 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidTAG: Temporally Aligned Video to GPS Geolocalization with Denoising Sequence Prediction at a Global Scale
Apr 14, 2026The task of video geolocalization aims to determine the precise GPS coordinates of a video's origin and map its trajectory; with applications in forensics, social media, and exploration. Existing classification-based approaches operate at a coarse city-level granularity and fail to capture fine-grained details, while image retrieval methods are impractical on a global scale due to the need for extensive image galleries which are infeasible to compile. Comparatively, constructing a gallery of GPS coordinates is straightforward and inexpensive. We propose VidTAG, a dual-encoder framework that performs frame-to-GPS retrieval using both self-supervised and language-aligned features. To address temporal inconsistencies in video predictions, we introduce the TempGeo module, which aligns frame embeddings, and the GeoRefiner module, an encoder-decoder architecture that refines GPS features using the aligned frame embeddings. Evaluations on Mapillary (MSLS) and GAMa datasets demonstrate our model's ability to generate temporally consistent trajectories and outperform baselines, achieving a 20% improvement at the 1 km threshold over GeoCLIP. We also beat current State-of-the-Art by 25% on global coarse grained video geolocalization (CityGuessr68k). Our approach enables fine-grained video geolocalization and lays a strong foundation for future research. More details on the project webpage: https://parthpk.github.io/vidtag_webpage/
Learning to Share: Selective Memory for Efficient Parallel Agentic Systems
Feb 05, 2026Agentic systems solve complex tasks by coordinating multiple agents that iteratively reason, invoke tools, and exchange intermediate results. To improve robustness and solution quality, recent approaches deploy multiple agent teams running in parallel to explore diverse reasoning trajectories. However, parallel execution comes at a significant computational cost: when different teams independently reason about similar sub-problems or execute analogous steps, they repeatedly perform substantial overlapping computation. To address these limitations, in this paper, we propose Learning to Share (LTS), a learned shared-memory mechanism for parallel agentic frameworks that enables selective cross-team information reuse while controlling context growth. LTS introduces a global memory bank accessible to all teams and a lightweight controller that decides whether intermediate agent steps should be added to memory or not. The controller is trained using stepwise reinforcement learning with usage-aware credit assignment, allowing it to identify information that is globally useful across parallel executions. Experiments on the AssistantBench and GAIA benchmarks show that LTS significantly reduces overall runtime while matching or improving task performance compared to memory-free parallel baselines, demonstrating that learned memory admission is an effective strategy for improving the efficiency of parallel agentic systems. Project page: https://joefioresi718.github.io/LTS_webpage/
GAEA: A Geolocation Aware Conversational Model
Mar 20, 2025



Image geolocalization, in which, traditionally, an AI model predicts the precise GPS coordinates of an image is a challenging task with many downstream applications. However, the user cannot utilize the model to further their knowledge other than the GPS coordinate; the model lacks an understanding of the location and the conversational ability to communicate with the user. In recent days, with tremendous progress of large multimodal models (LMMs) proprietary and open-source researchers have attempted to geolocalize images via LMMs. However, the issues remain unaddressed; beyond general tasks, for more specialized downstream tasks, one of which is geolocalization, LMMs struggle. In this work, we propose to solve this problem by introducing a conversational model GAEA that can provide information regarding the location of an image, as required by a user. No large-scale dataset enabling the training of such a model exists. Thus we propose a comprehensive dataset GAEA with 800K images and around 1.6M question answer pairs constructed by leveraging OpenStreetMap (OSM) attributes and geographical context clues. For quantitative evaluation, we propose a diverse benchmark comprising 4K image-text pairs to evaluate conversational capabilities equipped with diverse question types. We consider 11 state-of-the-art open-source and proprietary LMMs and demonstrate that GAEA significantly outperforms the best open-source model, LLaVA-OneVision by 25.69% and the best proprietary model, GPT-4o by 8.28%. Our dataset, model and codes are available
CityGuessr: City-Level Video Geo-Localization on a Global Scale
Nov 10, 2024



Video geolocalization is a crucial problem in current times. Given just a video, ascertaining where it was captured from can have a plethora of advantages. The problem of worldwide geolocalization has been tackled before, but only using the image modality. Its video counterpart remains relatively unexplored. Meanwhile, video geolocalization has also garnered some attention in the recent past, but the existing methods are all restricted to specific regions. This motivates us to explore the problem of video geolocalization at a global scale. Hence, we propose a novel problem of worldwide video geolocalization with the objective of hierarchically predicting the correct city, state/province, country, and continent, given a video. However, no large scale video datasets that have extensive worldwide coverage exist, to train models for solving this problem. To this end, we introduce a new dataset, CityGuessr68k comprising of 68,269 videos from 166 cities all over the world. We also propose a novel baseline approach to this problem, by designing a transformer-based architecture comprising of an elegant Self-Cross Attention module for incorporating scenes as well as a TextLabel Alignment strategy for distilling knowledge from textlabels in feature space. To further enhance our location prediction, we also utilize soft-scene labels. Finally we demonstrate the performance of our method on our new dataset as well as Mapillary(MSLS). Our code and datasets are available at: https://github.com/ParthPK/CityGuessr
Xi-Net: Transformer Based Seismic Waveform Reconstructor
Jun 14, 2024



Missing/erroneous data is a major problem in today's world. Collected seismic data sometimes contain gaps due to multitude of reasons like interference and sensor malfunction. Gaps in seismic waveforms hamper further signal processing to gain valuable information. Plethora of techniques are used for data reconstruction in other domains like image, video, audio, but translation of those methods to address seismic waveforms demands adapting them to lengthy sequence inputs, which is practically complex. Even if that is accomplished, high computational costs and inefficiency would still persist in these predominantly convolution-based reconstruction models. In this paper, we present a transformer-based deep learning model, Xi-Net, which utilizes multi-faceted time and frequency domain inputs for accurate waveform reconstruction. Xi-Net converts the input waveform to frequency domain, employs separate encoders for time and frequency domains, and one decoder for getting reconstructed output waveform from the fused features. 1D shifted-window transformer blocks form the elementary units of all parts of the model. To the best of our knowledge, this is the first transformer-based deep learning model for seismic waveform reconstruction. We demonstrate this model's prowess by filling 0.5-1s random gaps in 120s waveforms, resembling the original waveform quite closely. The code, models can be found at: https://github.com/Anshuman04/waveformReconstructor.
Where We Are and What We're Looking At: Query Based Worldwide Image Geo-localization Using Hierarchies and Scenes
Mar 07, 2023
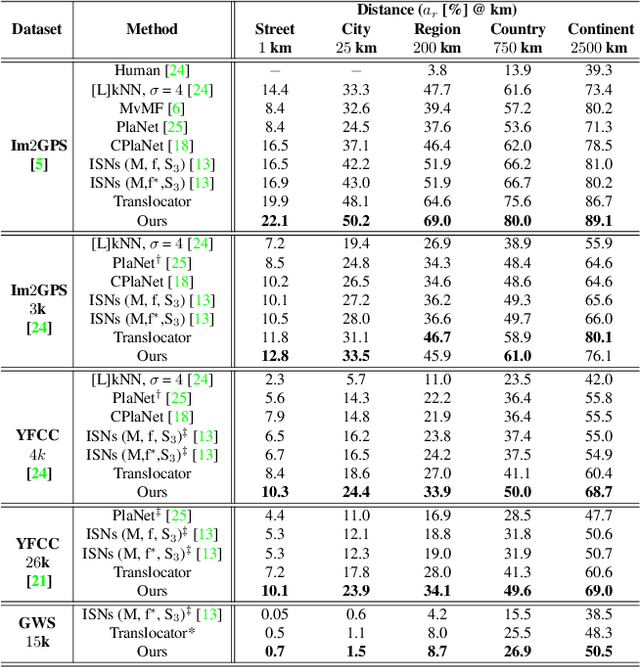

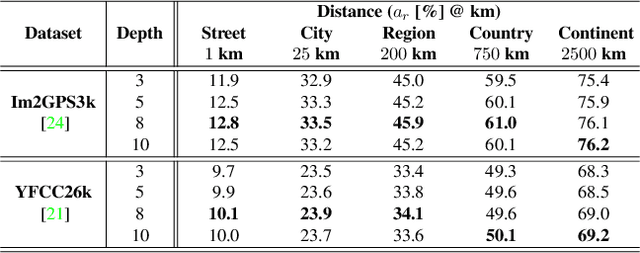
Determining the exact latitude and longitude that a photo was taken is a useful and widely applicable task, yet it remains exceptionally difficult despite the accelerated progress of other computer vision tasks. Most previous approaches have opted to learn a single representation of query images, which are then classified at different levels of geographic granularity. These approaches fail to exploit the different visual cues that give context to different hierarchies, such as the country, state, and city level. To this end, we introduce an end-to-end transformer-based architecture that exploits the relationship between different geographic levels (which we refer to as hierarchies) and the corresponding visual scene information in an image through hierarchical cross-attention. We achieve this by learning a query for each geographic hierarchy and scene type. Furthermore, we learn a separate representation for different environmental scenes, as different scenes in the same location are often defined by completely different visual features. We achieve state of the art street level accuracy on 4 standard geo-localization datasets : Im2GPS, Im2GPS3k, YFCC4k, and YFCC26k, as well as qualitatively demonstrate how our method learns different representations for different visual hierarchies and scenes, which has not been demonstrated in the previous methods. These previous testing datasets mostly consist of iconic landmarks or images taken from social media, which makes them either a memorization task, or biased towards certain places. To address this issue we introduce a much harder testing dataset, Google-World-Streets-15k, comprised of images taken from Google Streetview covering the whole planet and present state of the art results. Our code will be made available in the camera-ready version.