 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Multimodal Model Architectures
May 28, 2024
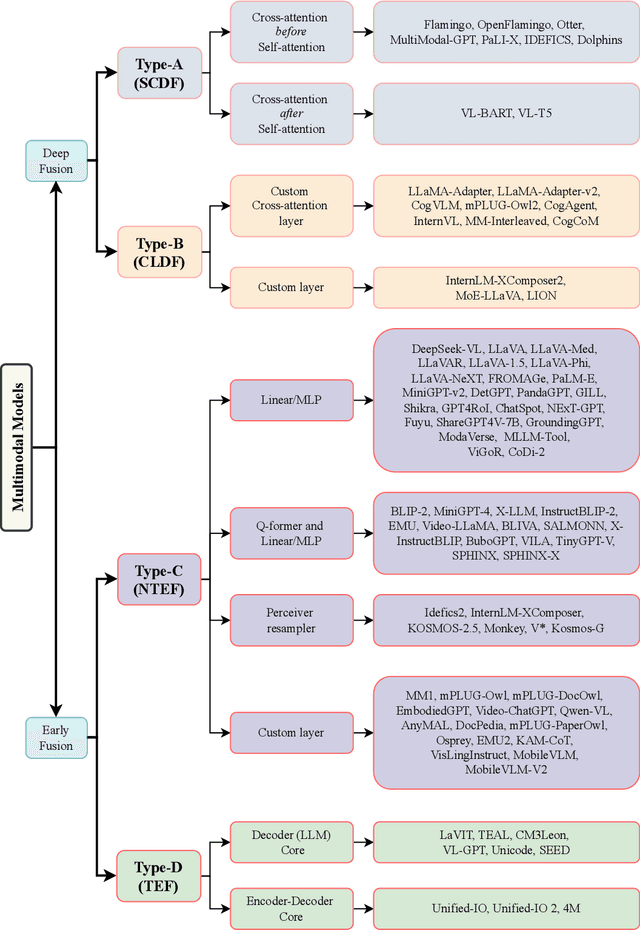
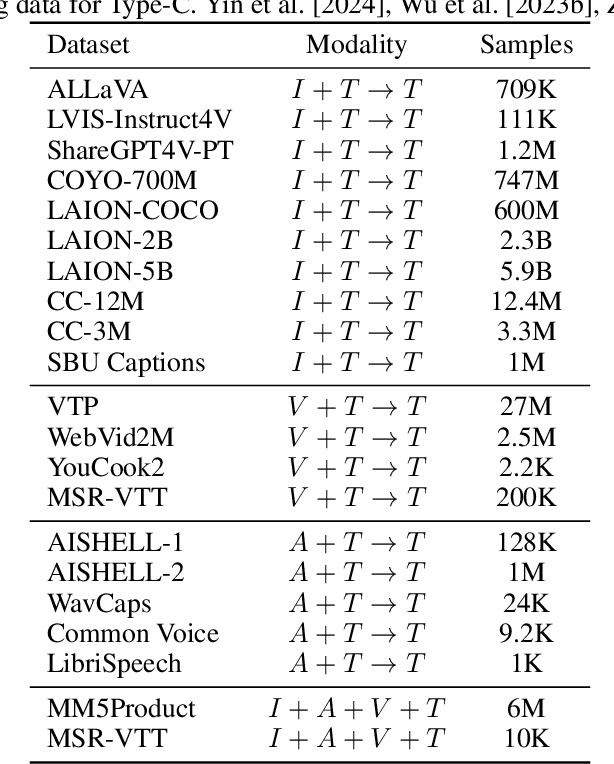
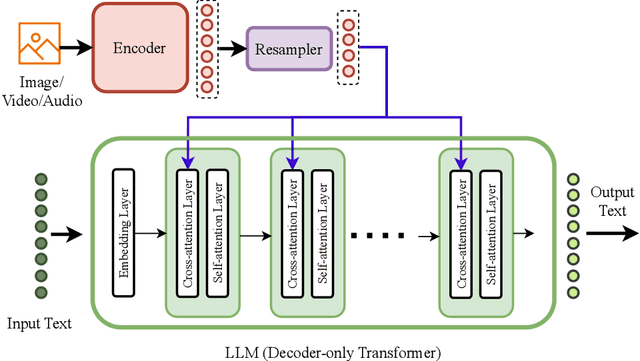
This work uniquely identifies and characterizes four prevalent multimodal model architectural patterns in the contemporary multimodal landscape. Systematically categorizing models by architecture type facilitates monitoring of developments in the multimodal domain. Distinct from recent survey papers that present general information on multimodal architectures, this research conducts a comprehensive exploration of architectural details and identifies four specific architectural types. The types are distinguished by their respective methodologies for integrating multimodal inputs into the deep neural network model. The first two types (Type A and B) deeply fuses multimodal inputs within the internal layers of the model, whereas the following two types (Type C and D) facilitate early fusion at the input stage. Type-A employs standard cross-attention, whereas Type-B utilizes custom-designed layers for modality fusion within the internal layers. On the other hand, Type-C utilizes modality-specific encoders, while Type-D leverages tokenizers to process the modalities at the model's input stage. The identified architecture types aid the monitoring of any-to-any multimodal model development. Notably, Type-C and Type-D are currently favored in the construction of any-to-any multimodal models. Type-C, distinguished by its non-tokenizing multimodal model architecture, is emerging as a viable alternative to Type-D, which utilizes input-tokenizing techniques. To assist in model selection, this work highlights the advantages and disadvantages of each architecture type based on data and compute requirements, architecture complexity, scalability, simplification of adding modalities, training objectives, and any-to-any multimodal generation capability.
MobileViTv3: Mobile-Friendly Vision Transformer with Simple and Effective Fusion of Local, Global and Input Features
Oct 06, 2022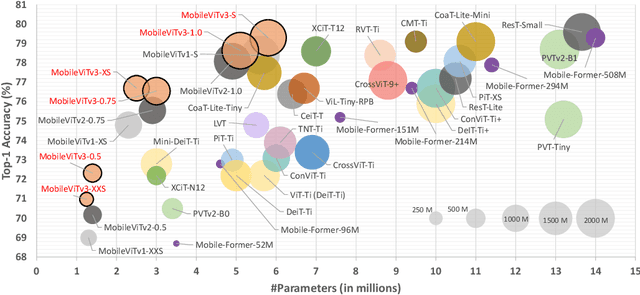
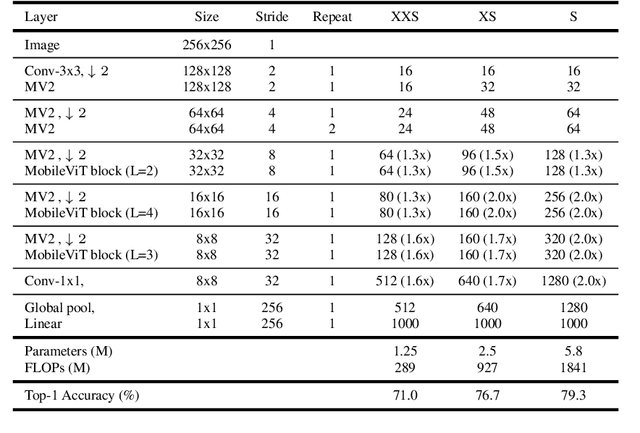
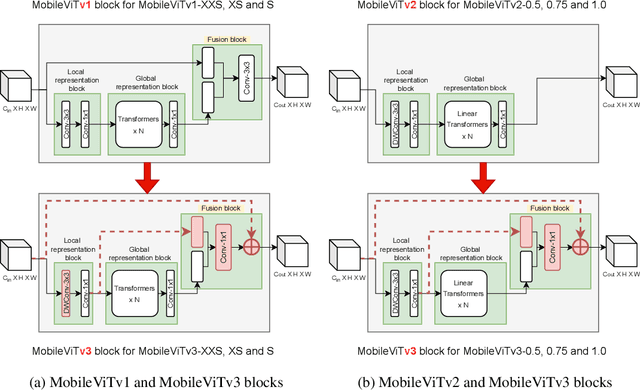
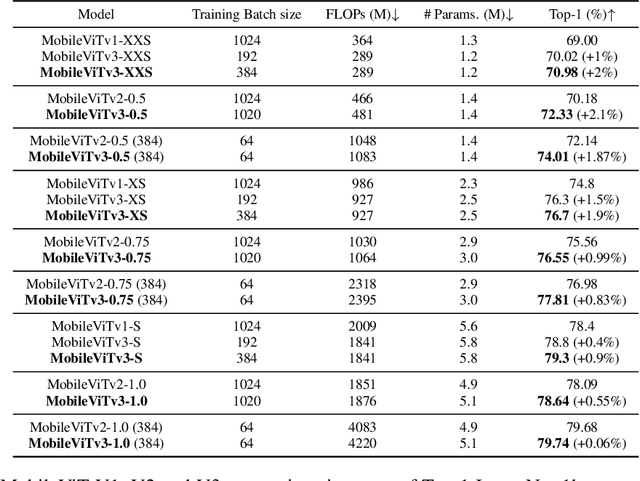
MobileViT (MobileViTv1) combines convolutional neural networks (CNNs) and vision transformers (ViTs) to create light-weight models for mobile vision tasks. Though the main MobileViTv1-block helps to achieve competitive state-of-the-art results, the fusion block inside MobileViTv1-block, creates scaling challenges and has a complex learning task. We propose changes to the fusion block that are simple and effective to create MobileViTv3-block, which addresses the scaling and simplifies the learning task. Our proposed MobileViTv3-block used to create MobileViTv3-XXS, XS and S models outperform MobileViTv1 on ImageNet-1k, ADE20K, COCO and PascalVOC2012 datasets. On ImageNet-1K, MobileViTv3-XXS and MobileViTv3-XS surpasses MobileViTv1-XXS and MobileViTv1-XS by 2% and 1.9% respectively. Recently published MobileViTv2 architecture removes fusion block and uses linear complexity transformers to perform better than MobileViTv1. We add our proposed fusion block to MobileViTv2 to create MobileViTv3-0.5, 0.75 and 1.0 models. These new models give better accuracy numbers on ImageNet-1k, ADE20K, COCO and PascalVOC2012 datasets as compared to MobileViTv2. MobileViTv3-0.5 and MobileViTv3-0.75 outperforms MobileViTv2-0.5 and MobileViTv2-0.75 by 2.1% and 1.0% respectively on ImageNet-1K dataset. For segmentation task, MobileViTv3-1.0 achieves 2.07% and 1.1% better mIOU compared to MobileViTv2-1.0 on ADE20K dataset and PascalVOC2012 dataset respectively. Our code and the trained models are available at: https://github.com/micronDLA/MobileViTv3
Reinforcement Learning Approach for Mapping Applications to Dataflow-Based Coarse-Grained Reconfigurable Array
May 26, 2022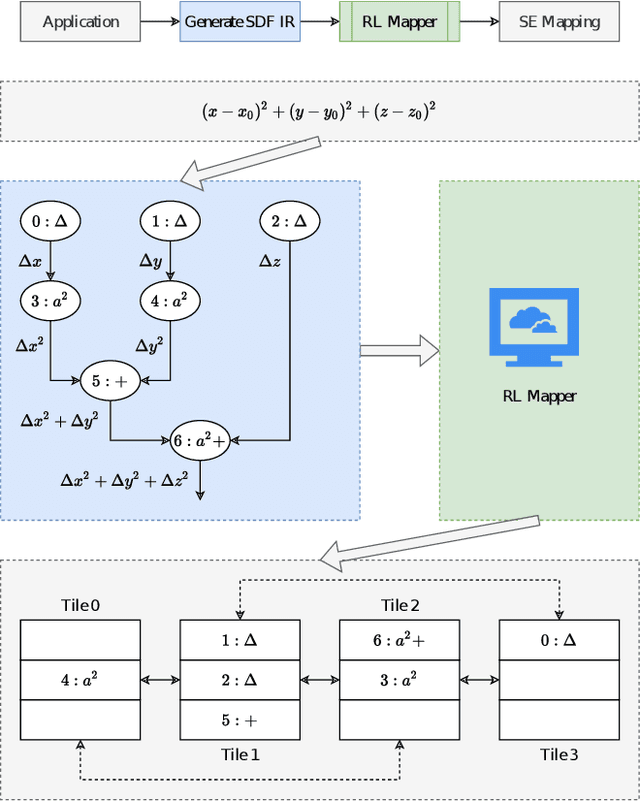
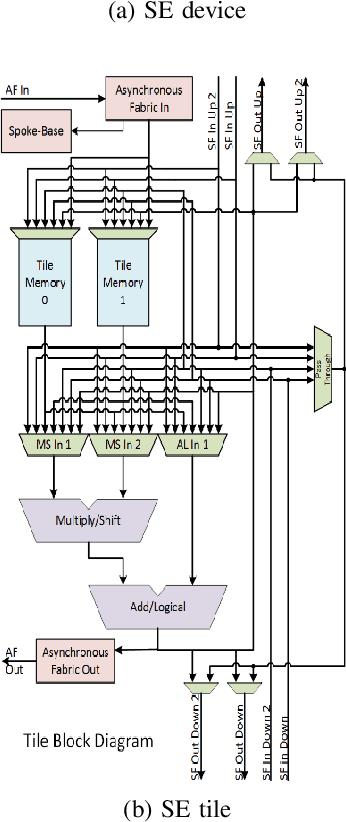
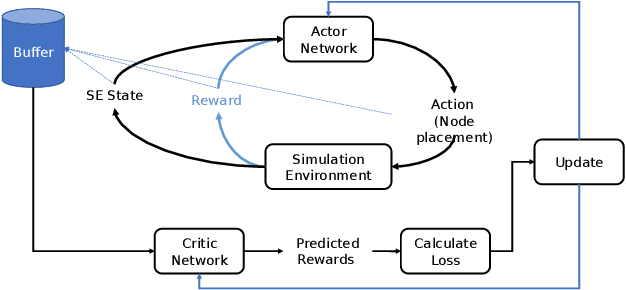
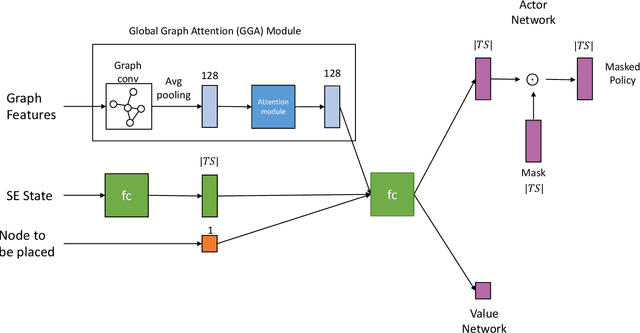
The Streaming Engine (SE) is a Coarse-Grained Reconfigurable Array which provides programming flexibility and high-performance with energy efficiency. An application program to be executed on the SE is represented as a combination of Synchronous Data Flow (SDF) graphs, where every instruction is represented as a node. Each node needs to be mapped to the right slot and array in the SE to ensure the correct execution of the program. This creates an optimization problem with a vast and sparse search space for which finding a mapping manually is impractical because it requires expertise and knowledge of the SE micro-architecture. In this work we propose a Reinforcement Learning framework with Global Graph Attention (GGA) module and output masking of invalid placements to find and optimize instruction schedules. We use Proximal Policy Optimization in order to train a model which places operations into the SE tiles based on a reward function that models the SE device and its constraints. The GGA module consists of a graph neural network and an attention module. The graph neural network creates embeddings of the SDFs and the attention block is used to model sequential operation placement. We show results on how certain workloads are mapped to the SE and the factors affecting mapping quality. We find that the addition of GGA, on average, finds 10% better instruction schedules in terms of total clock cycles taken and masking improves reward obtained by 20%.
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
Jun 14, 2017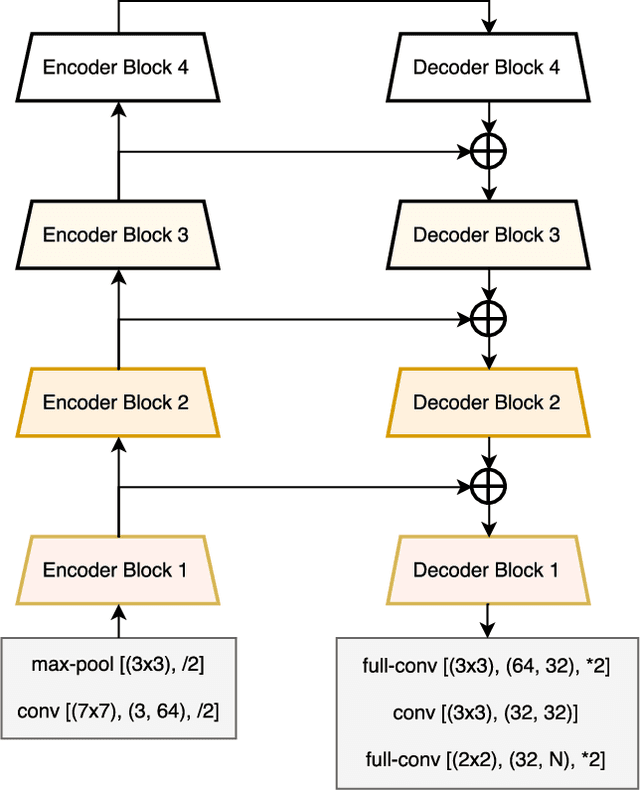
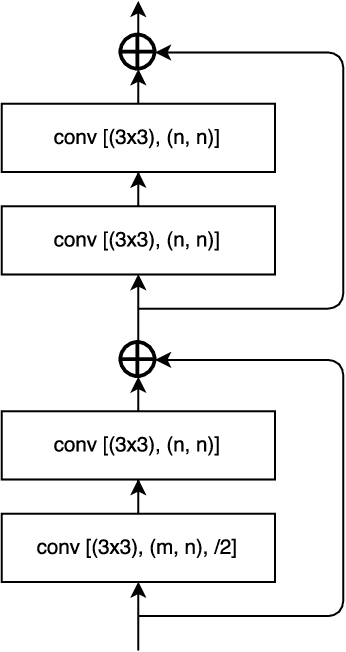
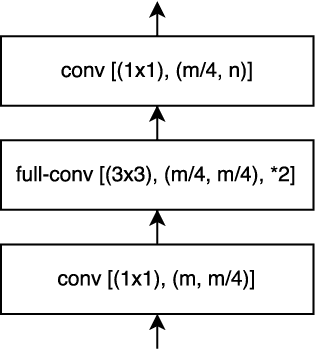
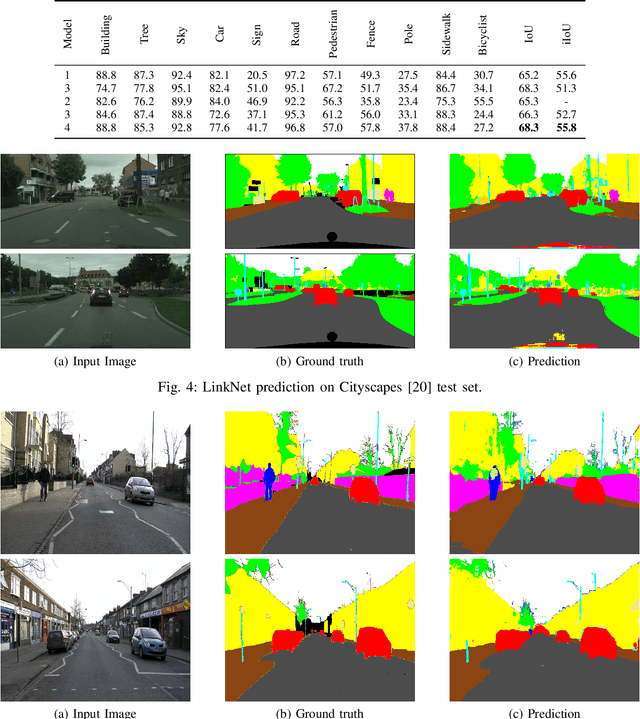
Pixel-wise semantic segmentation for visual scene understanding not only needs to be accurate, but also efficient in order to find any use in real-time application. Existing algorithms even though are accurate but they do not focus on utilizing the parameters of neural network efficiently. As a result they are huge in terms of parameters and number of operations; hence slow too. In this paper, we propose a novel deep neural network architecture which allows it to learn without any significant increase in number of parameters. Our network uses only 11.5 million parameters and 21.2 GFLOPs for processing an image of resolution 3x640x360. It gives state-of-the-art performance on CamVid and comparable results on Cityscapes dataset. We also compare our networks processing time on NVIDIA GPU and embedded system device with existing state-of-the-art architectures for different image resolutions.
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Jun 07, 2016
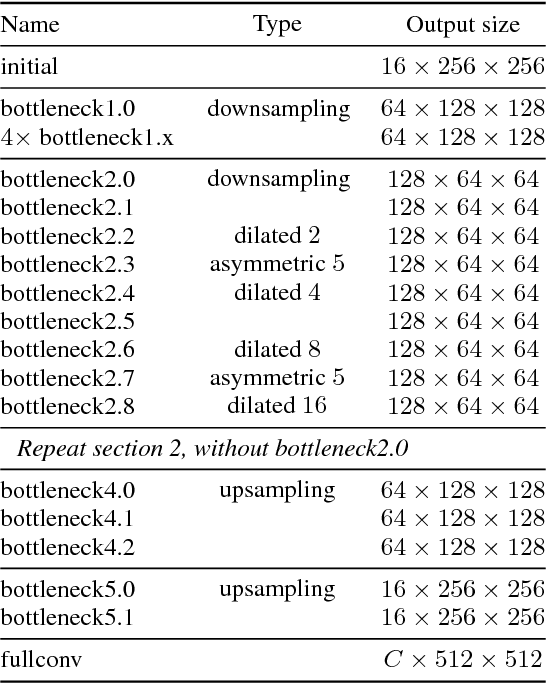
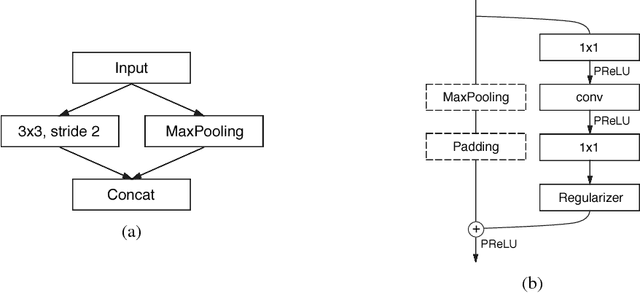

The ability to perform pixel-wise semantic segmentation in real-time is of paramount importance in mobile applications. Recent deep neural networks aimed at this task have the disadvantage of requiring a large number of floating point operations and have long run-times that hinder their usability. In this paper, we propose a novel deep neural network architecture named ENet (efficient neural network), created specifically for tasks requiring low latency operation. ENet is up to 18$\times$ faster, requires 75$\times$ less FLOPs, has 79$\times$ less parameters, and provides similar or better accuracy to existing models. We have tested it on CamVid, Cityscapes and SUN datasets and report on comparisons with existing state-of-the-art methods, and the trade-offs between accuracy and processing time of a network. We present performance measurements of the proposed architecture on embedded systems and suggest possible software improvements that could make ENet even faster.