 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Multimodal Model Architectures
May 28, 2024
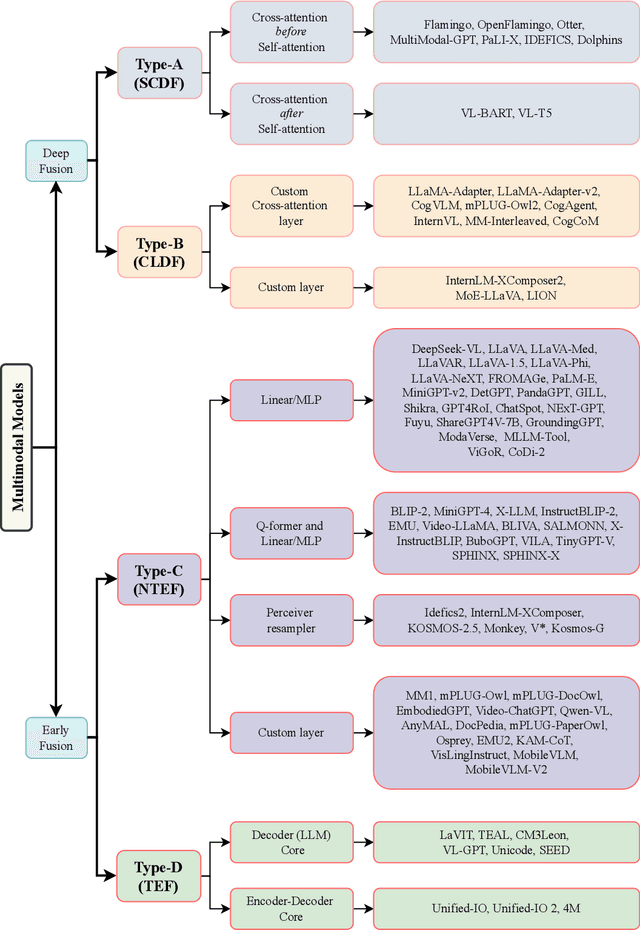
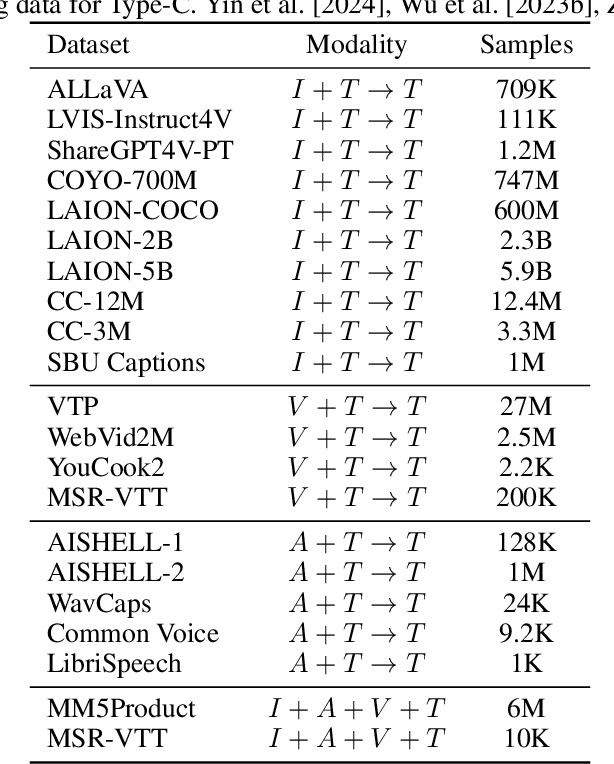
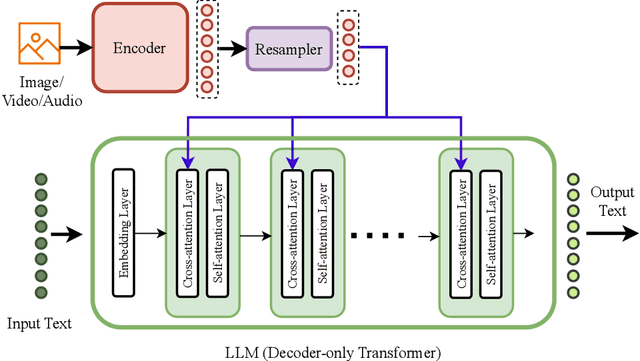
This work uniquely identifies and characterizes four prevalent multimodal model architectural patterns in the contemporary multimodal landscape. Systematically categorizing models by architecture type facilitates monitoring of developments in the multimodal domain. Distinct from recent survey papers that present general information on multimodal architectures, this research conducts a comprehensive exploration of architectural details and identifies four specific architectural types. The types are distinguished by their respective methodologies for integrating multimodal inputs into the deep neural network model. The first two types (Type A and B) deeply fuses multimodal inputs within the internal layers of the model, whereas the following two types (Type C and D) facilitate early fusion at the input stage. Type-A employs standard cross-attention, whereas Type-B utilizes custom-designed layers for modality fusion within the internal layers. On the other hand, Type-C utilizes modality-specific encoders, while Type-D leverages tokenizers to process the modalities at the model's input stage. The identified architecture types aid the monitoring of any-to-any multimodal model development. Notably, Type-C and Type-D are currently favored in the construction of any-to-any multimodal models. Type-C, distinguished by its non-tokenizing multimodal model architecture, is emerging as a viable alternative to Type-D, which utilizes input-tokenizing techniques. To assist in model selection, this work highlights the advantages and disadvantages of each architecture type based on data and compute requirements, architecture complexity, scalability, simplification of adding modalities, training objectives, and any-to-any multimodal generation capability.
OneCAD: One Classifier for All image Datasets using multimodal learning
May 11, 2023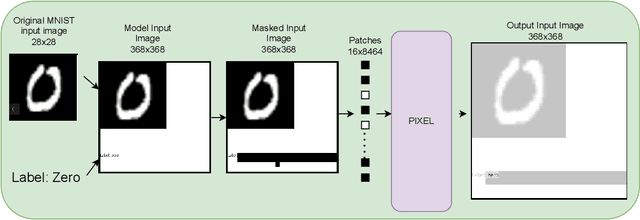

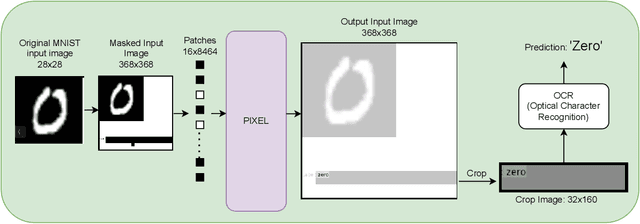

Vision-Transformers (ViTs) and Convolutional neural networks (CNNs) are widely used Deep Neural Networks (DNNs) for classification task. These model architectures are dependent on the number of classes in the dataset it was trained on. Any change in number of classes leads to change (partial or full) in the model's architecture. This work addresses the question: Is it possible to create a number-of-class-agnostic model architecture?. This allows model's architecture to be independent of the dataset it is trained on. This work highlights the issues with the current architectures (ViTs and CNNs). Also, proposes a training and inference framework OneCAD (One Classifier for All image Datasets) to achieve close-to number-of-class-agnostic transformer model. To best of our knowledge this is the first work to use Mask-Image-Modeling (MIM) with multimodal learning for classification task to create a DNN model architecture agnostic to the number of classes. Preliminary results are shown on natural and medical image datasets. Datasets: MNIST, CIFAR10, CIFAR100 and COVIDx. Code will soon be publicly available on github.
Reinforcement Learning Approach for Mapping Applications to Dataflow-Based Coarse-Grained Reconfigurable Array
May 26, 2022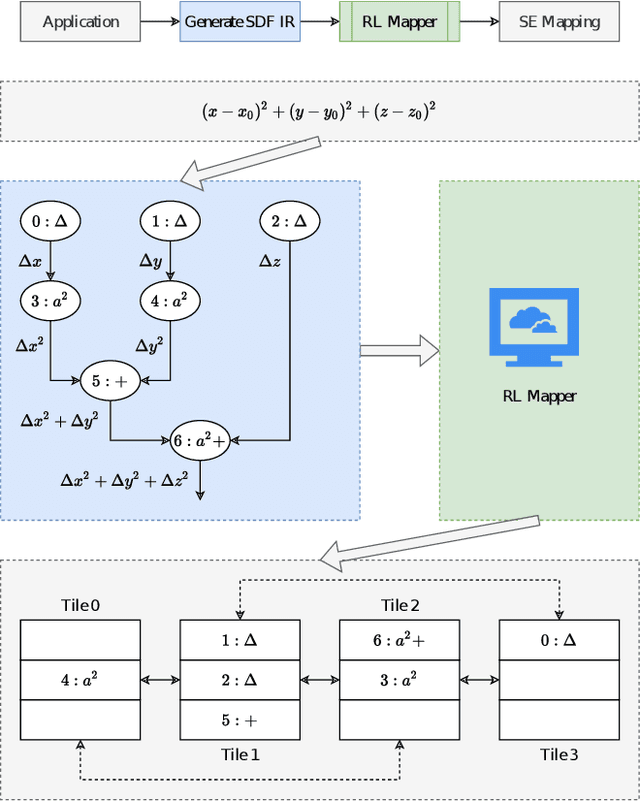
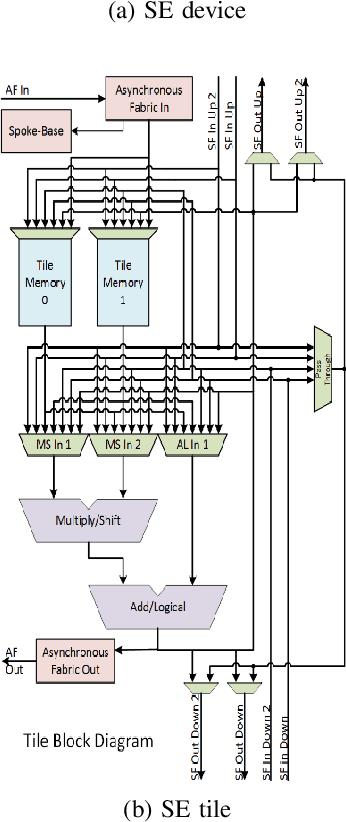
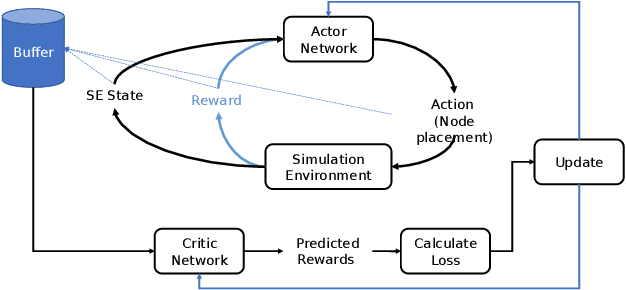
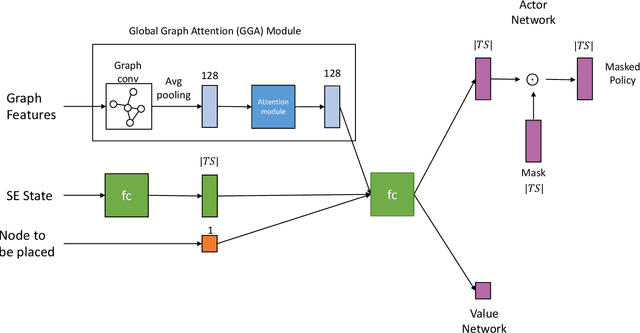
The Streaming Engine (SE) is a Coarse-Grained Reconfigurable Array which provides programming flexibility and high-performance with energy efficiency. An application program to be executed on the SE is represented as a combination of Synchronous Data Flow (SDF) graphs, where every instruction is represented as a node. Each node needs to be mapped to the right slot and array in the SE to ensure the correct execution of the program. This creates an optimization problem with a vast and sparse search space for which finding a mapping manually is impractical because it requires expertise and knowledge of the SE micro-architecture. In this work we propose a Reinforcement Learning framework with Global Graph Attention (GGA) module and output masking of invalid placements to find and optimize instruction schedules. We use Proximal Policy Optimization in order to train a model which places operations into the SE tiles based on a reward function that models the SE device and its constraints. The GGA module consists of a graph neural network and an attention module. The graph neural network creates embeddings of the SDFs and the attention block is used to model sequential operation placement. We show results on how certain workloads are mapped to the SE and the factors affecting mapping quality. We find that the addition of GGA, on average, finds 10% better instruction schedules in terms of total clock cycles taken and masking improves reward obtained by 20%.
Capsule Network Performance with Autonomous Navigation
Feb 08, 2020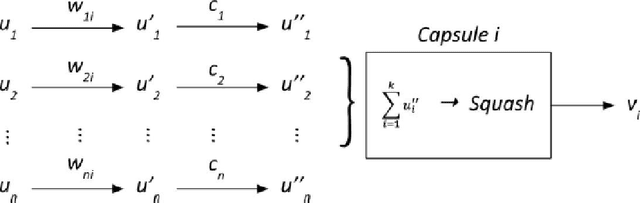


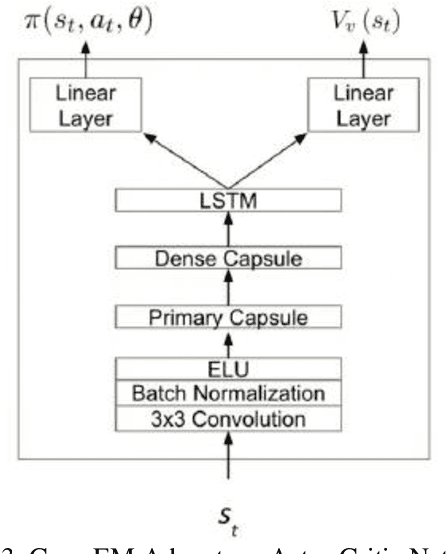
Capsule Networks (CapsNets) have been proposed as an alternative to Convolutional Neural Networks (CNNs). This paper showcases how CapsNets are more capable than CNNs for autonomous agent exploration of realistic scenarios. In real world navigation, rewards external to agents may be rare. In turn, reinforcement learning algorithms can struggle to form meaningful policy functions. This paper's approach Capsules Exploration Module (Caps-EM) pairs a CapsNets architecture with an Advantage Actor Critic algorithm. Other approaches for navigating sparse environments require intrinsic reward generators, such as the Intrinsic Curiosity Module (ICM) and Augmented Curiosity Modules (ACM). Caps-EM uses a more compact architecture without need for intrinsic rewards. Tested using ViZDoom, the Caps-EM uses 44% and 83% fewer trainable network parameters than the ICM and Depth-Augmented Curiosity Module (D-ACM), respectively, for 1141% and 437% average time improvement over the ICM and D-ACM, respectively, for converging to a policy function across "My Way Home" scenarios.
* In IJAIA Vol.11, No.1 for January 2020; 15 pages, 9 figures
Continual Reinforcement Learning in 3D Non-stationary Environments
May 24, 2019
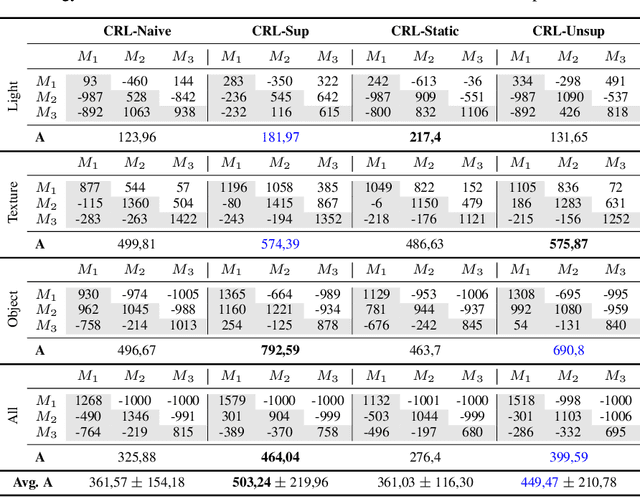

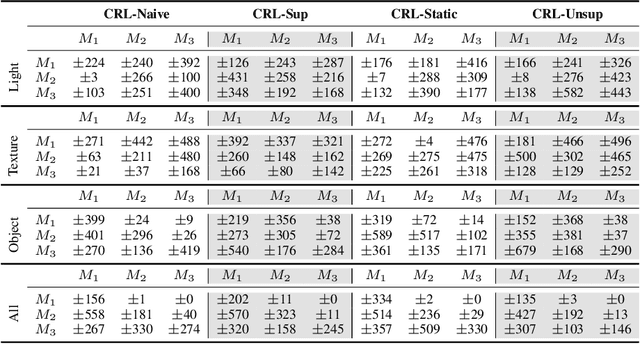
High-dimensional always-changing environments constitute a hard challenge for current reinforcement learning techniques. Artificial agents, nowadays, are often trained off-line in very static and controlled conditions in simulation such that training observations can be thought as sampled i.i.d. from the entire observations space. However, in real world settings, the environment is often non-stationary and subject to unpredictable, frequent changes. In this paper we propose and openly release CRLMaze, a new benchmark for learning continually through reinforcement in a complex 3D non-stationary task based on ViZDoom and subject to several environmental changes. Then, we introduce an end-to-end model-free continual reinforcement learning strategy showing competitive results with respect to four different baselines and not requiring any access to additional supervised signals, previously encountered environmental conditions or observations.
Deep Predictive Coding Network with Local Recurrent Processing for Object Recognition
Oct 26, 2018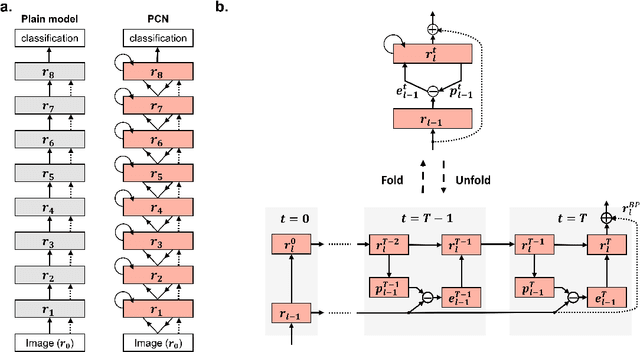
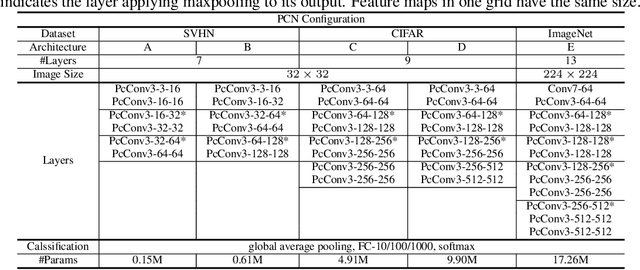
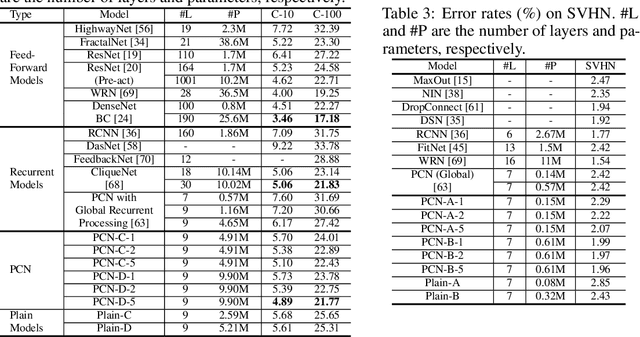
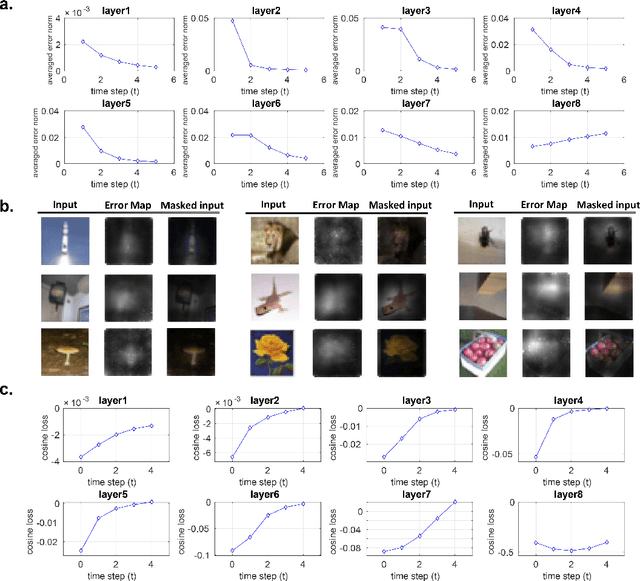
Inspired by "predictive coding" - a theory in neuroscience, we develop a bi-directional and dynamic neural network with local recurrent processing, namely predictive coding network (PCN). Unlike feedforward-only convolutional neural networks, PCN includes both feedback connections, which carry top-down predictions, and feedforward connections, which carry bottom-up errors of prediction. Feedback and feedforward connections enable adjacent layers to interact locally and recurrently to refine representations towards minimization of layer-wise prediction errors. When unfolded over time, the recurrent processing gives rise to an increasingly deeper hierarchy of non-linear transformation, allowing a shallow network to dynamically extend itself into an arbitrarily deep network. We train and test PCN for image classification with SVHN, CIFAR and ImageNet datasets. Despite notably fewer layers and parameters, PCN achieves competitive performance compared to classical and state-of-the-art models. Further analysis shows that the internal representations in PCN converge over time and yield increasingly better accuracy in object recognition. Errors of top-down prediction also reveal visual saliency or bottom-up attention.
Deep Predictive Coding Network for Object Recognition
Jul 29, 2018
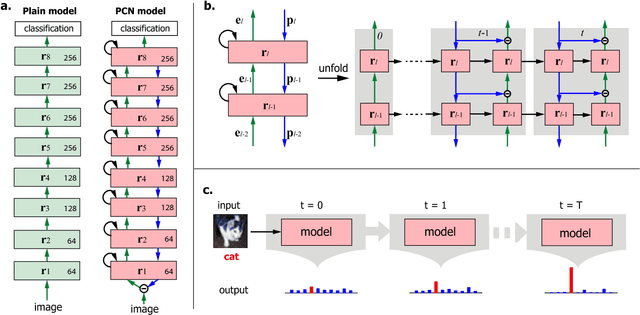
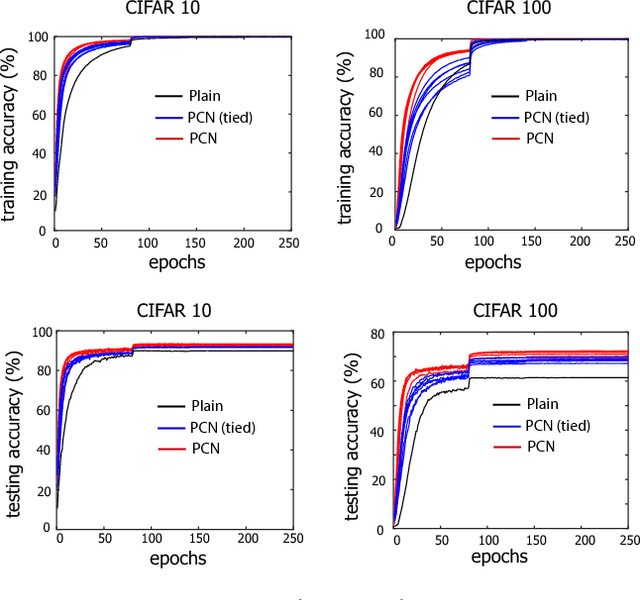
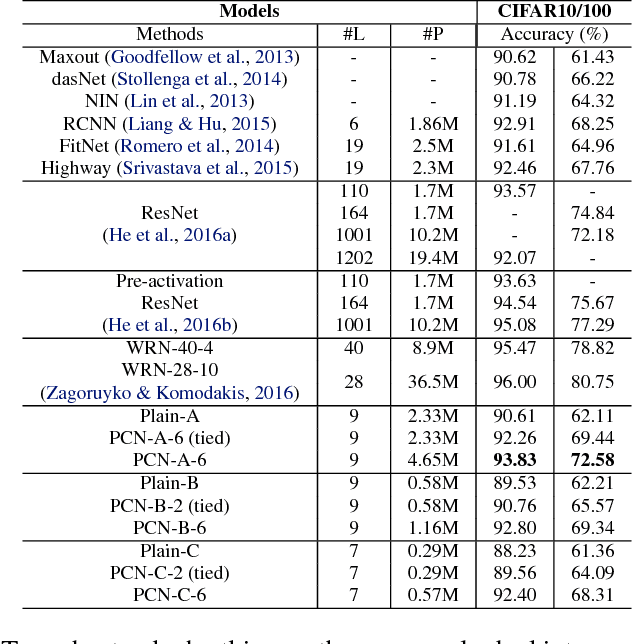
Based on the predictive coding theory in neuroscience, we designed a bi-directional and recurrent neural net, namely deep predictive coding networks (PCN). It has feedforward, feedback, and recurrent connections. Feedback connections from a higher layer carry the prediction of its lower-layer representation; feedforward connections carry the prediction errors to its higher-layer. Given image input, PCN runs recursive cycles of bottom-up and top-down computation to update its internal representations and reduce the difference between bottom-up input and top-down prediction at every layer. After multiple cycles of recursive updating, the representation is used for image classification. With benchmark data (CIFAR-10/100, SVHN, and MNIST), PCN was found to always outperform its feedforward-only counterpart: a model without any mechanism for recurrent dynamics. Its performance tended to improve given more cycles of computation over time. In short, PCN reuses a single architecture to recursively run bottom-up and top-down processes. As a dynamical system, PCN can be unfolded to a feedforward model that becomes deeper and deeper over time, while refining it representation towards more accurate and definitive object recognition.
Compiling Deep Learning Models for Custom Hardware Accelerators
Dec 10, 2017
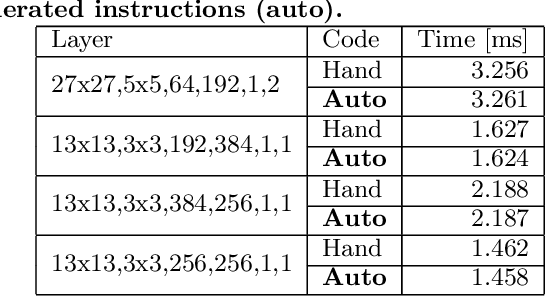

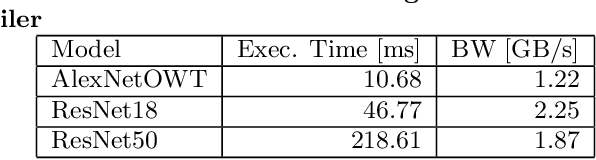
Convolutional neural networks (CNNs) are the core of most state-of-the-art deep learning algorithms specialized for object detection and classification. CNNs are both computationally complex and embarrassingly parallel. Two properties that leave room for potential software and hardware optimizations for embedded systems. Given a programmable hardware accelerator with a CNN oriented custom instructions set, the compiler's task is to exploit the hardware's full potential, while abiding with the hardware constraints and maintaining generality to run different CNN models with varying workload properties. Snowflake is an efficient and scalable hardware accelerator implemented on programmable logic devices. It implements a control pipeline for a custom instruction set. The goal of this paper is to present Snowflake's compiler that generates machine level instructions from Torch7 model description files. The main software design points explored in this work are: model structure parsing, CNN workload breakdown, loop rearrangement for memory bandwidth optimizations and memory access balancing. The performance achieved by compiler generated instructions matches against hand optimized code for convolution layers. Generated instructions also efficiently execute AlexNet and ResNet18 inference on Snowflake. Snowflake with $256$ processing units was synthesized on Xilinx's Zynq XC7Z045 FPGA. At $250$ MHz, AlexNet achieved in $93.6$ frames/s and $1.2$ GB/s of off-chip memory bandwidth, and $21.4$ frames/s and $2.2$ GB/s for ResNet18. Total on-chip power is $5$ W.
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
Jun 14, 2017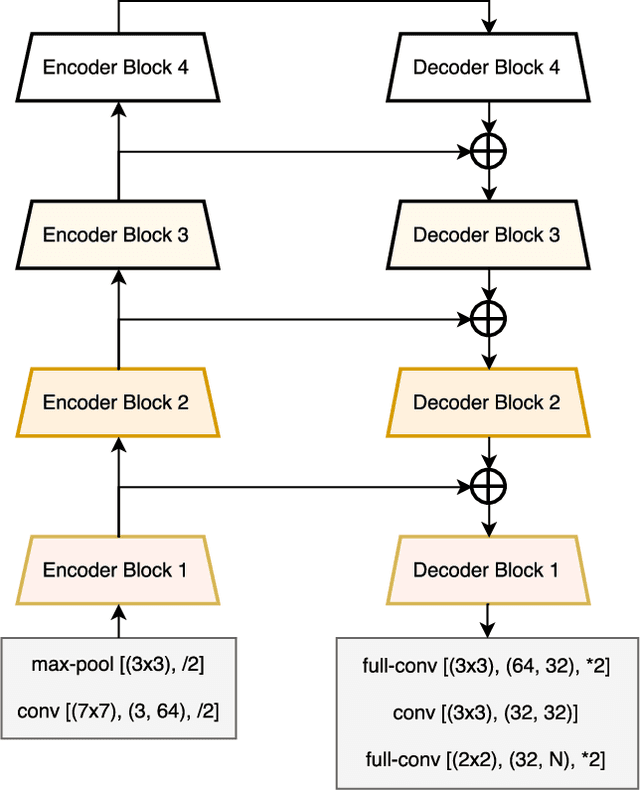
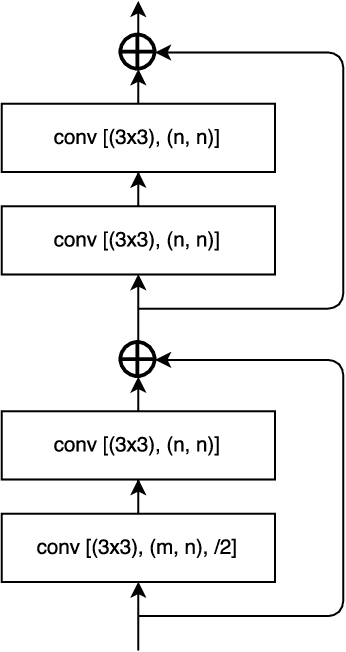
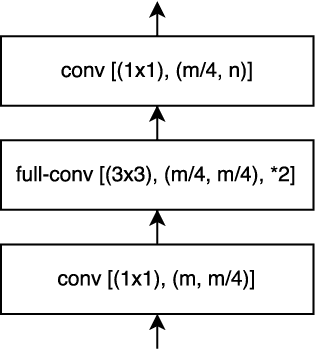
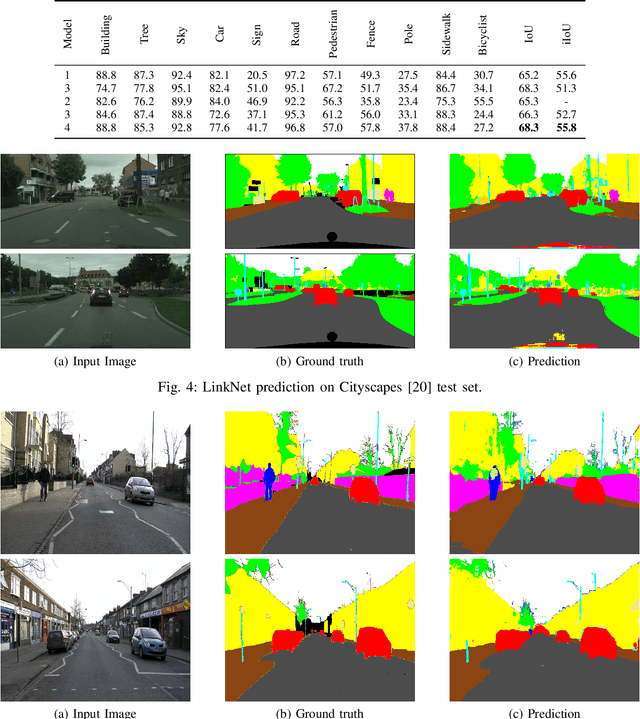
Pixel-wise semantic segmentation for visual scene understanding not only needs to be accurate, but also efficient in order to find any use in real-time application. Existing algorithms even though are accurate but they do not focus on utilizing the parameters of neural network efficiently. As a result they are huge in terms of parameters and number of operations; hence slow too. In this paper, we propose a novel deep neural network architecture which allows it to learn without any significant increase in number of parameters. Our network uses only 11.5 million parameters and 21.2 GFLOPs for processing an image of resolution 3x640x360. It gives state-of-the-art performance on CamVid and comparable results on Cityscapes dataset. We also compare our networks processing time on NVIDIA GPU and embedded system device with existing state-of-the-art architectures for different image resolutions.
CortexNet: a Generic Network Family for Robust Visual Temporal Representations
Jun 14, 2017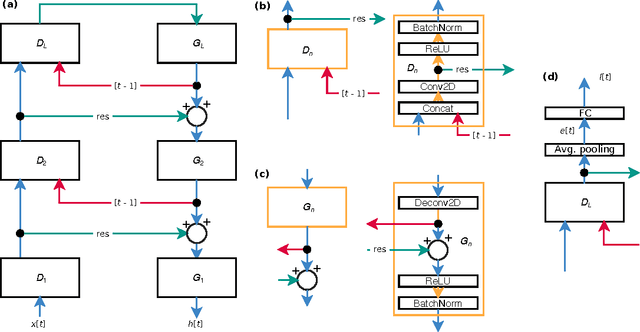
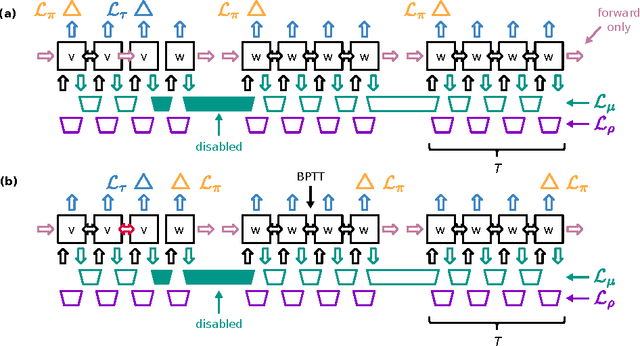
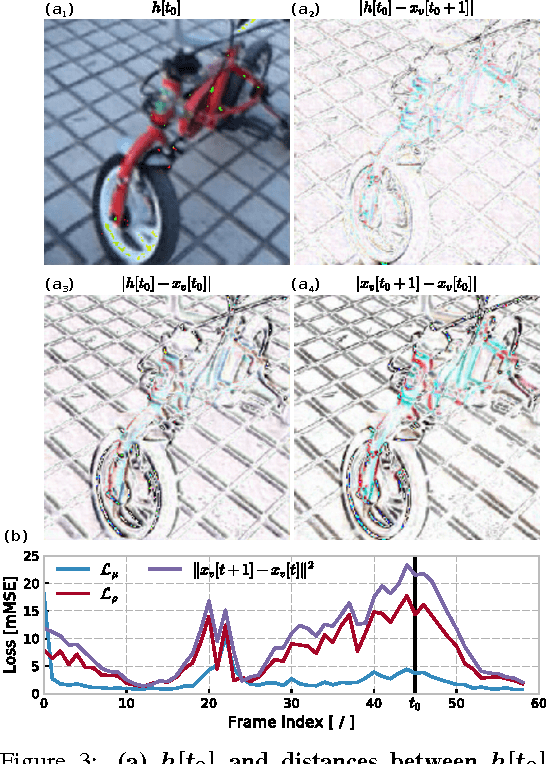
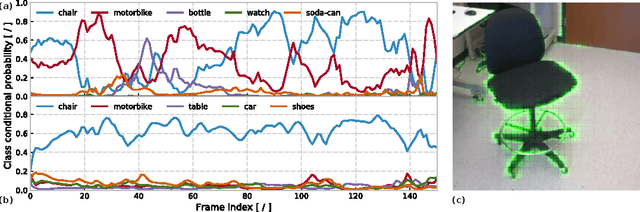
In the past five years we have observed the rise of incredibly well performing feed-forward neural networks trained supervisedly for vision related tasks. These models have achieved super-human performance on object recognition, localisation, and detection in still images. However, there is a need to identify the best strategy to employ these networks with temporal visual inputs and obtain a robust and stable representation of video data. Inspired by the human visual system, we propose a deep neural network family, CortexNet, which features not only bottom-up feed-forward connections, but also it models the abundant top-down feedback and lateral connections, which are present in our visual cortex. We introduce two training schemes - the unsupervised MatchNet and weakly supervised TempoNet modes - where a network learns how to correctly anticipate a subsequent frame in a video clip or the identity of its predominant subject, by learning egomotion clues and how to automatically track several objects in the current scene. Find the project website at https://engineering.purdue.edu/elab/CortexNet/.