 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Approach for Mapping Applications to Dataflow-Based Coarse-Grained Reconfigurable Array
May 26, 2022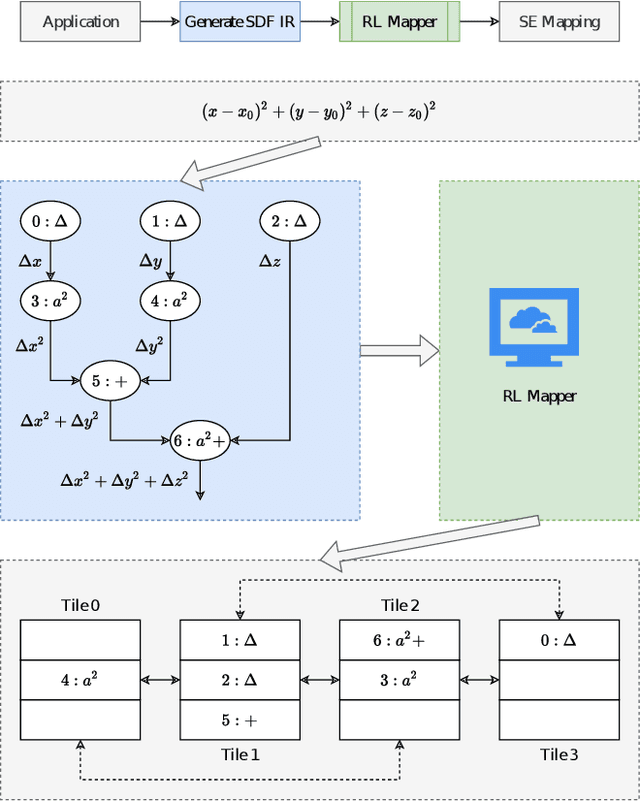
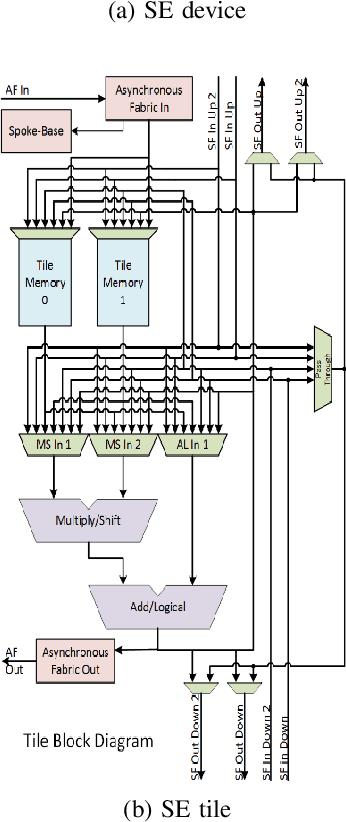
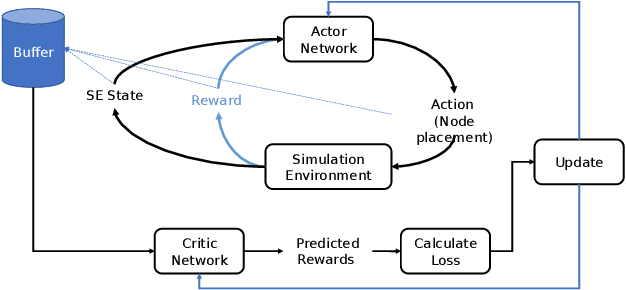
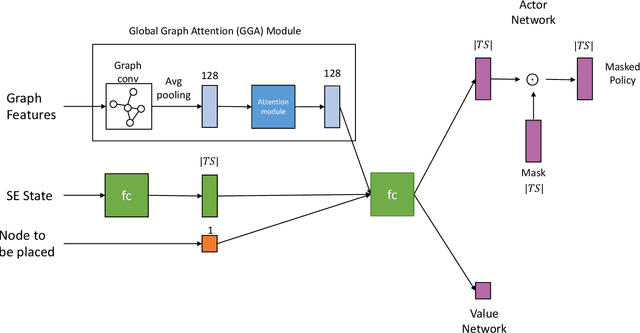
The Streaming Engine (SE) is a Coarse-Grained Reconfigurable Array which provides programming flexibility and high-performance with energy efficiency. An application program to be executed on the SE is represented as a combination of Synchronous Data Flow (SDF) graphs, where every instruction is represented as a node. Each node needs to be mapped to the right slot and array in the SE to ensure the correct execution of the program. This creates an optimization problem with a vast and sparse search space for which finding a mapping manually is impractical because it requires expertise and knowledge of the SE micro-architecture. In this work we propose a Reinforcement Learning framework with Global Graph Attention (GGA) module and output masking of invalid placements to find and optimize instruction schedules. We use Proximal Policy Optimization in order to train a model which places operations into the SE tiles based on a reward function that models the SE device and its constraints. The GGA module consists of a graph neural network and an attention module. The graph neural network creates embeddings of the SDFs and the attention block is used to model sequential operation placement. We show results on how certain workloads are mapped to the SE and the factors affecting mapping quality. We find that the addition of GGA, on average, finds 10% better instruction schedules in terms of total clock cycles taken and masking improves reward obtained by 20%.
Compiling Deep Learning Models for Custom Hardware Accelerators
Dec 10, 2017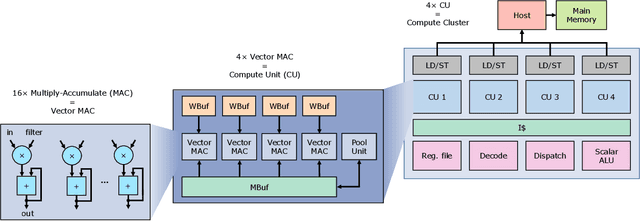
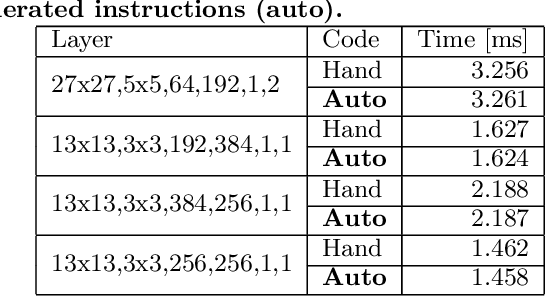

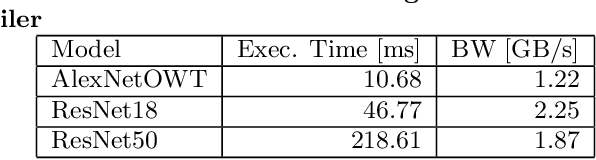
Convolutional neural networks (CNNs) are the core of most state-of-the-art deep learning algorithms specialized for object detection and classification. CNNs are both computationally complex and embarrassingly parallel. Two properties that leave room for potential software and hardware optimizations for embedded systems. Given a programmable hardware accelerator with a CNN oriented custom instructions set, the compiler's task is to exploit the hardware's full potential, while abiding with the hardware constraints and maintaining generality to run different CNN models with varying workload properties. Snowflake is an efficient and scalable hardware accelerator implemented on programmable logic devices. It implements a control pipeline for a custom instruction set. The goal of this paper is to present Snowflake's compiler that generates machine level instructions from Torch7 model description files. The main software design points explored in this work are: model structure parsing, CNN workload breakdown, loop rearrangement for memory bandwidth optimizations and memory access balancing. The performance achieved by compiler generated instructions matches against hand optimized code for convolution layers. Generated instructions also efficiently execute AlexNet and ResNet18 inference on Snowflake. Snowflake with $256$ processing units was synthesized on Xilinx's Zynq XC7Z045 FPGA. At $250$ MHz, AlexNet achieved in $93.6$ frames/s and $1.2$ GB/s of off-chip memory bandwidth, and $21.4$ frames/s and $2.2$ GB/s for ResNet18. Total on-chip power is $5$ W.
Recurrent Neural Networks Hardware Implementation on FPGA
Mar 04, 2016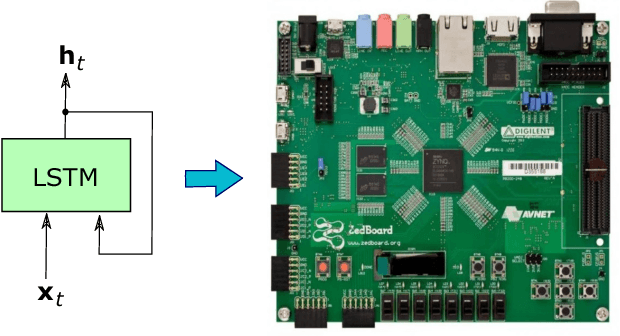
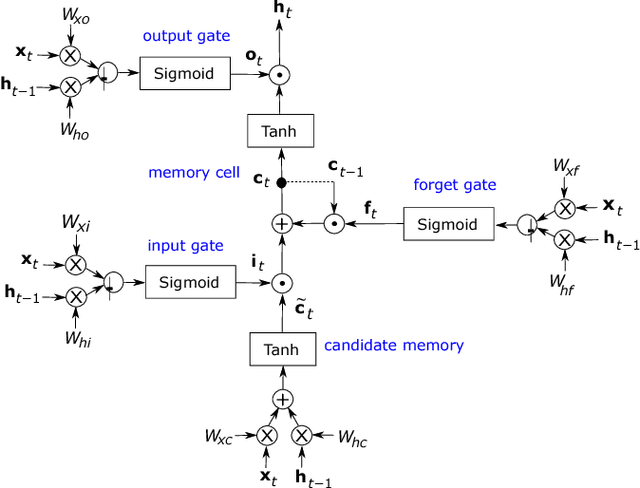
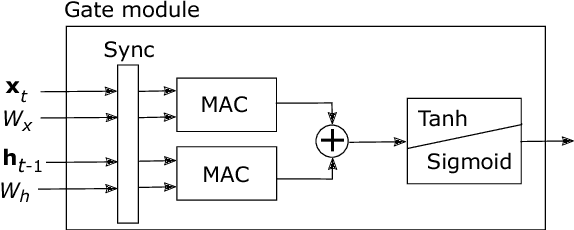
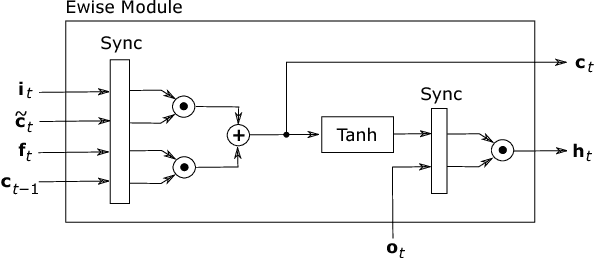
Recurrent Neural Networks (RNNs) have the ability to retain memory and learn data sequences. Due to the recurrent nature of RNNs, it is sometimes hard to parallelize all its computations on conventional hardware. CPUs do not currently offer large parallelism, while GPUs offer limited parallelism due to sequential components of RNN models. In this paper we present a hardware implementation of Long-Short Term Memory (LSTM) recurrent network on the programmable logic Zynq 7020 FPGA from Xilinx. We implemented a RNN with $2$ layers and $128$ hidden units in hardware and it has been tested using a character level language model. The implementation is more than $21\times$ faster than the ARM CPU embedded on the Zynq 7020 FPGA. This work can potentially evolve to a RNN co-processor for future mobile devices.