 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFetFIDS: A Feature Embedding Attention based Federated Network Intrusion Detection Algorithm
Aug 12, 2025Intrusion Detection Systems (IDS) have an increasingly important role in preventing exploitation of network vulnerabilities by malicious actors. Recent deep learning based developments have resulted in significant improvements in the performance of IDS systems. In this paper, we present FetFIDS, where we explore the employment of feature embedding instead of positional embedding to improve intrusion detection performance of a transformer based deep learning system. Our model is developed with the aim of deployments in edge learning scenarios, where federated learning over multiple communication rounds can ensure both privacy and localized performance improvements. FetFIDS outperforms multiple state-of-the-art intrusion detection systems in a federated environment and demonstrates a high degree of suitability to federated learning. The code for this work can be found at https://github.com/ghosh64/fetfids.
Developing a Transferable Federated Network Intrusion Detection System
Aug 12, 2025Intrusion Detection Systems (IDS) are a vital part of a network-connected device. In this paper, we develop a deep learning based intrusion detection system that is deployed in a distributed setup across devices connected to a network. Our aim is to better equip deep learning models against unknown attacks using knowledge from known attacks. To this end, we develop algorithms to maximize the number of transferability relationships. We propose a Convolutional Neural Network (CNN) model, along with two algorithms that maximize the number of relationships observed. One is a two step data pre-processing stage, and the other is a Block-Based Smart Aggregation (BBSA) algorithm. The proposed system succeeds in achieving superior transferability performance while maintaining impressive local detection rates. We also show that our method is generalizable, exhibiting transferability potential across datasets and even with different backbones. The code for this work can be found at https://github.com/ghosh64/tabfidsv2.
A Racing Dataset and Baseline Model for Track Detection in Autonomous Racing
Feb 19, 2025A significant challenge in racing-related research is the lack of publicly available datasets containing raw images with corresponding annotations for the downstream task. In this paper, we introduce RoRaTrack, a novel dataset that contains annotated multi-camera image data from racing scenarios for track detection. The data is collected on a Dallara AV-21 at a racing circuit in Indiana, in collaboration with the Indy Autonomous Challenge (IAC). RoRaTrack addresses common problems such as blurriness due to high speed, color inversion from the camera, and absence of lane markings on the track. Consequently, we propose RaceGAN, a baseline model based on a Generative Adversarial Network (GAN) that effectively addresses these challenges. The proposed model demonstrates superior performance compared to current state-of-the-art machine learning models in track detection. The dataset and code for this work are available at github.com/RaceGAN.
Improving Transferability of Network Intrusion Detection in a Federated Learning Setup
Jan 07, 2024



Network Intrusion Detection Systems (IDS) aim to detect the presence of an intruder by analyzing network packets arriving at an internet connected device. Data-driven deep learning systems, popular due to their superior performance compared to traditional IDS, depend on availability of high quality training data for diverse intrusion classes. A way to overcome this limitation is through transferable learning, where training for one intrusion class can lead to detection of unseen intrusion classes after deployment. In this paper, we provide a detailed study on the transferability of intrusion detection. We investigate practical federated learning configurations to enhance the transferability of intrusion detection. We propose two techniques to significantly improve the transferability of a federated intrusion detection system. The code for this work can be found at https://github.com/ghosh64/transferability.
Data-Driven Subsampling in the Presence of an Adversarial Actor
Jan 07, 2024Deep learning based automatic modulation classification (AMC) has received significant attention owing to its potential applications in both military and civilian use cases. Recently, data-driven subsampling techniques have been utilized to overcome the challenges associated with computational complexity and training time for AMC. Beyond these direct advantages of data-driven subsampling, these methods also have regularizing properties that may improve the adversarial robustness of the modulation classifier. In this paper, we investigate the effects of an adversarial attack on an AMC system that employs deep learning models both for AMC and for subsampling. Our analysis shows that subsampling itself is an effective deterrent to adversarial attacks. We also uncover the most efficient subsampling strategy when an adversarial attack on both the classifier and the subsampler is anticipated.
Deep OFDM Channel Estimation: Capturing Frequency Recurrence
Jan 07, 2024In this paper, we propose a deep-learning-based channel estimation scheme in an orthogonal frequency division multiplexing (OFDM) system. Our proposed method, named Single Slot Recurrence Along Frequency Network (SisRafNet), is based on a novel study of recurrent models for exploiting sequential behavior of channels across frequencies. Utilizing the fact that wireless channels have a high degree of correlation across frequencies, we employ recurrent neural network techniques within a single OFDM slot, thus overcoming the latency and memory constraints typically associated with recurrence based methods. The proposed SisRafNet delivers superior estimation performance compared to existing deep-learning-based channel estimation techniques and the performance has been validated on a wide range of 3rd Generation Partnership Project (3GPP) compliant channel scenarios at multiple signal-to-noise ratios.
A Study on Transferability of Deep Learning Models for Network Intrusion Detection
Dec 17, 2023In this paper, we explore transferability in learning between different attack classes in a network intrusion detection setup. We evaluate transferability of attack classes by training a deep learning model with a specific attack class and testing it on a separate attack class. We observe the effects of real and synthetically generated data augmentation techniques on transferability. We investigate the nature of observed transferability relationships, which can be either symmetric or asymmetric. We also examine explainability of the transferability relationships using the recursive feature elimination algorithm. We study data preprocessing techniques to boost model performance. The code for this work can be found at https://github.com/ghosh64/transferability.
CD&S Dataset: Handheld Imagery Dataset Acquired Under Field Conditions for Corn Disease Identification and Severity Estimation
Oct 22, 2021
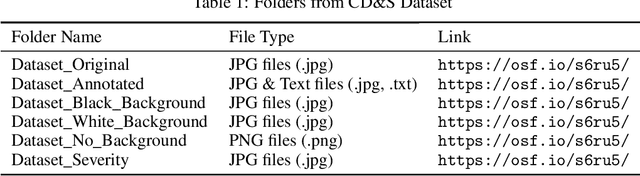
Accurate disease identification and its severity estimation is an important consideration for disease management. Deep learning-based solutions for disease management using imagery datasets are being increasingly explored by the research community. However, most reported studies have relied on imagery datasets that were acquired under controlled lab conditions. As a result, such models lacked the ability to identify diseases in the field. Therefore, to train a robust deep learning model for field use, an imagery dataset was created using raw images acquired under field conditions using a handheld sensor and augmented images with varying backgrounds. The Corn Disease and Severity (CD&S) dataset consisted of 511, 524, and 562, field acquired raw images, corresponding to three common foliar corn diseases, namely Northern Leaf Blight (NLB), Gray Leaf Spot (GLS), and Northern Leaf Spot (NLS), respectively. For training disease identification models, half of the imagery data for each disease was annotated using bounding boxes and also used to generate 2343 additional images through augmentation using three different backgrounds. For severity estimation, an additional 515 raw images for NLS were acquired and categorized into severity classes ranging from 1 (resistant) to 5 (susceptible). Overall, the CD&S dataset consisted of 4455 total images comprising of 2112 field images and 2343 augmented images.
Towards End-to-End Deep Learning for Autonomous Racing: On Data Collection and a Unified Architecture for Steering and Throttle Prediction
May 04, 2021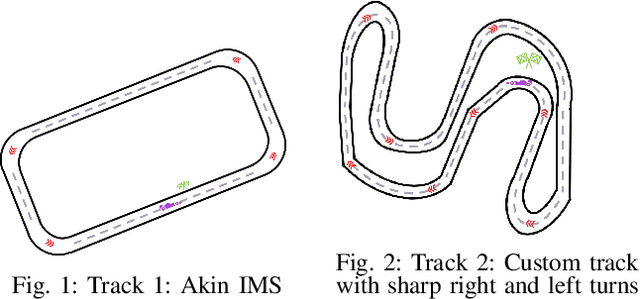
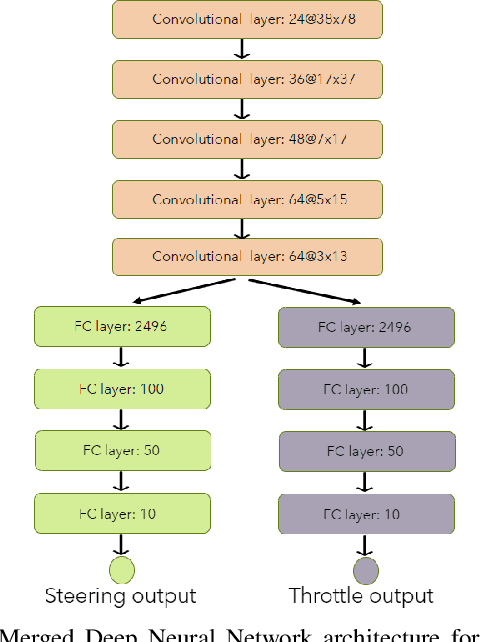

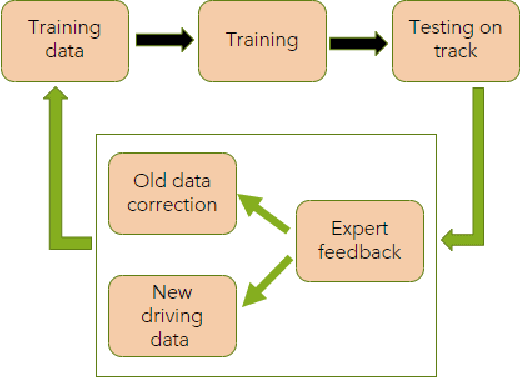
Deep Neural Networks (DNNs) which are trained end-to-end have been successfully applied to solve complex problems that we have not been able to solve in past decades. Autonomous driving is one of the most complex problems which is yet to be completely solved and autonomous racing adds more complexity and exciting challenges to this problem. Towards the challenge of applying end-to-end learning to autonomous racing, this paper shows results on two aspects: (1) Analyzing the relationship between the driving data used for training and the maximum speed at which the DNN can be successfully applied for predicting steering angle, (2) Neural network architecture and training methodology for learning steering and throttle without any feedback or recurrent connections.
Mitigating Gradient-based Adversarial Attacks via Denoising and Compression
Apr 03, 2021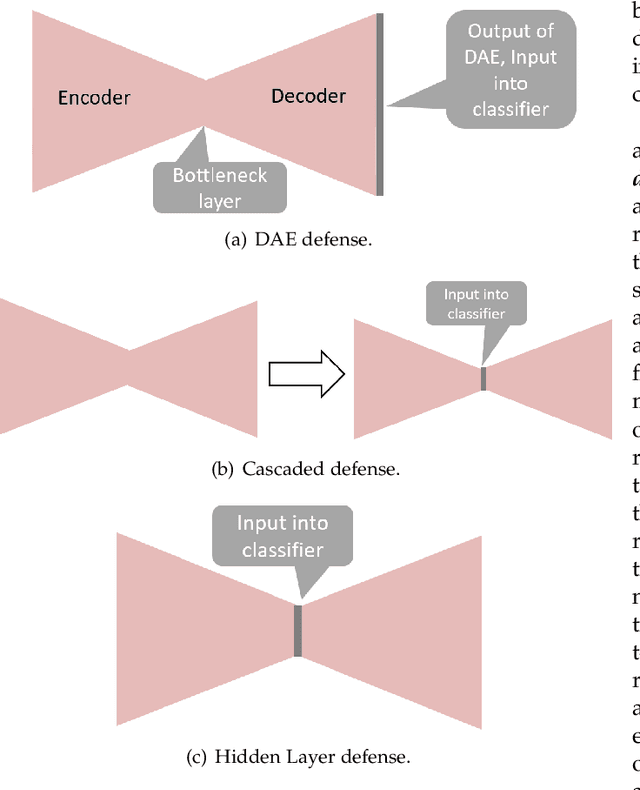
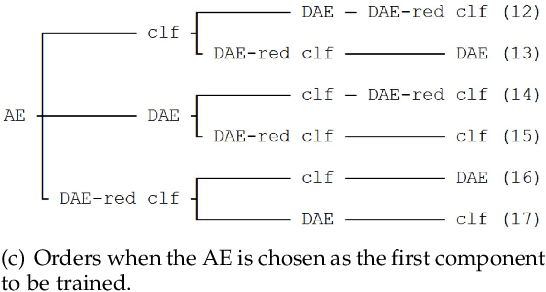
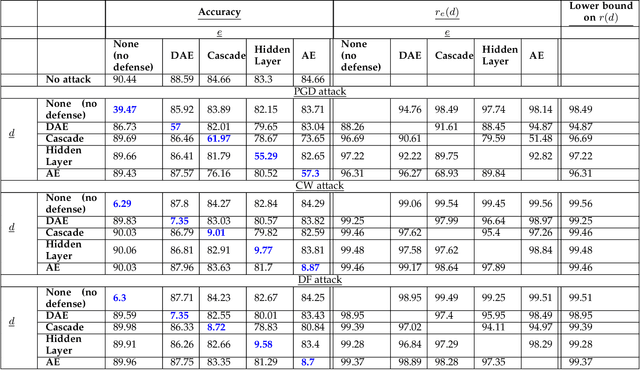

Gradient-based adversarial attacks on deep neural networks pose a serious threat, since they can be deployed by adding imperceptible perturbations to the test data of any network, and the risk they introduce cannot be assessed through the network's original training performance. Denoising and dimensionality reduction are two distinct methods that have been independently investigated to combat such attacks. While denoising offers the ability to tailor the defense to the specific nature of the attack, dimensionality reduction offers the advantage of potentially removing previously unseen perturbations, along with reducing the training time of the network being defended. We propose strategies to combine the advantages of these two defense mechanisms. First, we propose the cascaded defense, which involves denoising followed by dimensionality reduction. To reduce the training time of the defense for a small trade-off in performance, we propose the hidden layer defense, which involves feeding the output of the encoder of a denoising autoencoder into the network. Further, we discuss how adaptive attacks against these defenses could become significantly weak when an alternative defense is used, or when no defense is used. In this light, we propose a new metric to evaluate a defense which measures the sensitivity of the adaptive attack to modifications in the defense. Finally, we present a guideline for building an ordered repertoire of defenses, a.k.a. a defense infrastructure, that adjusts to limited computational resources in presence of uncertainty about the attack strategy.