 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning
Paper and Code
Dec 08, 2020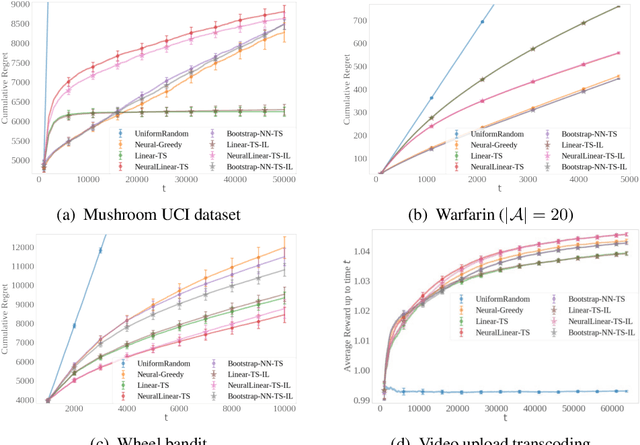
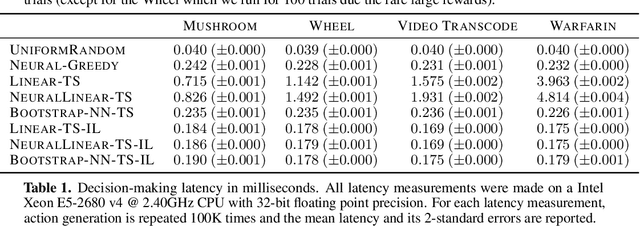
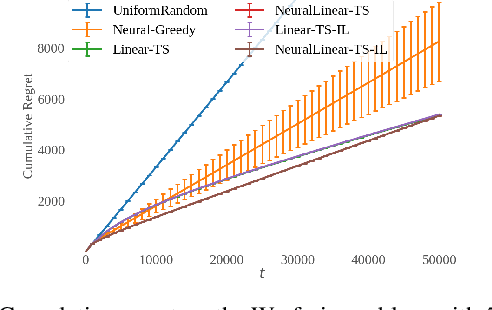

Thompson sampling (TS) has emerged as a robust technique for contextual bandit problems. However, TS requires posterior inference and optimization for action generation, prohibiting its use in many internet applications where latency and ease of deployment are of concern. We propose a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation by performing posterior inference and optimization offline. The explicit policy representation enables fast online decision-making and easy deployment in mobile and server-based environments. Our algorithm iteratively performs offline batch updates to the TS policy and learns a new imitation policy. Since we update the TS policy with observations collected under the imitation policy, our algorithm emulates an off-policy version of TS. Our imitation algorithm guarantees Bayes regret comparable to TS, up to the sum of single-step imitation errors. We show these imitation errors can be made arbitrarily small when unlabeled contexts are cheaply available, which is the case for most large-scale internet applications. Empirically, we show that our imitation policy achieves comparable regret to TS, while reducing decision-time latency by over an order of magnitude.