 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretation of Emergent Communication in Heterogeneous Collaborative Embodied Agents
Oct 12, 2021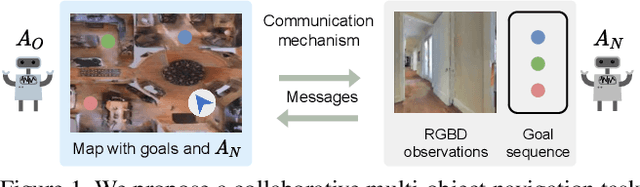
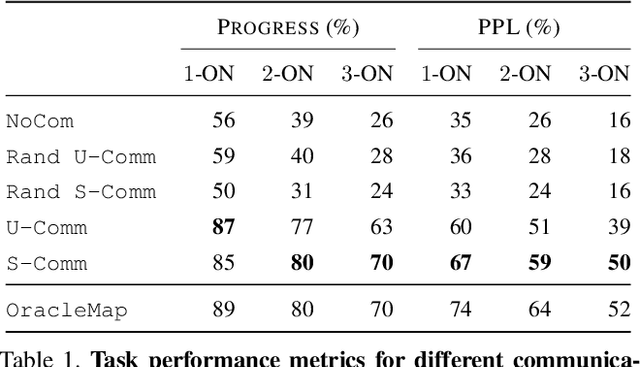
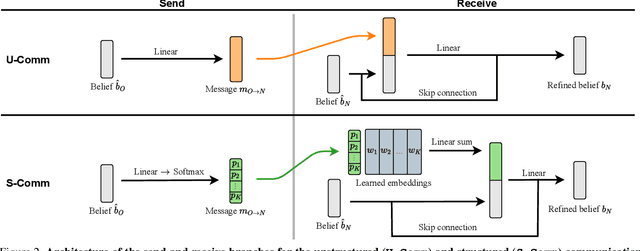
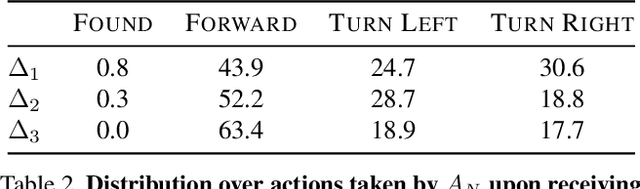
Communication between embodied AI agents has received increasing attention in recent years. Despite its use, it is still unclear whether the learned communication is interpretable and grounded in perception. To study the grounding of emergent forms of communication, we first introduce the collaborative multi-object navigation task CoMON. In this task, an oracle agent has detailed environment information in the form of a map. It communicates with a navigator agent that perceives the environment visually and is tasked to find a sequence of goals. To succeed at the task, effective communication is essential. CoMON hence serves as a basis to study different communication mechanisms between heterogeneous agents, that is, agents with different capabilities and roles. We study two common communication mechanisms and analyze their communication patterns through an egocentric and spatial lens. We show that the emergent communication can be grounded to the agent observations and the spatial structure of the 3D environment. Video summary: https://youtu.be/kLv2rxO9t0g
Language-Aligned Waypoint (LAW) Supervision for Vision-and-Language Navigation in Continuous Environments
Sep 30, 2021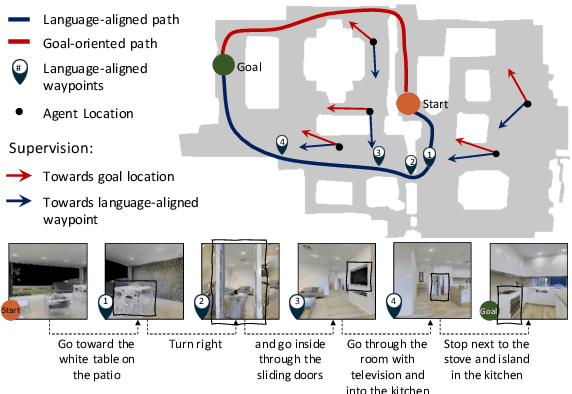

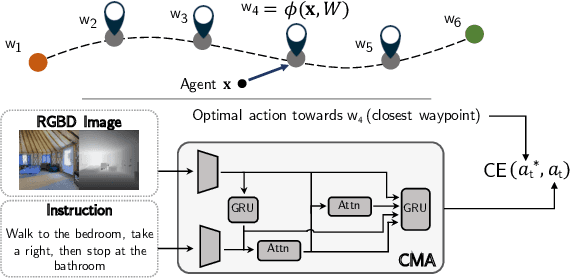
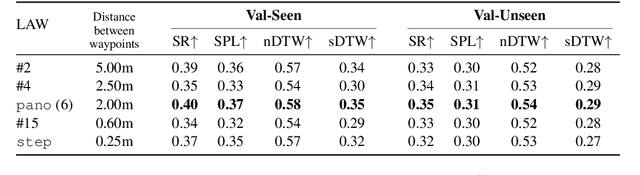
In the Vision-and-Language Navigation (VLN) task an embodied agent navigates a 3D environment, following natural language instructions. A challenge in this task is how to handle 'off the path' scenarios where an agent veers from a reference path. Prior work supervises the agent with actions based on the shortest path from the agent's location to the goal, but such goal-oriented supervision is often not in alignment with the instruction. Furthermore, the evaluation metrics employed by prior work do not measure how much of a language instruction the agent is able to follow. In this work, we propose a simple and effective language-aligned supervision scheme, and a new metric that measures the number of sub-instructions the agent has completed during navigation.
An End-to-End Network for Emotion-Cause Pair Extraction
Mar 03, 2021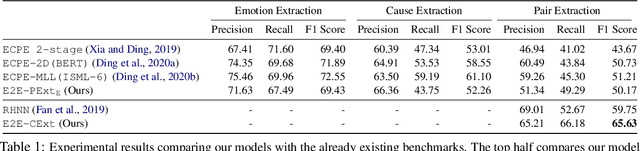
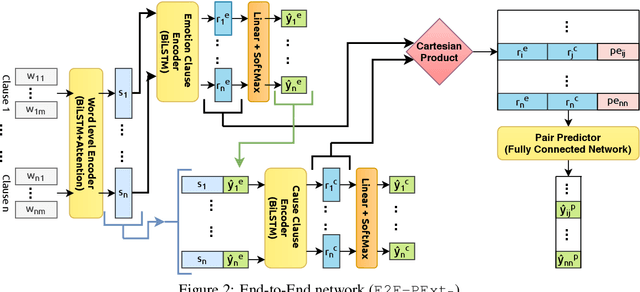

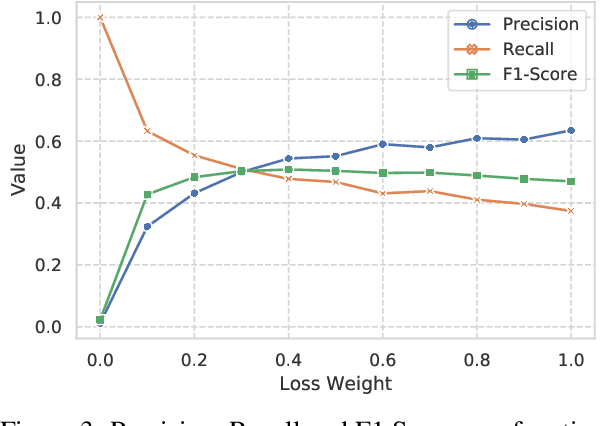
The task of Emotion-Cause Pair Extraction (ECPE) aims to extract all potential clause-pairs of emotions and their corresponding causes in a document. Unlike the more well-studied task of Emotion Cause Extraction (ECE), ECPE does not require the emotion clauses to be provided as annotations. Previous works on ECPE have either followed a multi-stage approach where emotion extraction, cause extraction, and pairing are done independently or use complex architectures to resolve its limitations. In this paper, we propose an end-to-end model for the ECPE task. Due to the unavailability of an English language ECPE corpus, we adapt the NTCIR-13 ECE corpus and establish a baseline for the ECPE task on this dataset. On this dataset, the proposed method produces significant performance improvements (~6.5 increase in F1 score) over the multi-stage approach and achieves comparable performance to the state-of-the-art methods.
MultiON: Benchmarking Semantic Map Memory using Multi-Object Navigation
Dec 07, 2020
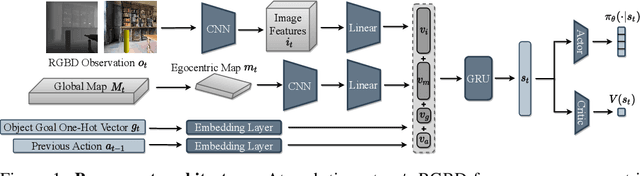


Navigation tasks in photorealistic 3D environments are challenging because they require perception and effective planning under partial observability. Recent work shows that map-like memory is useful for long-horizon navigation tasks. However, a focused investigation of the impact of maps on navigation tasks of varying complexity has not yet been performed. We propose the multiON task, which requires navigation to an episode-specific sequence of objects in a realistic environment. MultiON generalizes the ObjectGoal navigation task and explicitly tests the ability of navigation agents to locate previously observed goal objects. We perform a set of multiON experiments to examine how a variety of agent models perform across a spectrum of navigation task complexities. Our experiments show that: i) navigation performance degrades dramatically with escalating task complexity; ii) a simple semantic map agent performs surprisingly well relative to more complex neural image feature map agents; and iii) even oracle map agents achieve relatively low performance, indicating the potential for future work in training embodied navigation agents using maps. Video summary: https://youtu.be/yqTlHNIcgnY