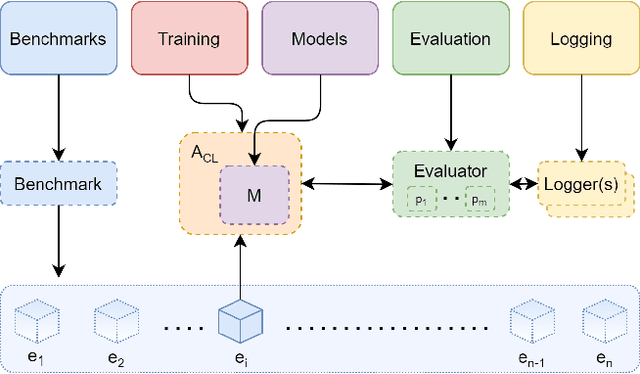

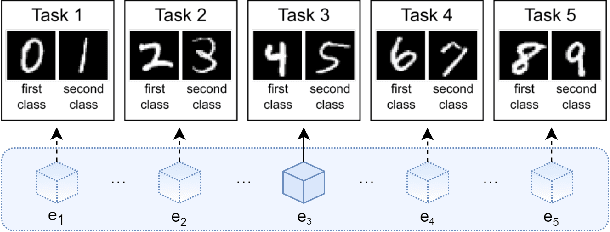

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.