 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Diagnostics for Understanding Agent Training Behaviour in Cooperative MARL
Dec 13, 2023



Cooperative multi-agent reinforcement learning (MARL) has made substantial strides in addressing the distributed decision-making challenges. However, as multi-agent systems grow in complexity, gaining a comprehensive understanding of their behaviour becomes increasingly challenging. Conventionally, tracking team rewards over time has served as a pragmatic measure to gauge the effectiveness of agents in learning optimal policies. Nevertheless, we argue that relying solely on the empirical returns may obscure crucial insights into agent behaviour. In this paper, we explore the application of explainable AI (XAI) tools to gain profound insights into agent behaviour. We employ these diagnostics tools within the context of Level-Based Foraging and Multi-Robot Warehouse environments and apply them to a diverse array of MARL algorithms. We demonstrate how our diagnostics can enhance the interpretability and explainability of MARL systems, providing a better understanding of agent behaviour.
Towards a Standardised Performance Evaluation Protocol for Cooperative MARL
Sep 21, 2022

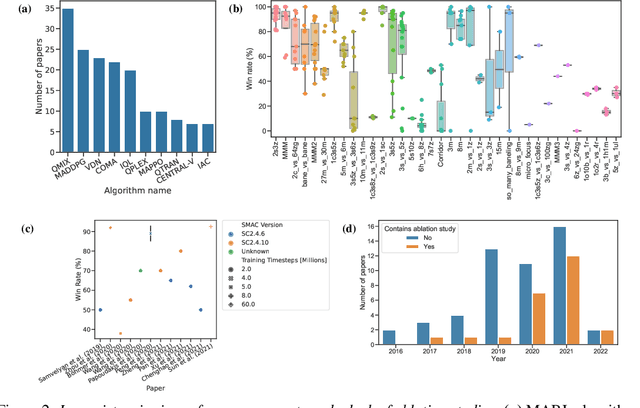

Multi-agent reinforcement learning (MARL) has emerged as a useful approach to solving decentralised decision-making problems at scale. Research in the field has been growing steadily with many breakthrough algorithms proposed in recent years. In this work, we take a closer look at this rapid development with a focus on evaluation methodologies employed across a large body of research in cooperative MARL. By conducting a detailed meta-analysis of prior work, spanning 75 papers accepted for publication from 2016 to 2022, we bring to light worrying trends that put into question the true rate of progress. We further consider these trends in a wider context and take inspiration from single-agent RL literature on similar issues with recommendations that remain applicable to MARL. Combining these recommendations, with novel insights from our analysis, we propose a standardised performance evaluation protocol for cooperative MARL. We argue that such a standard protocol, if widely adopted, would greatly improve the validity and credibility of future research, make replication and reproducibility easier, as well as improve the ability of the field to accurately gauge the rate of progress over time by being able to make sound comparisons across different works. Finally, we release our meta-analysis data publicly on our project website for future research on evaluation: https://sites.google.com/view/marl-standard-protocol