 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Spatial augmentation in Self-supervised models in the purview of training and test distributions
Paper and Code
Sep 26, 2024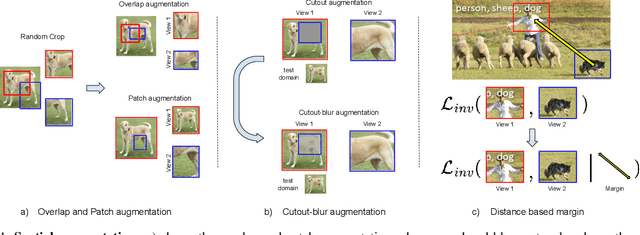
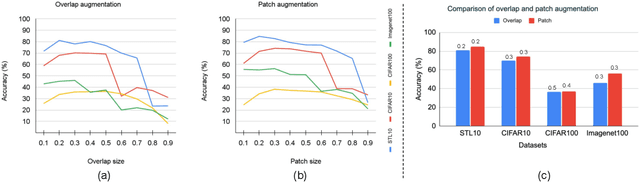
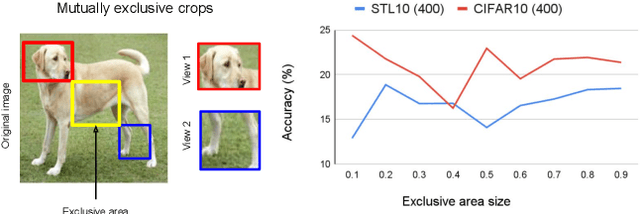
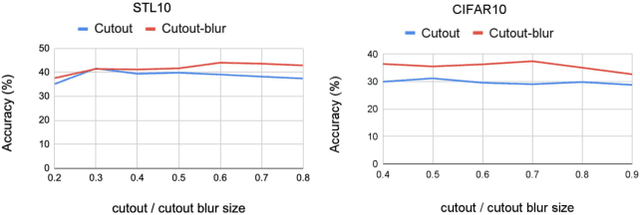
In this paper, we present an empirical study of typical spatial augmentation techniques used in self-supervised representation learning methods (both contrastive and non-contrastive), namely random crop and cutout. Our contributions are: (a) we dissociate random cropping into two separate augmentations, overlap and patch, and provide a detailed analysis on the effect of area of overlap and patch size to the accuracy on down stream tasks. (b) We offer an insight into why cutout augmentation does not learn good representation, as reported in earlier literature. Finally, based on these analysis, (c) we propose a distance-based margin to the invariance loss for learning scene-centric representations for the downstream task on object-centric distribution, showing that as simple as a margin proportional to the pixel distance between the two spatial views in the scence-centric images can improve the learned representation. Our study furthers the understanding of the spatial augmentations, and the effect of the domain-gap between the training augmentations and the test distribution.