 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Signatures of Large Language Models
Jul 03, 2026The rapidly growing repository of publicly available large language models (LLMs) presents significant challenges for systematic management and quantification at scale, such as model lineage tracing, licensing, and evaluation. However, task-specific benchmarks are insufficient for this setting, as LLMs differ widely in architectures, scales, and training procedures. To address this challenge, we adopt spectral shape-based metrics for managing and quantifying LLMs based on Heavy-Tailed Self-Regularization theory. Our approach uses the shape information of the weight empirical spectral density as a compact spectral signature of each model. This signature captures intrinsic properties of pretrained models and remains robust during post-training, making it suitable for model-level analysis. In addition, this metric is data-free, computationally-efficient, and scale-invariant, enabling large-scale analysis in practice. Moreover, we curate a large and diverse model corpus consisting of major open-source LLM families, and use it to systematically benchmark spectral and non-spectral metrics across models and downstream tasks. We show that our spectral signature supports the tracking of the model lineage, the unsupervised clustering of similar models, and the quantification of the model performance. Overall, the proposed spectral signature provides a meaningful proxy for broad performance trends across LLMs, enabling efficient organization, comparison, and analysis of large model collections.
Shrinkage priors for Bayesian Substitute Confounders
Jun 16, 2026Multi-cause observational studies contain information about unmeasured confounding through the dependence structure among causes. However, literal imputation of the unobserved confounder is often more complex than learning a lower-dimensional substitute score that preserves the shared assignment variation needed for stable causal adjustment. The deconfounder (Wang and Blei, 2019) and related substitute confounder methods exploit this idea, but flexible assignment models can fit the joint distribution of the causes while producing scores that over-encode the treatment vector, collapse overlap, or capture single-cause variation. We develop a Bayesian factor assignment framework for learning sparse substitute confounders that retain coarse multi-cause dependence with shrinkage priors. The theory is stated at the level of posterior concentration, factor score contraction, and overlap-preserving assignment geometry and therefore does not rely on a particular shrinkage prior. Under these conditions, the proposed regression-adjusted estimators are consistent for mean potential outcomes when the corresponding latent variable identification assumptions hold. Shrinkage priors provide a natural tool for latent structural learning: they favour low-dimensional factors supported by multiple causes, discourage effectively single-cause factors, and induce an ordering of the latent factors through progressive shrinkage. Synthetic experiments illustrate the roles of signal strength, outcome validity, and geometry-aware regularization. In an Alzheimer's Disease Neuroimaging Initiative (ADNI) baseline analysis, sparse substitute scores recover much of the adjustment obtained by directly conditioning on invasive cerebrospinal-fluid biomarkers, while collapse diagnostics identify when fitted factors reduce to individual observed measurements.
Asymptotic Optimism for Tensor Regression Models with Applications to Neural Network Compression
Mar 27, 2026We study rank selection for low-rank tensor regression under random covariates design. Under a Gaussian random-design model and some mild conditions, we derive population expressions for the expected training-testing discrepancy (optimism) for both CP and Tucker decomposition. We further demonstrate that the optimism is minimized at the true tensor rank for both CP and Tucker regression. This yields a prediction-oriented rank-selection rule that aligns with cross-validation and extends naturally to tensor-model averaging. We also discuss conditions under which under- or over-ranked models may appear preferable, thereby clarifying the scope of the method. Finally, we showcase its practical utility on a real-world image regression task and extend its application to tensor-based compression of neural network, highlighting its potential for model selection in deep learning.
Wasserstein-type Gaussian Process Regressions for Input Measurement Uncertainty
Mar 18, 2026Gaussian process (GP) regression is widely used for uncertainty quantification, yet the standard formulation assumes noise-free covariates. When inputs are measured with error, this errors-in-variables (EIV) setting can lead to optimistically narrow posterior intervals and biased decisions. We study GP regression under input measurement uncertainty by representing each noisy input as a probability measure and defining covariance through Wasserstein distances between these measures. Building on this perspective, we instantiate a deterministic projected Wasserstein ARD (PWA) kernel whose one-dimensional components admit closed-form expressions and whose product structure yields a scalable, positive-definite kernel on distributions. Unlike latent-input GP models, PWA-based GPs (\PWAGPs) handle input noise without introducing unobserved covariates or Monte Carlo projections, making uncertainty quantification more transparent and robust.
GGMPs: Generalized Gaussian Mixture Processes
Mar 11, 2026Conditional density estimation is complicated by multimodality, heteroscedasticity, and strong non-Gaussianity. Gaussian processes (GPs) provide a principled nonparametric framework with calibrated uncertainty, but standard GP regression is limited by its unimodal Gaussian predictive form. We introduce the Generalized Gaussian Mixture Process (GGMP), a GP-based method for multimodal conditional density estimation in settings where each input may be associated with a complex output distribution rather than a single scalar response. GGMP combines local Gaussian mixture fitting, cross-input component alignment and per-component heteroscedastic GP training to produce a closed-form Gaussian mixture predictive density. The method is tractable, compatible with standard GP solvers and scalable methods, and avoids the exponentially large latent-assignment structure of naive multimodal GP formulations. Empirically, GGMPs improve distributional approximation on synthetic and real-world datasets with pronounced non-Gaussianity and multimodality.
Wedge Sampling: Efficient Tensor Completion with Nearly-Linear Sample Complexity
Feb 05, 2026We introduce Wedge Sampling, a new non-adaptive sampling scheme for low-rank tensor completion. We study recovery of an order-$k$ low-rank tensor of dimension $n \times \cdots \times n$ from a subset of its entries. Unlike the standard uniform entry model (i.e., i.i.d. samples from $[n]^k$), wedge sampling allocates observations to structured length-two patterns (wedges) in an associated bipartite sampling graph. By directly promoting these length-two connections, the sampling design strengthens the spectral signal that underlies efficient initialization, in regimes where uniform sampling is too sparse to generate enough informative correlations. Our main result shows that this change in sampling paradigm enables polynomial-time algorithms to achieve both weak and exact recovery with nearly linear sample complexity in $n$. The approach is also plug-and-play: wedge-sampling-based spectral initialization can be combined with existing refinement procedures (e.g., spectral or gradient-based methods) using only an additional $\tilde{O}(n)$ uniformly sampled entries, substantially improving over the $\tilde{O}(n^{k/2})$ sample complexity typically required under uniform entry sampling for efficient methods. Overall, our results suggest that the statistical-to-computational gap highlighted in Barak and Moitra (2022) is, to a large extent, a consequence of the uniform entry sampling model for tensor completion, and that alternative non-adaptive measurement designs that guarantee a strong initialization can overcome this barrier.
Robust Bayesian Optimization via Tempered Posteriors
Jan 11, 2026Bayesian optimization (BO) iteratively fits a Gaussian process (GP) surrogate to accumulated evaluations and selects new queries via an acquisition function such as expected improvement (EI). In practice, BO often concentrates evaluations near the current incumbent, causing the surrogate to become overconfident and to understate predictive uncertainty in the region guiding subsequent decisions. We develop a robust GP-based BO via tempered posterior updates, which downweight the likelihood by a power $α\in (0,1]$ to mitigate overconfidence under local misspecification. We establish cumulative regret bounds for tempered BO under a family of generalized improvement rules, including EI, and show that tempering yields strictly sharper worst-case regret guarantees than the standard posterior $(α=1)$, with the most favorable guarantees occurring near the classical EI choice. Motivated by our theoretic findings, we propose a prequential procedure for selecting $α$ online: it decreases $α$ when realized prediction errors exceed model-implied uncertainty and returns $α$ toward one as calibration improves. Empirical results demonstrate that tempering provides a practical yet theoretically grounded tool for stabilizing BO surrogates under localized sampling.
EnQode: Fast Amplitude Embedding for Quantum Machine Learning Using Classical Data
Mar 18, 2025Amplitude embedding (AE) is essential in quantum machine learning (QML) for encoding classical data onto quantum circuits. However, conventional AE methods suffer from deep, variable-length circuits that introduce high output error due to extensive gate usage and variable error rates across samples, resulting in noise-driven inconsistencies that degrade model accuracy. We introduce EnQode, a fast AE technique based on symbolic representation that addresses these limitations by clustering dataset samples and solving for cluster mean states through a low-depth, machine-specific ansatz. Optimized to reduce physical gates and SWAP operations, EnQode ensures all samples face consistent, low noise levels by standardizing circuit depth and composition. With over 90% fidelity in data mapping, EnQode enables robust, high-performance QML on noisy intermediate-scale quantum (NISQ) devices. Our open-source solution provides a scalable and efficient alternative for integrating classical data with quantum models.
Kernel-based estimators for functional causal effects
Mar 06, 2025
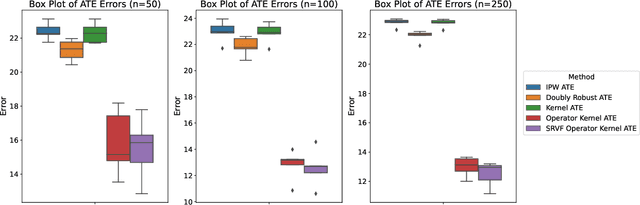
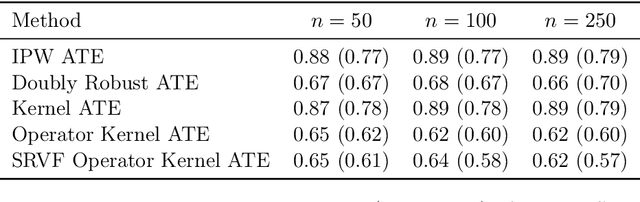
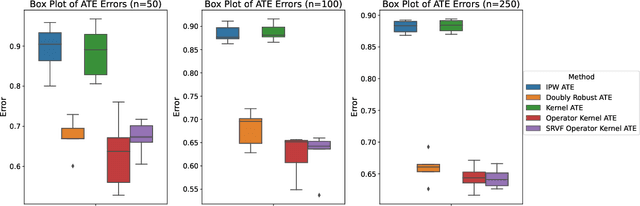
We propose causal effect estimators based on empirical Fr\'{e}chet means and operator-valued kernels, tailored to functional data spaces. These methods address the challenges of high-dimensionality, sequential ordering, and model complexity while preserving robustness to treatment misspecification. Using structural assumptions, we obtain compact representations of potential outcomes, enabling scalable estimation of causal effects over time and across covariates. We provide both theoretical, regarding the consistency of functional causal effects, as well as empirical comparison of a range of proposed causal effect estimators. Applications to binary treatment settings with functional outcomes illustrate the framework's utility in biomedical monitoring, where outcomes exhibit complex temporal dynamics. Our estimators accommodate scenarios with registered covariates and outcomes, aligning them to the Fr\'{e}chet means, as well as cases requiring higher-order representations to capture intricate covariate-outcome interactions. These advancements extend causal inference to dynamic and non-linear domains, offering new tools for understanding complex treatment effects in functional data settings.
Asymptotic Optimism of Random-Design Linear and Kernel Regression Models
Feb 18, 2025We derived the closed-form asymptotic optimism of linear regression models under random designs, and generalizes it to kernel ridge regression. Using scaled asymptotic optimism as a generic predictive model complexity measure, we studied the fundamental different behaviors of linear regression model, tangent kernel (NTK) regression model and three-layer fully connected neural networks (NN). Our contribution is two-fold: we provided theoretical ground for using scaled optimism as a model predictive complexity measure; and we show empirically that NN with ReLUs behaves differently from kernel models under this measure. With resampling techniques, we can also compute the optimism for regression models with real data.