 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effectiveness of GPT Models in Test-Taking: A Case Study of the Driver's License Knowledge Test
Paper and Code
Aug 22, 2023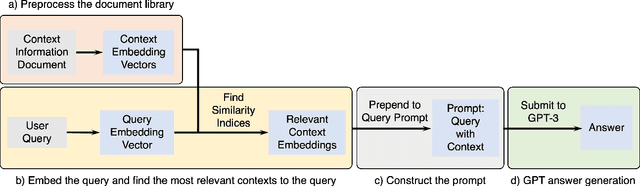

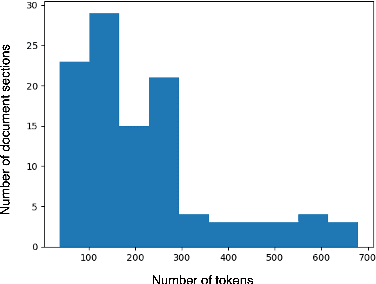

Large language models such as Open AI's Generative Pre-trained Transformer (GPT) models are proficient at answering questions, but their knowledge is confined to the information present in their training data. This limitation renders them ineffective when confronted with questions about recent developments or non-public documents. Our research proposes a method that enables GPT models to answer questions by employing context from an information source not previously included in their training data. The methodology includes preprocessing of contextual information, the embedding of contexts and queries, constructing prompt through the integration of context embeddings, and generating answers using GPT models. We applied this method in a controlled test scenario using the California Driver's Handbook as the information source. The GPT-3 model achieved a 96% passing score on a set of 50 sample driving knowledge test questions. In contrast, without context, the model's passing score fell to 82%. However, the model still fails to answer some questions correctly even with providing library of context, highlighting room for improvement. The research also examined the impact of prompt length and context format, on the model's performance. Overall, the study provides insights into the limitations and potential improvements for GPT models in question-answering tasks.