 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAscribe New Dimensions to Scientific Data Visualization with VR
Apr 18, 2025For over half a century, the computer mouse has been the primary tool for interacting with digital data, yet it remains a limiting factor in exploring complex, multi-scale scientific images. Traditional 2D visualization methods hinder intuitive analysis of inherently 3D structures. Virtual Reality (VR) offers a transformative alternative, providing immersive, interactive environments that enhance data comprehension. This article introduces ASCRIBE-VR, a VR platform of Autonomous Solutions for Computational Research with Immersive Browsing \& Exploration, which integrates AI-driven algorithms with scientific images. ASCRIBE-VR enables multimodal analysis, structural assessments, and immersive visualization, supporting scientific visualization of advanced datasets such as X-ray CT, Magnetic Resonance, and synthetic 3D imaging. Our VR tools, compatible with Meta Quest, can consume the output of our AI-based segmentation and iterative feedback processes to enable seamless exploration of large-scale 3D images. By merging AI-generated results with VR visualization, ASCRIBE-VR enhances scientific discovery, bridging the gap between computational analysis and human intuition in materials research, connecting human-in-the-loop with digital twins.
Compactly-supported nonstationary kernels for computing exact Gaussian processes on big data
Nov 07, 2024



The Gaussian process (GP) is a widely used probabilistic machine learning method for stochastic function approximation, stochastic modeling, and analyzing real-world measurements of nonlinear processes. Unlike many other machine learning methods, GPs include an implicit characterization of uncertainty, making them extremely useful across many areas of science, technology, and engineering. Traditional implementations of GPs involve stationary kernels (also termed covariance functions) that limit their flexibility and exact methods for inference that prevent application to data sets with more than about ten thousand points. Modern approaches to address stationarity assumptions generally fail to accommodate large data sets, while all attempts to address scalability focus on approximating the Gaussian likelihood, which can involve subjectivity and lead to inaccuracies. In this work, we explicitly derive an alternative kernel that can discover and encode both sparsity and nonstationarity. We embed the kernel within a fully Bayesian GP model and leverage high-performance computing resources to enable the analysis of massive data sets. We demonstrate the favorable performance of our novel kernel relative to existing exact and approximate GP methods across a variety of synthetic data examples. Furthermore, we conduct space-time prediction based on more than one million measurements of daily maximum temperature and verify that our results outperform state-of-the-art methods in the Earth sciences. More broadly, having access to exact GPs that use ultra-scalable, sparsity-discovering, nonstationary kernels allows GP methods to truly compete with a wide variety of machine learning methods.
MLExchange: A web-based platform enabling exchangeable machine learning workflows
Aug 23, 2022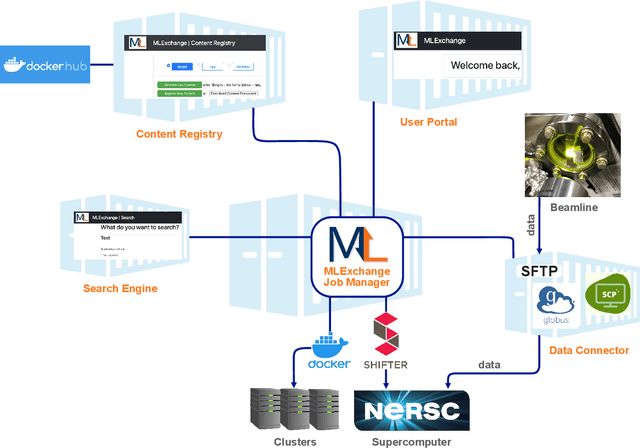
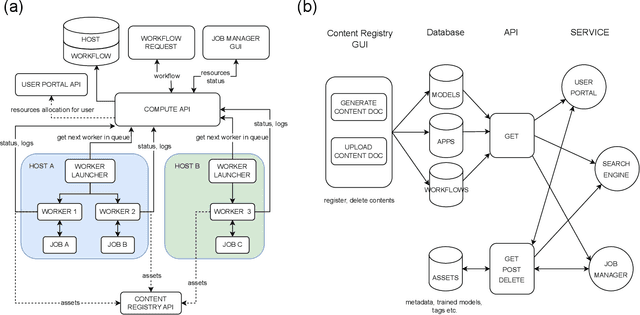
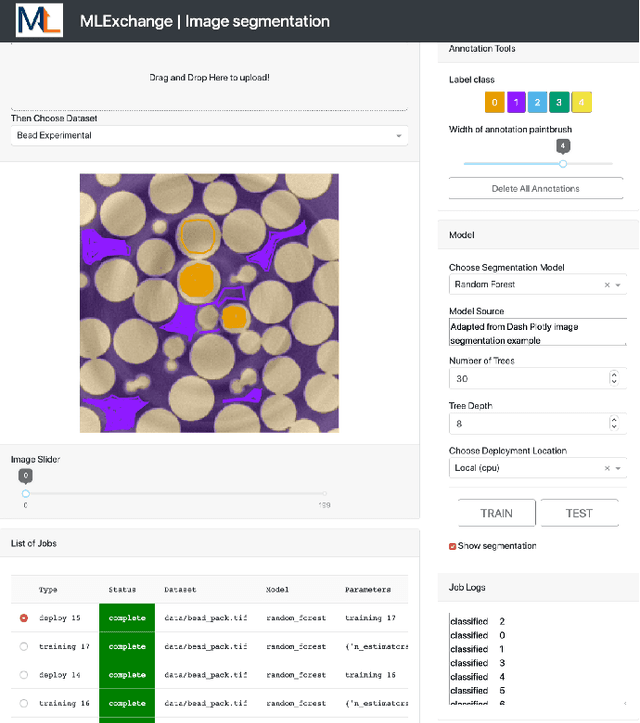
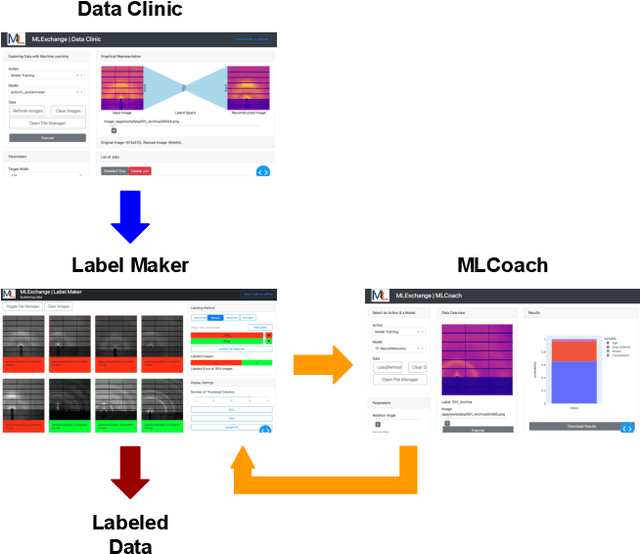
Machine learning (ML) algorithms are showing a growing trend in helping the scientific communities across different disciplines and institutions to address large and diverse data problems. However, many available ML tools are programmatically demanding and computationally costly. The MLExchange project aims to build a collaborative platform equipped with enabling tools that allow scientists and facility users who do not have a profound ML background to use ML and computational resources in scientific discovery. At the high level, we are targeting a full user experience where managing and exchanging ML algorithms, workflows, and data are readily available through web applications. So far, we have built four major components, i.e, the central job manager, the centralized content registry, user portal, and search engine, and successfully deployed these components on a testing server. Since each component is an independent container, the whole platform or its individual service(s) can be easily deployed at servers of different scales, ranging from a laptop (usually a single user) to high performance clusters (HPC) accessed (simultaneously) by many users. Thus, MLExchange renders flexible using scenarios -- users could either access the services and resources from a remote server or run the whole platform or its individual service(s) within their local network.