 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGMPs: Generalized Gaussian Mixture Processes
Mar 11, 2026Conditional density estimation is complicated by multimodality, heteroscedasticity, and strong non-Gaussianity. Gaussian processes (GPs) provide a principled nonparametric framework with calibrated uncertainty, but standard GP regression is limited by its unimodal Gaussian predictive form. We introduce the Generalized Gaussian Mixture Process (GGMP), a GP-based method for multimodal conditional density estimation in settings where each input may be associated with a complex output distribution rather than a single scalar response. GGMP combines local Gaussian mixture fitting, cross-input component alignment and per-component heteroscedastic GP training to produce a closed-form Gaussian mixture predictive density. The method is tractable, compatible with standard GP solvers and scalable methods, and avoids the exponentially large latent-assignment structure of naive multimodal GP formulations. Empirically, GGMPs improve distributional approximation on synthetic and real-world datasets with pronounced non-Gaussianity and multimodality.
Compactly-supported nonstationary kernels for computing exact Gaussian processes on big data
Nov 07, 2024



The Gaussian process (GP) is a widely used probabilistic machine learning method for stochastic function approximation, stochastic modeling, and analyzing real-world measurements of nonlinear processes. Unlike many other machine learning methods, GPs include an implicit characterization of uncertainty, making them extremely useful across many areas of science, technology, and engineering. Traditional implementations of GPs involve stationary kernels (also termed covariance functions) that limit their flexibility and exact methods for inference that prevent application to data sets with more than about ten thousand points. Modern approaches to address stationarity assumptions generally fail to accommodate large data sets, while all attempts to address scalability focus on approximating the Gaussian likelihood, which can involve subjectivity and lead to inaccuracies. In this work, we explicitly derive an alternative kernel that can discover and encode both sparsity and nonstationarity. We embed the kernel within a fully Bayesian GP model and leverage high-performance computing resources to enable the analysis of massive data sets. We demonstrate the favorable performance of our novel kernel relative to existing exact and approximate GP methods across a variety of synthetic data examples. Furthermore, we conduct space-time prediction based on more than one million measurements of daily maximum temperature and verify that our results outperform state-of-the-art methods in the Earth sciences. More broadly, having access to exact GPs that use ultra-scalable, sparsity-discovering, nonstationary kernels allows GP methods to truly compete with a wide variety of machine learning methods.
A Unifying Perspective on Non-Stationary Kernels for Deeper Gaussian Processes
Sep 18, 2023The Gaussian process (GP) is a popular statistical technique for stochastic function approximation and uncertainty quantification from data. GPs have been adopted into the realm of machine learning in the last two decades because of their superior prediction abilities, especially in data-sparse scenarios, and their inherent ability to provide robust uncertainty estimates. Even so, their performance highly depends on intricate customizations of the core methodology, which often leads to dissatisfaction among practitioners when standard setups and off-the-shelf software tools are being deployed. Arguably the most important building block of a GP is the kernel function which assumes the role of a covariance operator. Stationary kernels of the Mat\'ern class are used in the vast majority of applied studies; poor prediction performance and unrealistic uncertainty quantification are often the consequences. Non-stationary kernels show improved performance but are rarely used due to their more complicated functional form and the associated effort and expertise needed to define and tune them optimally. In this perspective, we want to help ML practitioners make sense of some of the most common forms of non-stationarity for Gaussian processes. We show a variety of kernels in action using representative datasets, carefully study their properties, and compare their performances. Based on our findings, we propose a new kernel that combines some of the identified advantages of existing kernels.
Exact Gaussian Processes for Massive Datasets via Non-Stationary Sparsity-Discovering Kernels
May 18, 2022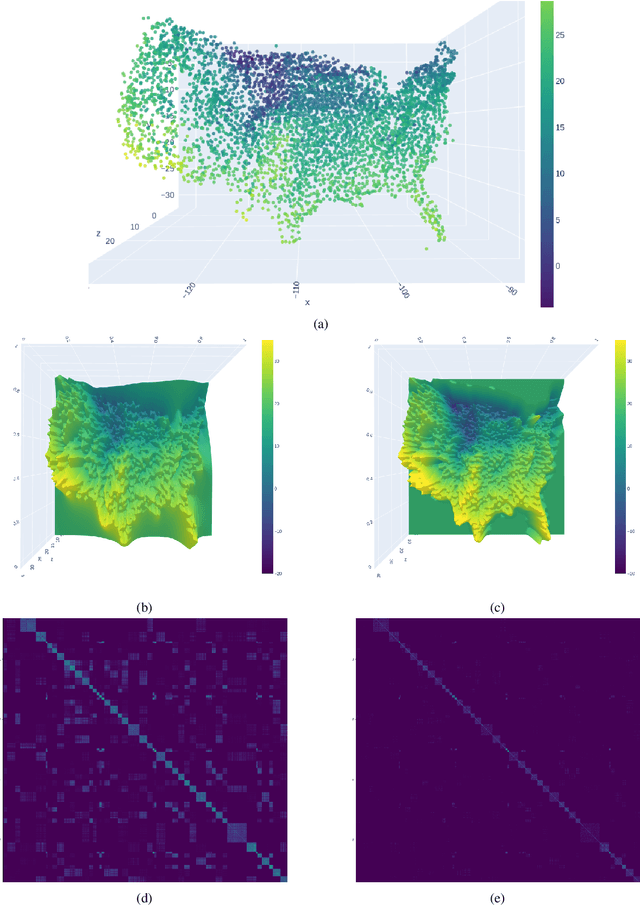
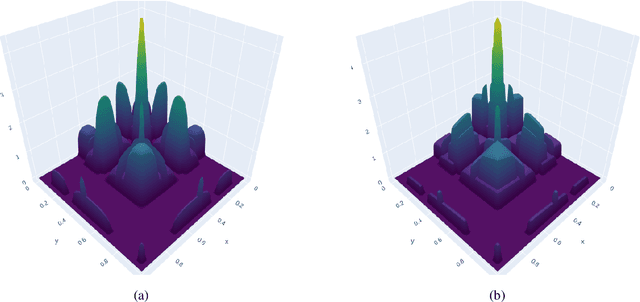
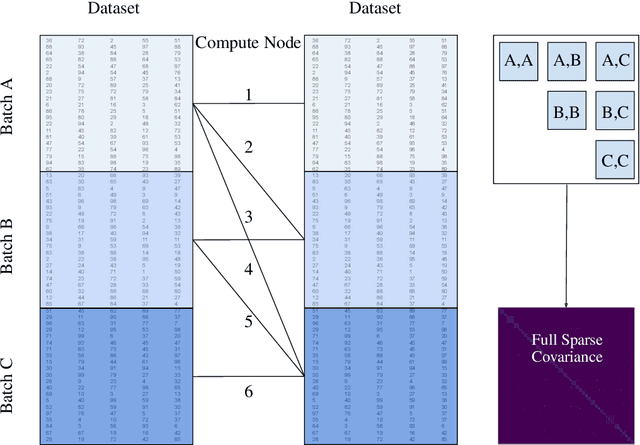

A Gaussian Process (GP) is a prominent mathematical framework for stochastic function approximation in science and engineering applications. This success is largely attributed to the GP's analytical tractability, robustness, non-parametric structure, and natural inclusion of uncertainty quantification. Unfortunately, the use of exact GPs is prohibitively expensive for large datasets due to their unfavorable numerical complexity of $O(N^3)$ in computation and $O(N^2)$ in storage. All existing methods addressing this issue utilize some form of approximation -- usually considering subsets of the full dataset or finding representative pseudo-points that render the covariance matrix well-structured and sparse. These approximate methods can lead to inaccuracies in function approximations and often limit the user's flexibility in designing expressive kernels. Instead of inducing sparsity via data-point geometry and structure, we propose to take advantage of naturally-occurring sparsity by allowing the kernel to discover -- instead of induce -- sparse structure. The premise of this paper is that GPs, in their most native form, are often naturally sparse, but commonly-used kernels do not allow us to exploit this sparsity. The core concept of exact, and at the same time sparse GPs relies on kernel definitions that provide enough flexibility to learn and encode not only non-zero but also zero covariances. This principle of ultra-flexible, compactly-supported, and non-stationary kernels, combined with HPC and constrained optimization, lets us scale exact GPs well beyond 5 million data points.
Advanced Stationary and Non-Stationary Kernel Designs for Domain-Aware Gaussian Processes
Feb 05, 2021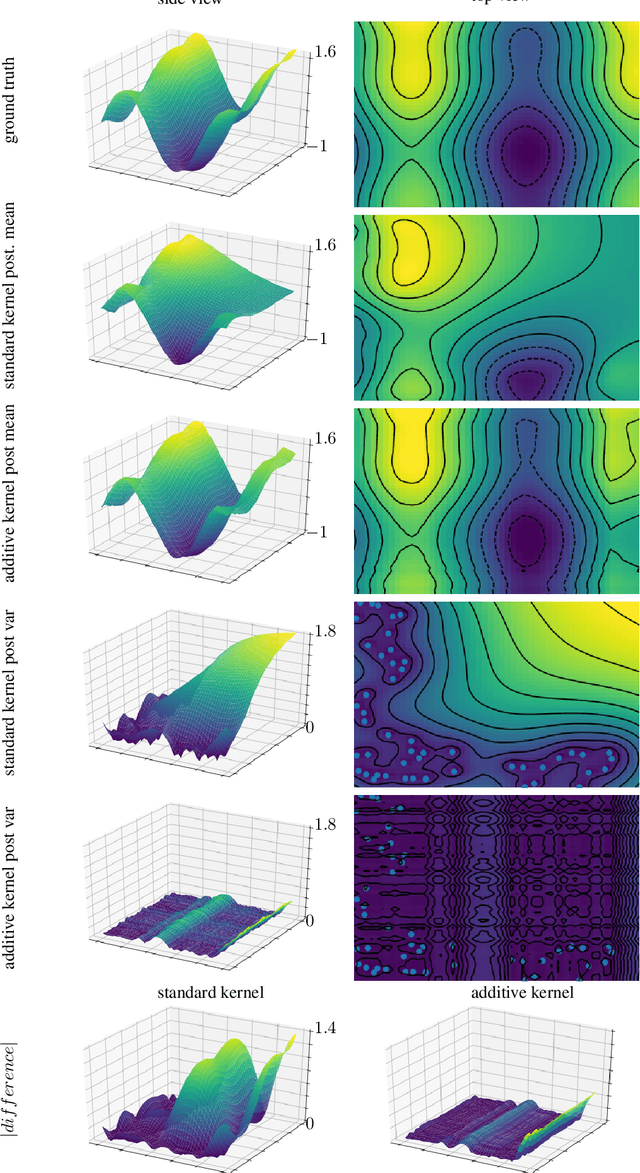
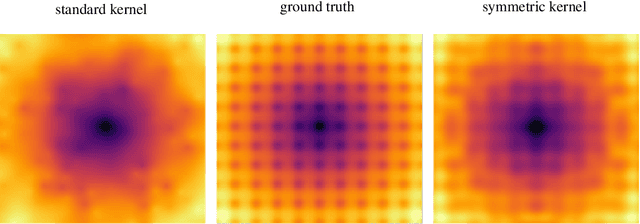

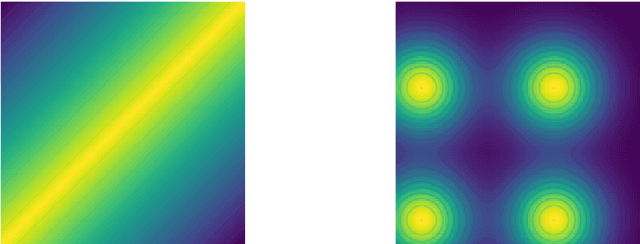
Gaussian process regression is a widely-applied method for function approximation and uncertainty quantification. The technique has gained popularity recently in the machine learning community due to its robustness and interpretability. The mathematical methods we discuss in this paper are an extension of the Gaussian-process framework. We are proposing advanced kernel designs that only allow for functions with certain desirable characteristics to be elements of the reproducing kernel Hilbert space (RKHS) that underlies all kernel methods and serves as the sample space for Gaussian process regression. These desirable characteristics reflect the underlying physics; two obvious examples are symmetry and periodicity constraints. In addition, non-stationary kernel designs can be defined in the same framework to yield flexible multi-task Gaussian processes. We will show the impact of advanced kernel designs on Gaussian processes using several synthetic and two scientific data sets. The results show that including domain knowledge, communicated through advanced kernel designs, has a significant impact on the accuracy and relevance of the function approximation.
Autonomous Materials Discovery Driven by Gaussian Process Regression with Inhomogeneous Measurement Noise and Anisotropic Kernels
Jun 03, 2020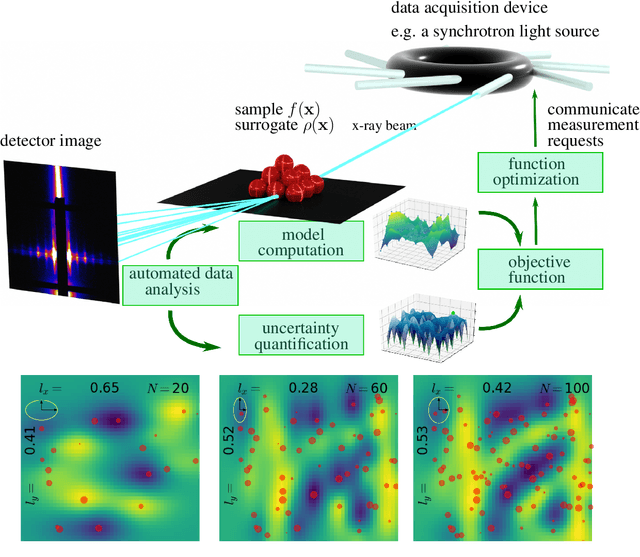
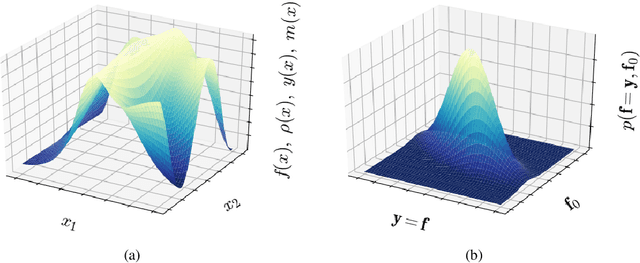
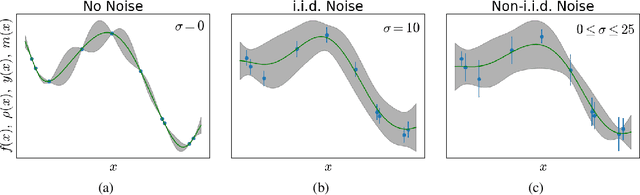
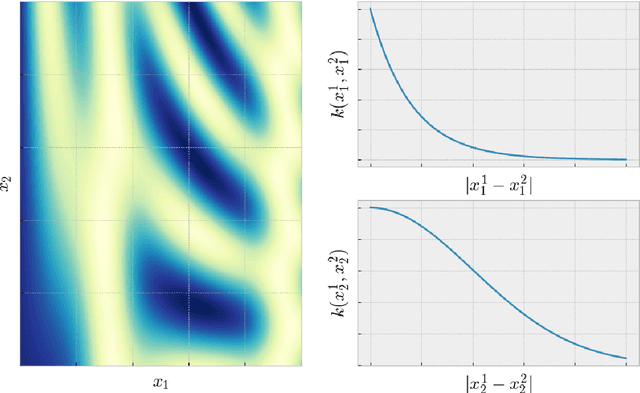
A majority of experimental disciplines face the challenge of exploring large and high-dimensional parameter spaces in search of new scientific discoveries. Materials science is no exception; the wide variety of synthesis, processing, and environmental conditions that influence material properties gives rise to particularly vast parameter spaces. Recent advances have led to an increase in efficiency of materials discovery by increasingly automating the exploration processes. Methods for autonomous experimentation have become more sophisticated recently, allowing for multi-dimensional parameter spaces to be explored efficiently and with minimal human intervention, thereby liberating the scientists to focus on interpretations and big-picture decisions. Gaussian process regression (GPR) techniques have emerged as the method of choice for steering many classes of experiments. We have recently demonstrated the positive impact of GPR-driven decision-making algorithms on autonomously steering experiments at a synchrotron beamline. However, due to the complexity of the experiments, GPR often cannot be used in its most basic form, but rather has to be tuned to account for the special requirements of the experiments. Two requirements seem to be of particular importance, namely inhomogeneous measurement noise (input dependent or non-i.i.d.) and anisotropic kernel functions, which are the two concepts that we tackle in this paper. Our synthetic and experimental tests demonstrate the importance of both concepts for experiments in materials science and the benefits that result from including them in the autonomous decision-making process.