 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOryx: a Performant and Scalable Algorithm for Many-Agent Coordination in Offline MARL
May 28, 2025A key challenge in offline multi-agent reinforcement learning (MARL) is achieving effective many-agent multi-step coordination in complex environments. In this work, we propose Oryx, a novel algorithm for offline cooperative MARL to directly address this challenge. Oryx adapts the recently proposed retention-based architecture Sable and combines it with a sequential form of implicit constraint Q-learning (ICQ), to develop a novel offline auto-regressive policy update scheme. This allows Oryx to solve complex coordination challenges while maintaining temporal coherence over lengthy trajectories. We evaluate Oryx across a diverse set of benchmarks from prior works (SMAC, RWARE, and Multi-Agent MuJoCo) covering tasks of both discrete and continuous control, varying in scale and difficulty. Oryx achieves state-of-the-art performance on more than 80% of the 65 tested datasets, outperforming prior offline MARL methods and demonstrating robust generalisation across domains with many agents and long horizons. Finally, we introduce new datasets to push the limits of many-agent coordination in offline MARL, and demonstrate Oryx's superior ability to scale effectively in such settings. We will make all of our datasets, experimental data, and code available upon publication.
Breaking the Performance Ceiling in Complex Reinforcement Learning requires Inference Strategies
May 27, 2025Reinforcement learning (RL) systems have countless applications, from energy-grid management to protein design. However, such real-world scenarios are often extremely difficult, combinatorial in nature, and require complex coordination between multiple agents. This level of complexity can cause even state-of-the-art RL systems, trained until convergence, to hit a performance ceiling which they are unable to break out of with zero-shot inference. Meanwhile, many digital or simulation-based applications allow for an inference phase that utilises a specific time and compute budget to explore multiple attempts before outputting a final solution. In this work, we show that such an inference phase employed at execution time, and the choice of a corresponding inference strategy, are key to breaking the performance ceiling observed in complex multi-agent RL problems. Our main result is striking: we can obtain up to a 126% and, on average, a 45% improvement over the previous state-of-the-art across 17 tasks, using only a couple seconds of extra wall-clock time during execution. We also demonstrate promising compute scaling properties, supported by over 60k experiments, making it the largest study on inference strategies for complex RL to date. Our experimental data and code are available at https://sites.google.com/view/inf-marl.
SMX: Sequential Monte Carlo Planning for Expert Iteration
Feb 12, 2024Developing agents that can leverage planning abilities during their decision and learning processes is critical to the advancement of Artificial Intelligence. Recent works have demonstrated the effectiveness of combining tree-based search methods and self-play learning mechanisms. Yet, these methods typically face scaling challenges due to the sequential nature of their search. While practical engineering solutions can partly overcome this, they still demand extensive computational resources, which hinders their applicability. In this paper, we introduce SMX, a model-based planning algorithm that utilises scalable Sequential Monte Carlo methods to create an effective self-learning mechanism. Grounded in the theoretical framework of control as inference, SMX benefits from robust theoretical underpinnings. Its sampling-based search approach makes it adaptable to environments with both discrete and continuous action spaces. Furthermore, SMX allows for high parallelisation and can run on hardware accelerators to optimise computing efficiency. SMX demonstrates a statistically significant improvement in performance compared to AlphaZero, as well as demonstrating its performance as an improvement operator for a model-free policy, matching or exceeding top model-free methods across both continuous and discrete environments.
Efficiently Quantifying Individual Agent Importance in Cooperative MARL
Dec 13, 2023Measuring the contribution of individual agents is challenging in cooperative multi-agent reinforcement learning (MARL). In cooperative MARL, team performance is typically inferred from a single shared global reward. Arguably, among the best current approaches to effectively measure individual agent contributions is to use Shapley values. However, calculating these values is expensive as the computational complexity grows exponentially with respect to the number of agents. In this paper, we adapt difference rewards into an efficient method for quantifying the contribution of individual agents, referred to as Agent Importance, offering a linear computational complexity relative to the number of agents. We show empirically that the computed values are strongly correlated with the true Shapley values, as well as the true underlying individual agent rewards, used as the ground truth in environments where these are available. We demonstrate how Agent Importance can be used to help study MARL systems by diagnosing algorithmic failures discovered in prior MARL benchmarking work. Our analysis illustrates Agent Importance as a valuable explainability component for future MARL benchmarks.
How much can change in a year? Revisiting Evaluation in Multi-Agent Reinforcement Learning
Dec 13, 2023Establishing sound experimental standards and rigour is important in any growing field of research. Deep Multi-Agent Reinforcement Learning (MARL) is one such nascent field. Although exciting progress has been made, MARL has recently come under scrutiny for replicability issues and a lack of standardised evaluation methodology, specifically in the cooperative setting. Although protocols have been proposed to help alleviate the issue, it remains important to actively monitor the health of the field. In this work, we extend the database of evaluation methodology previously published by containing meta-data on MARL publications from top-rated conferences and compare the findings extracted from this updated database to the trends identified in their work. Our analysis shows that many of the worrying trends in performance reporting remain. This includes the omission of uncertainty quantification, not reporting all relevant evaluation details and a narrowing of algorithmic development classes. Promisingly, we do observe a trend towards more difficult scenarios in SMAC-v1, which if continued into SMAC-v2 will encourage novel algorithmic development. Our data indicate that replicability needs to be approached more proactively by the MARL community to ensure trust in the field as we move towards exciting new frontiers.
On Diagnostics for Understanding Agent Training Behaviour in Cooperative MARL
Dec 13, 2023



Cooperative multi-agent reinforcement learning (MARL) has made substantial strides in addressing the distributed decision-making challenges. However, as multi-agent systems grow in complexity, gaining a comprehensive understanding of their behaviour becomes increasingly challenging. Conventionally, tracking team rewards over time has served as a pragmatic measure to gauge the effectiveness of agents in learning optimal policies. Nevertheless, we argue that relying solely on the empirical returns may obscure crucial insights into agent behaviour. In this paper, we explore the application of explainable AI (XAI) tools to gain profound insights into agent behaviour. We employ these diagnostics tools within the context of Level-Based Foraging and Multi-Robot Warehouse environments and apply them to a diverse array of MARL algorithms. We demonstrate how our diagnostics can enhance the interpretability and explainability of MARL systems, providing a better understanding of agent behaviour.
The challenge of redundancy on multi-agent value factorisation
Mar 28, 2023In the field of cooperative multi-agent reinforcement learning (MARL), the standard paradigm is the use of centralised training and decentralised execution where a central critic conditions the policies of the cooperative agents based on a central state. It has been shown, that in cases with large numbers of redundant agents these methods become less effective. In a more general case, there is likely to be a larger number of agents in an environment than is required to solve the task. These redundant agents reduce performance by enlarging the dimensionality of both the state space and and increasing the size of the joint policy used to solve the environment. We propose leveraging layerwise relevance propagation (LRP) to instead separate the learning of the joint value function and generation of local reward signals and create a new MARL algorithm: relevance decomposition network (RDN). We find that although the performance of both baselines VDN and Qmix degrades with the number of redundant agents, RDN is unaffected.
Towards a Standardised Performance Evaluation Protocol for Cooperative MARL
Sep 21, 2022

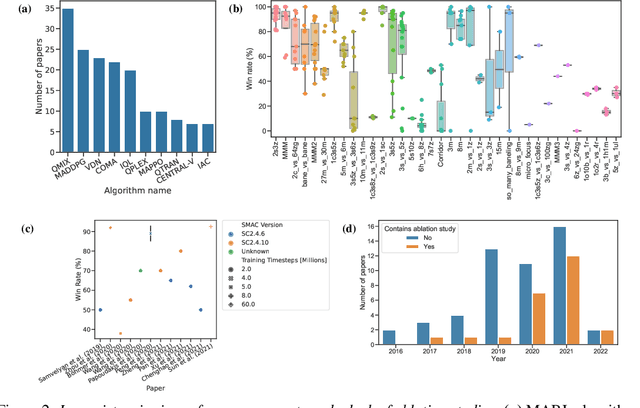

Multi-agent reinforcement learning (MARL) has emerged as a useful approach to solving decentralised decision-making problems at scale. Research in the field has been growing steadily with many breakthrough algorithms proposed in recent years. In this work, we take a closer look at this rapid development with a focus on evaluation methodologies employed across a large body of research in cooperative MARL. By conducting a detailed meta-analysis of prior work, spanning 75 papers accepted for publication from 2016 to 2022, we bring to light worrying trends that put into question the true rate of progress. We further consider these trends in a wider context and take inspiration from single-agent RL literature on similar issues with recommendations that remain applicable to MARL. Combining these recommendations, with novel insights from our analysis, we propose a standardised performance evaluation protocol for cooperative MARL. We argue that such a standard protocol, if widely adopted, would greatly improve the validity and credibility of future research, make replication and reproducibility easier, as well as improve the ability of the field to accurately gauge the rate of progress over time by being able to make sound comparisons across different works. Finally, we release our meta-analysis data publicly on our project website for future research on evaluation: https://sites.google.com/view/marl-standard-protocol