 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLExchange: A web-based platform enabling exchangeable machine learning workflows
Aug 23, 2022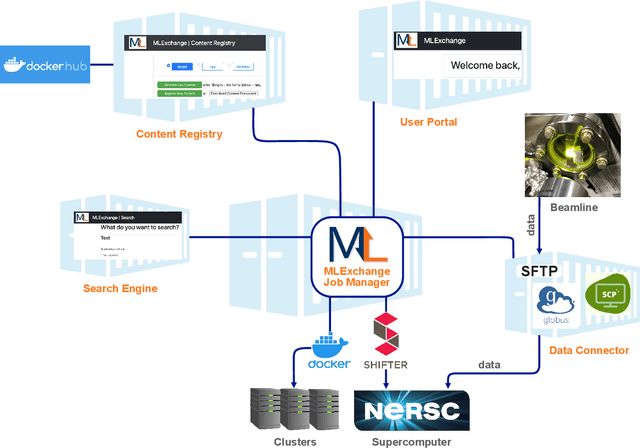
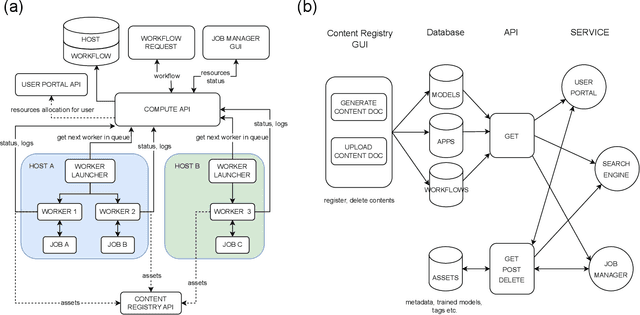
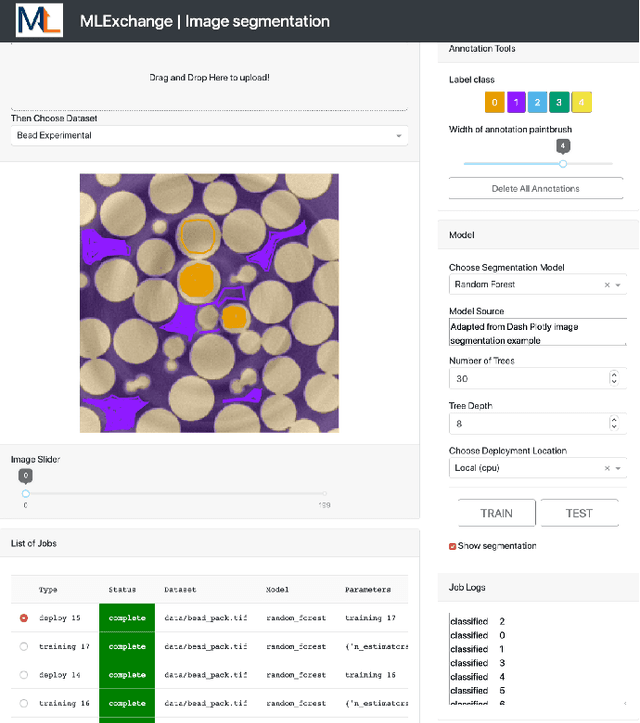
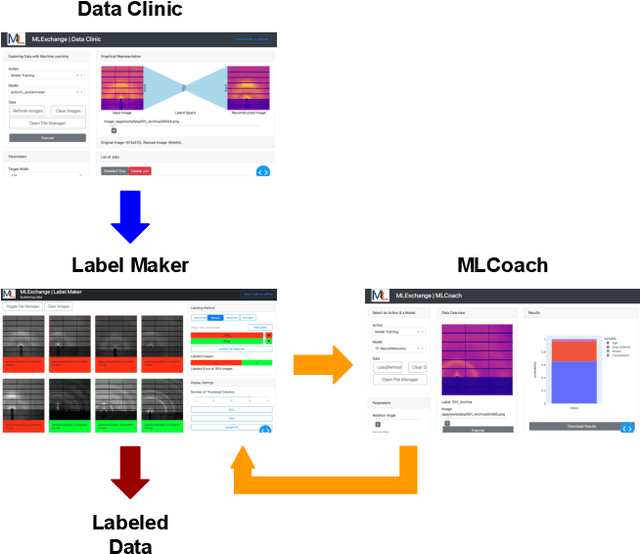
Machine learning (ML) algorithms are showing a growing trend in helping the scientific communities across different disciplines and institutions to address large and diverse data problems. However, many available ML tools are programmatically demanding and computationally costly. The MLExchange project aims to build a collaborative platform equipped with enabling tools that allow scientists and facility users who do not have a profound ML background to use ML and computational resources in scientific discovery. At the high level, we are targeting a full user experience where managing and exchanging ML algorithms, workflows, and data are readily available through web applications. So far, we have built four major components, i.e, the central job manager, the centralized content registry, user portal, and search engine, and successfully deployed these components on a testing server. Since each component is an independent container, the whole platform or its individual service(s) can be easily deployed at servers of different scales, ranging from a laptop (usually a single user) to high performance clusters (HPC) accessed (simultaneously) by many users. Thus, MLExchange renders flexible using scenarios -- users could either access the services and resources from a remote server or run the whole platform or its individual service(s) within their local network.
Exact Gaussian Processes for Massive Datasets via Non-Stationary Sparsity-Discovering Kernels
May 18, 2022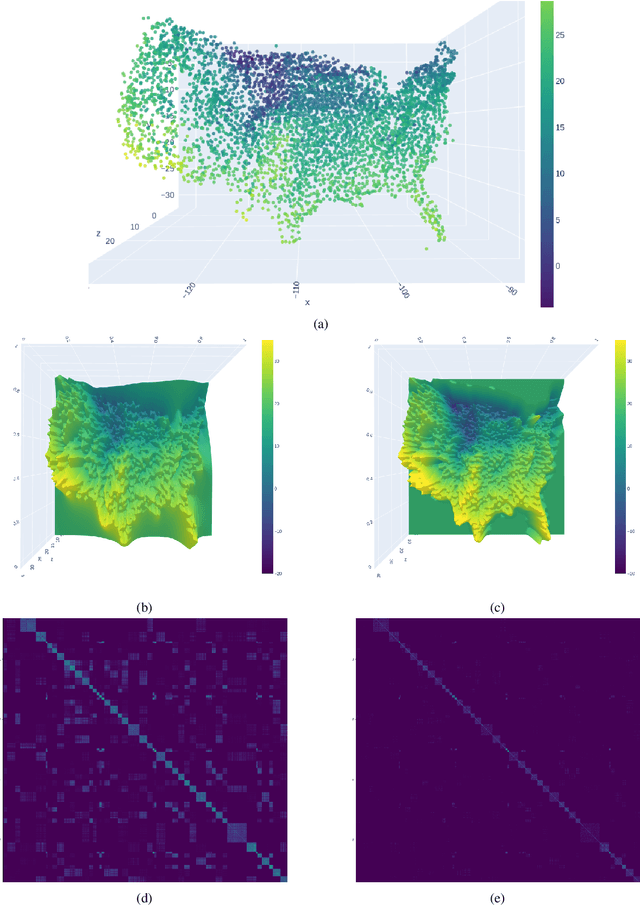
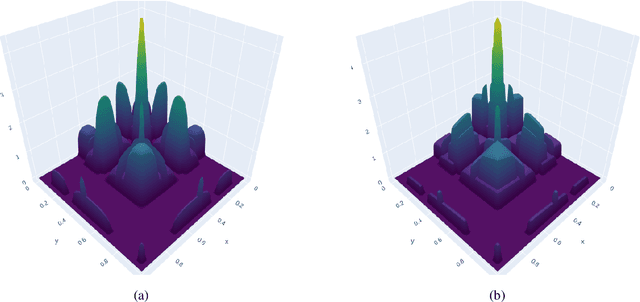
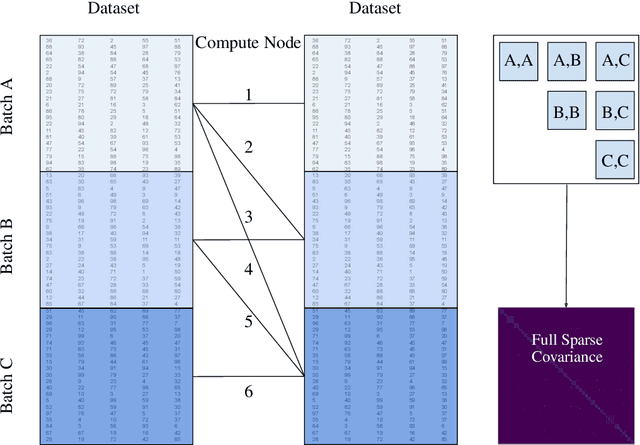

A Gaussian Process (GP) is a prominent mathematical framework for stochastic function approximation in science and engineering applications. This success is largely attributed to the GP's analytical tractability, robustness, non-parametric structure, and natural inclusion of uncertainty quantification. Unfortunately, the use of exact GPs is prohibitively expensive for large datasets due to their unfavorable numerical complexity of $O(N^3)$ in computation and $O(N^2)$ in storage. All existing methods addressing this issue utilize some form of approximation -- usually considering subsets of the full dataset or finding representative pseudo-points that render the covariance matrix well-structured and sparse. These approximate methods can lead to inaccuracies in function approximations and often limit the user's flexibility in designing expressive kernels. Instead of inducing sparsity via data-point geometry and structure, we propose to take advantage of naturally-occurring sparsity by allowing the kernel to discover -- instead of induce -- sparse structure. The premise of this paper is that GPs, in their most native form, are often naturally sparse, but commonly-used kernels do not allow us to exploit this sparsity. The core concept of exact, and at the same time sparse GPs relies on kernel definitions that provide enough flexibility to learn and encode not only non-zero but also zero covariances. This principle of ultra-flexible, compactly-supported, and non-stationary kernels, combined with HPC and constrained optimization, lets us scale exact GPs well beyond 5 million data points.