 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating structured assumptions with probabilistic graphical models in fMRI data analysis
Paper and Code
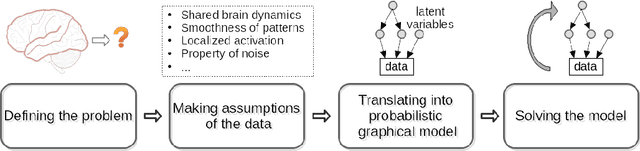
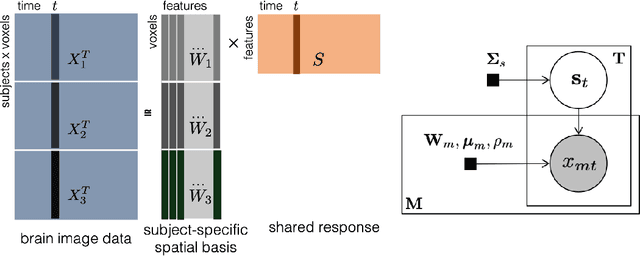
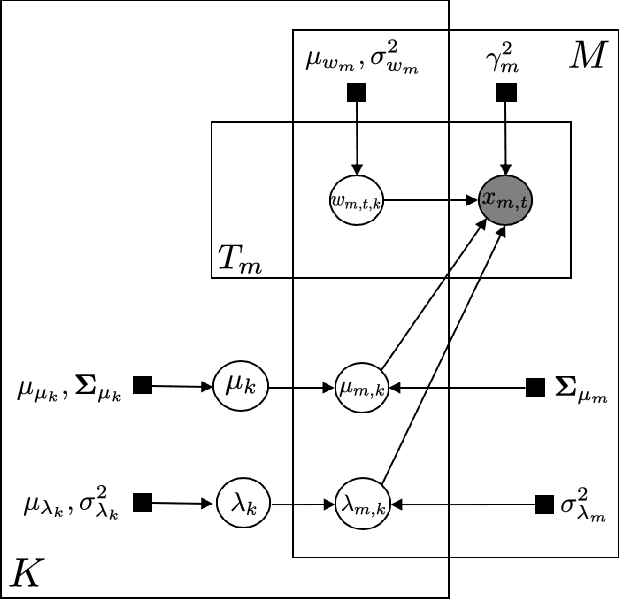
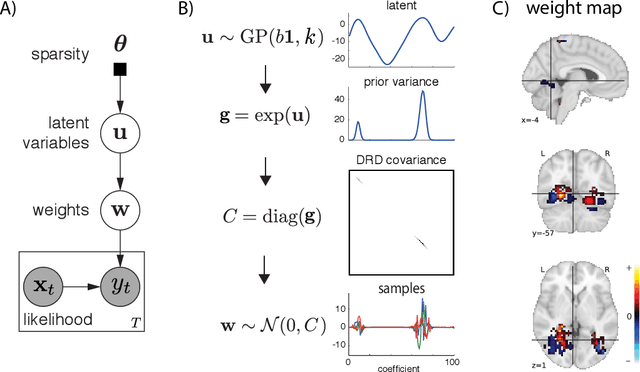
With the wide adoption of functional magnetic resonance imaging (fMRI) by cognitive neuroscience researchers, large volumes of brain imaging data have been accumulated in recent years. Aggregating these data to derive scientific insights often faces the challenge that fMRI data are high-dimensional, heterogeneous across people, and noisy. These challenges demand the development of computational tools that are tailored both for the neuroscience questions and for the properties of the data. We review a few recently developed algorithms in various domains of fMRI research: fMRI in naturalistic tasks, analyzing full-brain functional connectivity, pattern classification, inferring representational similarity and modeling structured residuals. These algorithms all tackle the challenges in fMRI similarly: they start by making clear statements of assumptions about neural data and existing domain knowledge, incorporating those assumptions and domain knowledge into probabilistic graphical models, and using those models to estimate properties of interest or latent structures in the data. Such approaches can avoid erroneous findings, reduce the impact of noise, better utilize known properties of the data, and better aggregate data across groups of subjects. With these successful cases, we advocate wider adoption of explicit model construction in cognitive neuroscience. Although we focus on fMRI, the principle illustrated here is generally applicable to brain data of other modalities.