 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of Domain Knowledge from Human Feedback in Text-to-SQL
Nov 10, 2025Large Language Models (LLMs) can generate SQL queries from natural language questions but struggle with database-specific schemas and tacit domain knowledge. We introduce a framework for continual learning from human feedback in text-to-SQL, where a learning agent receives natural language feedback to refine queries and distills the revealed knowledge for reuse on future tasks. This distilled knowledge is stored in a structured memory, enabling the agent to improve execution accuracy over time. We design and evaluate multiple variations of a learning agent architecture that vary in how they capture and retrieve past experiences. Experiments on the BIRD benchmark Dev set show that memory-augmented agents, particularly the Procedural Agent, achieve significant accuracy gains and error reduction by leveraging human-in-the-loop feedback. Our results highlight the importance of transforming tacit human expertise into reusable knowledge, paving the way for more adaptive, domain-aware text-to-SQL systems that continually learn from a human-in-the-loop.
Shining a Light on Hurricane Damage Estimation via Nighttime Light Data: Pre-processing Matters
Oct 29, 2024Amidst escalating climate change, hurricanes are inflicting severe socioeconomic impacts, marked by heightened economic losses and increased displacement. Previous research utilized nighttime light data to predict the impact of hurricanes on economic losses. However, prior work did not provide a thorough analysis of the impact of combining different techniques for pre-processing nighttime light (NTL) data. Addressing this gap, our research explores a variety of NTL pre-processing techniques, including value thresholding, built masking, and quality filtering and imputation, applied to two distinct datasets, VSC-NTL and VNP46A2, at the zip code level. Experiments evaluate the correlation of the denoised NTL data with economic damages of Category 4-5 hurricanes in Florida. They reveal that the quality masking and imputation technique applied to VNP46A2 show a substantial correlation with economic damage data.
Enabling Advanced Land Cover Analytics: An Integrated Data Extraction Pipeline for Predictive Modeling with the Dynamic World Dataset
Oct 11, 2024



Understanding land cover holds considerable potential for a myriad of practical applications, particularly as data accessibility transitions from being exclusive to governmental and commercial entities to now including the broader research community. Nevertheless, although the data is accessible to any community member interested in exploration, there exists a formidable learning curve and no standardized process for accessing, pre-processing, and leveraging the data for subsequent tasks. In this study, we democratize this data by presenting a flexible and efficient end to end pipeline for working with the Dynamic World dataset, a cutting-edge near-real-time land use/land cover (LULC) dataset. This includes a pre-processing and representation framework which tackles noise removal, efficient extraction of large amounts of data, and re-representation of LULC data in a format well suited for several downstream tasks. To demonstrate the power of our pipeline, we use it to extract data for an urbanization prediction problem and build a suite of machine learning models with excellent performance. This task is easily generalizable to the prediction of any type of land cover and our pipeline is also compatible with a series of other downstream tasks.
Exploring the Effectiveness of GPT Models in Test-Taking: A Case Study of the Driver's License Knowledge Test
Aug 22, 2023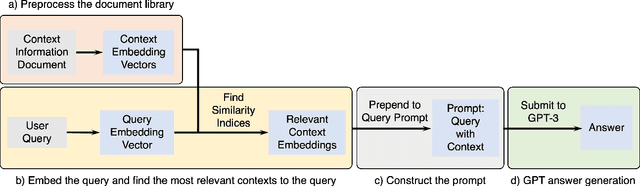


Large language models such as Open AI's Generative Pre-trained Transformer (GPT) models are proficient at answering questions, but their knowledge is confined to the information present in their training data. This limitation renders them ineffective when confronted with questions about recent developments or non-public documents. Our research proposes a method that enables GPT models to answer questions by employing context from an information source not previously included in their training data. The methodology includes preprocessing of contextual information, the embedding of contexts and queries, constructing prompt through the integration of context embeddings, and generating answers using GPT models. We applied this method in a controlled test scenario using the California Driver's Handbook as the information source. The GPT-3 model achieved a 96% passing score on a set of 50 sample driving knowledge test questions. In contrast, without context, the model's passing score fell to 82%. However, the model still fails to answer some questions correctly even with providing library of context, highlighting room for improvement. The research also examined the impact of prompt length and context format, on the model's performance. Overall, the study provides insights into the limitations and potential improvements for GPT models in question-answering tasks.
Financial Time Series Forecasting using CNN and Transformer
Apr 11, 2023

Time series forecasting is important across various domains for decision-making. In particular, financial time series such as stock prices can be hard to predict as it is difficult to model short-term and long-term temporal dependencies between data points. Convolutional Neural Networks (CNN) are good at capturing local patterns for modeling short-term dependencies. However, CNNs cannot learn long-term dependencies due to the limited receptive field. Transformers on the other hand are capable of learning global context and long-term dependencies. In this paper, we propose to harness the power of CNNs and Transformers to model both short-term and long-term dependencies within a time series, and forecast if the price would go up, down or remain the same (flat) in the future. In our experiments, we demonstrated the success of the proposed method in comparison to commonly adopted statistical and deep learning methods on forecasting intraday stock price change of S&P 500 constituents.