 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution of Multimodal Model Architectures
May 28, 2024
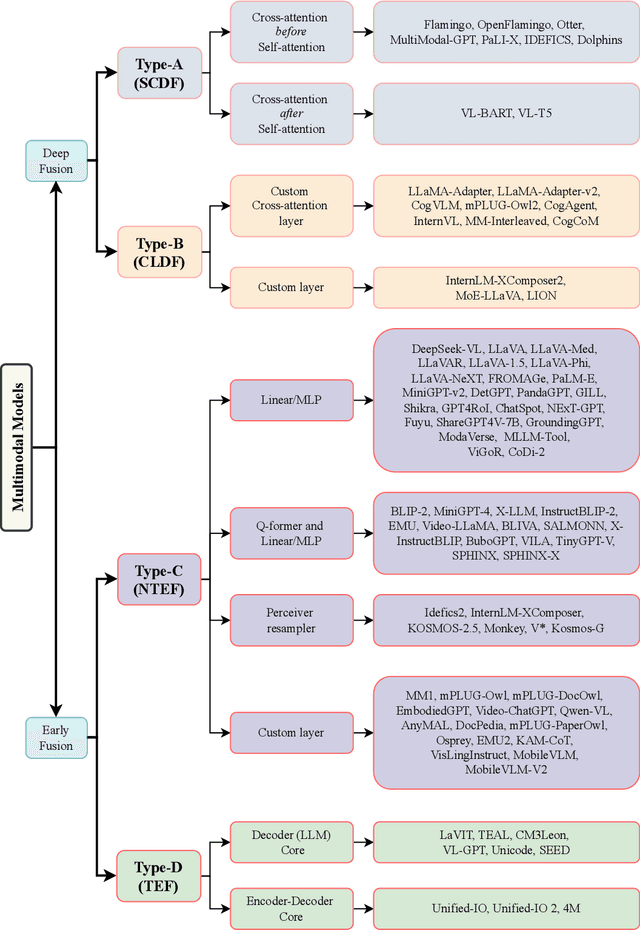
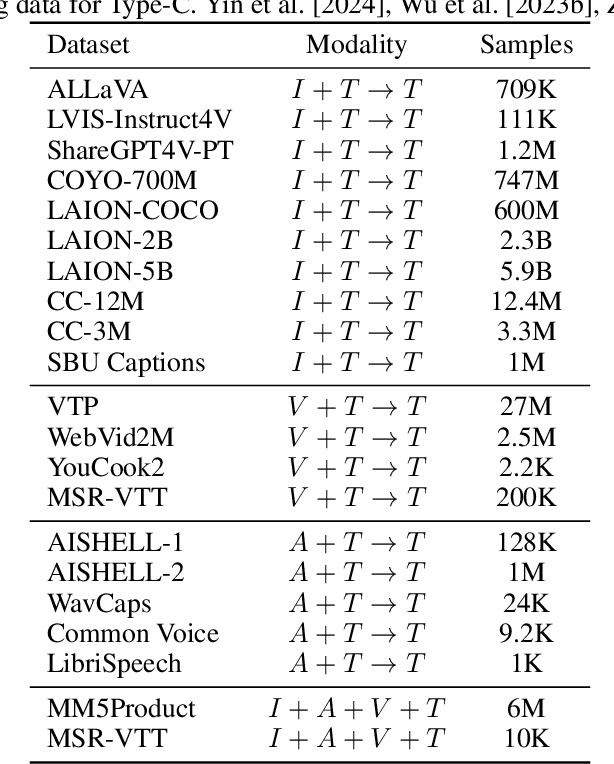
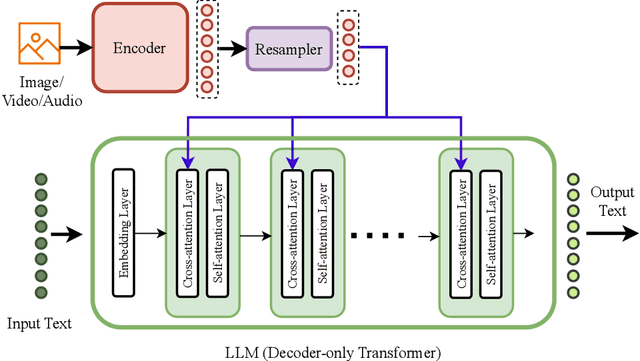
This work uniquely identifies and characterizes four prevalent multimodal model architectural patterns in the contemporary multimodal landscape. Systematically categorizing models by architecture type facilitates monitoring of developments in the multimodal domain. Distinct from recent survey papers that present general information on multimodal architectures, this research conducts a comprehensive exploration of architectural details and identifies four specific architectural types. The types are distinguished by their respective methodologies for integrating multimodal inputs into the deep neural network model. The first two types (Type A and B) deeply fuses multimodal inputs within the internal layers of the model, whereas the following two types (Type C and D) facilitate early fusion at the input stage. Type-A employs standard cross-attention, whereas Type-B utilizes custom-designed layers for modality fusion within the internal layers. On the other hand, Type-C utilizes modality-specific encoders, while Type-D leverages tokenizers to process the modalities at the model's input stage. The identified architecture types aid the monitoring of any-to-any multimodal model development. Notably, Type-C and Type-D are currently favored in the construction of any-to-any multimodal models. Type-C, distinguished by its non-tokenizing multimodal model architecture, is emerging as a viable alternative to Type-D, which utilizes input-tokenizing techniques. To assist in model selection, this work highlights the advantages and disadvantages of each architecture type based on data and compute requirements, architecture complexity, scalability, simplification of adding modalities, training objectives, and any-to-any multimodal generation capability.
OneCAD: One Classifier for All image Datasets using multimodal learning
May 11, 2023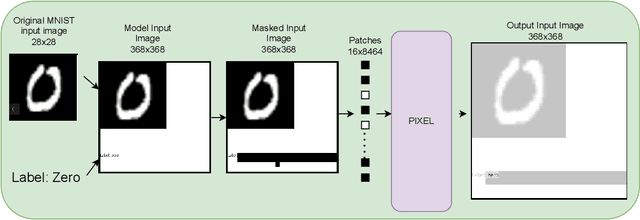

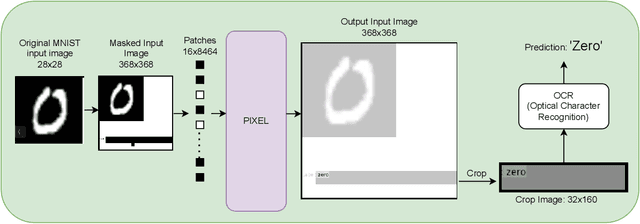

Vision-Transformers (ViTs) and Convolutional neural networks (CNNs) are widely used Deep Neural Networks (DNNs) for classification task. These model architectures are dependent on the number of classes in the dataset it was trained on. Any change in number of classes leads to change (partial or full) in the model's architecture. This work addresses the question: Is it possible to create a number-of-class-agnostic model architecture?. This allows model's architecture to be independent of the dataset it is trained on. This work highlights the issues with the current architectures (ViTs and CNNs). Also, proposes a training and inference framework OneCAD (One Classifier for All image Datasets) to achieve close-to number-of-class-agnostic transformer model. To best of our knowledge this is the first work to use Mask-Image-Modeling (MIM) with multimodal learning for classification task to create a DNN model architecture agnostic to the number of classes. Preliminary results are shown on natural and medical image datasets. Datasets: MNIST, CIFAR10, CIFAR100 and COVIDx. Code will soon be publicly available on github.
MobileViTv3: Mobile-Friendly Vision Transformer with Simple and Effective Fusion of Local, Global and Input Features
Oct 06, 2022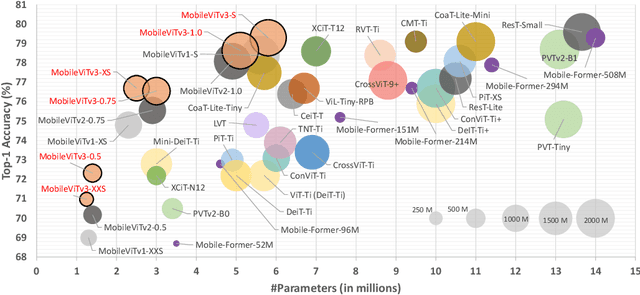
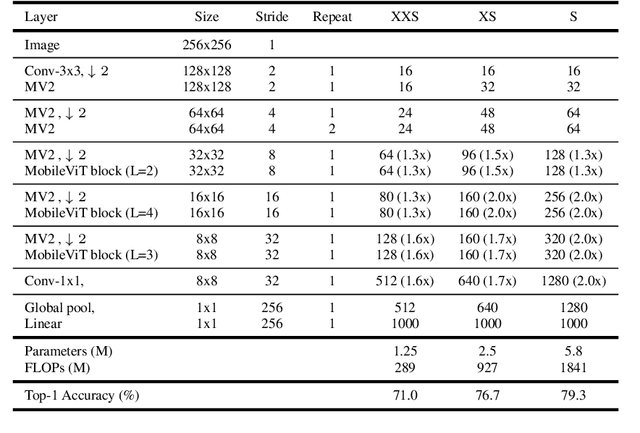
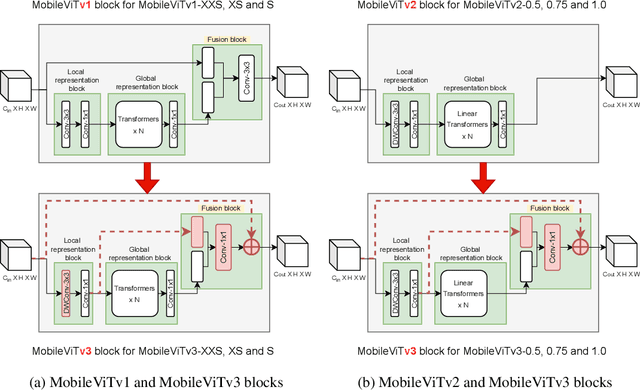
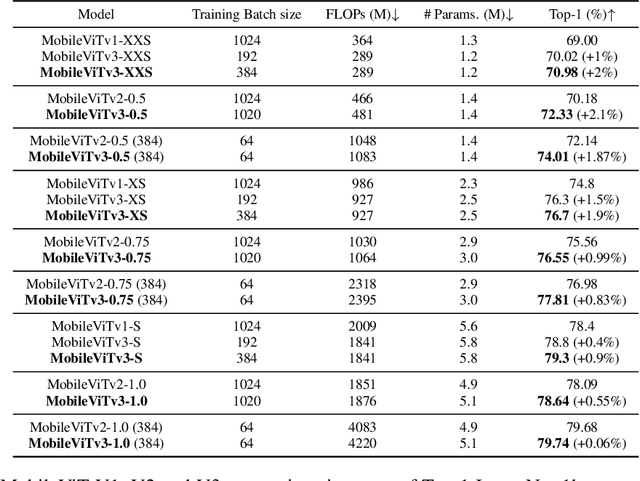
MobileViT (MobileViTv1) combines convolutional neural networks (CNNs) and vision transformers (ViTs) to create light-weight models for mobile vision tasks. Though the main MobileViTv1-block helps to achieve competitive state-of-the-art results, the fusion block inside MobileViTv1-block, creates scaling challenges and has a complex learning task. We propose changes to the fusion block that are simple and effective to create MobileViTv3-block, which addresses the scaling and simplifies the learning task. Our proposed MobileViTv3-block used to create MobileViTv3-XXS, XS and S models outperform MobileViTv1 on ImageNet-1k, ADE20K, COCO and PascalVOC2012 datasets. On ImageNet-1K, MobileViTv3-XXS and MobileViTv3-XS surpasses MobileViTv1-XXS and MobileViTv1-XS by 2% and 1.9% respectively. Recently published MobileViTv2 architecture removes fusion block and uses linear complexity transformers to perform better than MobileViTv1. We add our proposed fusion block to MobileViTv2 to create MobileViTv3-0.5, 0.75 and 1.0 models. These new models give better accuracy numbers on ImageNet-1k, ADE20K, COCO and PascalVOC2012 datasets as compared to MobileViTv2. MobileViTv3-0.5 and MobileViTv3-0.75 outperforms MobileViTv2-0.5 and MobileViTv2-0.75 by 2.1% and 1.0% respectively on ImageNet-1K dataset. For segmentation task, MobileViTv3-1.0 achieves 2.07% and 1.1% better mIOU compared to MobileViTv2-1.0 on ADE20K dataset and PascalVOC2012 dataset respectively. Our code and the trained models are available at: https://github.com/micronDLA/MobileViTv3
Towards End-to-End Deep Learning for Autonomous Racing: On Data Collection and a Unified Architecture for Steering and Throttle Prediction
May 04, 2021
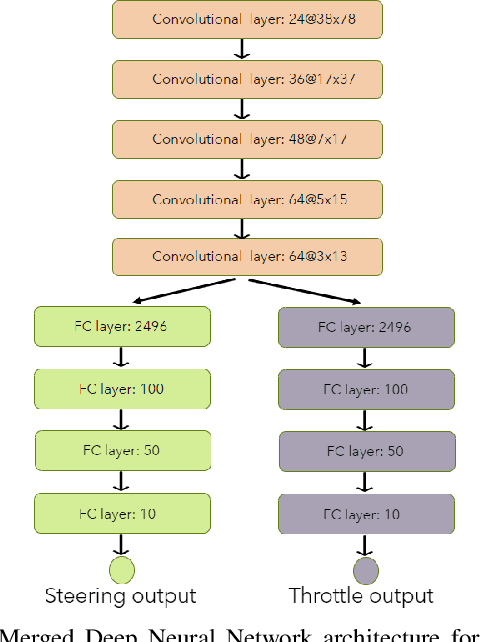

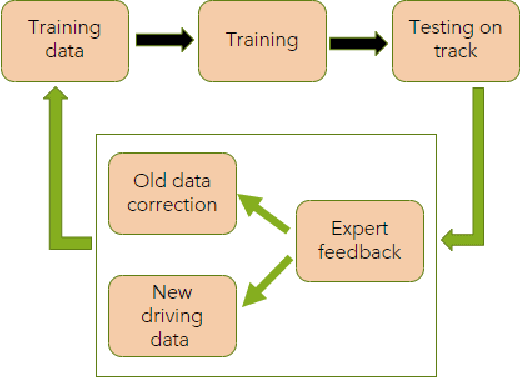
Deep Neural Networks (DNNs) which are trained end-to-end have been successfully applied to solve complex problems that we have not been able to solve in past decades. Autonomous driving is one of the most complex problems which is yet to be completely solved and autonomous racing adds more complexity and exciting challenges to this problem. Towards the challenge of applying end-to-end learning to autonomous racing, this paper shows results on two aspects: (1) Analyzing the relationship between the driving data used for training and the maximum speed at which the DNN can be successfully applied for predicting steering angle, (2) Neural network architecture and training methodology for learning steering and throttle without any feedback or recurrent connections.