 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Neural Stochastic Differential Equations with Change Points
Nov 01, 2024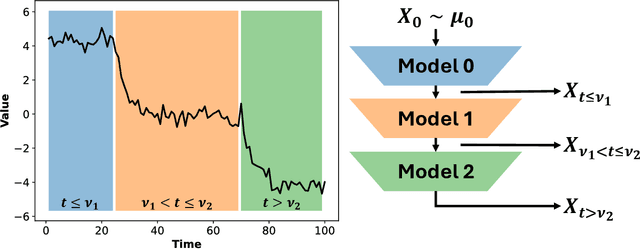


In this work, we explore modeling change points in time-series data using neural stochastic differential equations (neural SDEs). We propose a novel model formulation and training procedure based on the variational autoencoder (VAE) framework for modeling time-series as a neural SDE. Unlike existing algorithms training neural SDEs as VAEs, our proposed algorithm only necessitates a Gaussian prior of the initial state of the latent stochastic process, rather than a Wiener process prior on the entire latent stochastic process. We develop two methodologies for modeling and estimating change points in time-series data with distribution shifts. Our iterative algorithm alternates between updating neural SDE parameters and updating the change points based on either a maximum likelihood-based approach or a change point detection algorithm using the sequential likelihood ratio test. We provide a theoretical analysis of this proposed change point detection scheme. Finally, we present an empirical evaluation that demonstrates the expressive power of our proposed model, showing that it can effectively model both classical parametric SDEs and some real datasets with distribution shifts.
A Language Model-Guided Framework for Mining Time Series with Distributional Shifts
Jun 07, 2024Effective utilization of time series data is often constrained by the scarcity of data quantity that reflects complex dynamics, especially under the condition of distributional shifts. Existing datasets may not encompass the full range of statistical properties required for robust and comprehensive analysis. And privacy concerns can further limit their accessibility in domains such as finance and healthcare. This paper presents an approach that utilizes large language models and data source interfaces to explore and collect time series datasets. While obtained from external sources, the collected data share critical statistical properties with primary time series datasets, making it possible to model and adapt to various scenarios. This method enlarges the data quantity when the original data is limited or lacks essential properties. It suggests that collected datasets can effectively supplement existing datasets, especially involving changes in data distribution. We demonstrate the effectiveness of the collected datasets through practical examples and show how time series forecasting foundation models fine-tuned on these datasets achieve comparable performance to those models without fine-tuning.
Comprehensive evaluation of Mal-API-2019 dataset by machine learning in malware detection
Mar 04, 2024
This study conducts a thorough examination of malware detection using machine learning techniques, focusing on the evaluation of various classification models using the Mal-API-2019 dataset. The aim is to advance cybersecurity capabilities by identifying and mitigating threats more effectively. Both ensemble and non-ensemble machine learning methods, such as Random Forest, XGBoost, K Nearest Neighbor (KNN), and Neural Networks, are explored. Special emphasis is placed on the importance of data pre-processing techniques, particularly TF-IDF representation and Principal Component Analysis, in improving model performance. Results indicate that ensemble methods, particularly Random Forest and XGBoost, exhibit superior accuracy, precision, and recall compared to others, highlighting their effectiveness in malware detection. The paper also discusses limitations and potential future directions, emphasizing the need for continuous adaptation to address the evolving nature of malware. This research contributes to ongoing discussions in cybersecurity and provides practical insights for developing more robust malware detection systems in the digital era.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.