 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactive Conversational Assistant for a Procedural Manual Task based on Audio and IMU
Feb 17, 2026Real-time conversational assistants for procedural tasks often depend on video input, which can be computationally expensive and compromise user privacy. For the first time, we propose a real-time conversational assistant that provides comprehensive guidance for a procedural task using only lightweight privacy-preserving modalities such as audio and IMU inputs from a user's wearable device to understand the context. This assistant proactively communicates step-by-step instructions to a user performing a furniture assembly task, and answers user questions. We construct a dataset containing conversations where the assistant guides the user in performing the task. On observing that an off-the-shelf language model is a very talkative assistant, we design a novel User Whim Agnostic (UWA) LoRA finetuning method which improves the model's ability to suppress less informative dialogues, while maintaining its tendency to communicate important instructions. This leads to >30% improvement in the F-score. Finetuning the model also results in a 16x speedup by eliminating the need to provide in-context examples in the prompt. We further describe how such an assistant is implemented on edge devices with no dependence on the cloud.
Aligning Audio Captions with Human Preferences
Sep 18, 2025Current audio captioning systems rely heavily on supervised learning with paired audio-caption datasets, which are expensive to curate and may not reflect human preferences in real-world scenarios. To address this limitation, we propose a preference-aligned audio captioning framework based on Reinforcement Learning from Human Feedback (RLHF). To effectively capture nuanced human preferences, we train a Contrastive Language-Audio Pretraining (CLAP)-based reward model using human-labeled pairwise preference data. This reward model is integrated into a reinforcement learning framework to fine-tune any baseline captioning system without relying on ground-truth caption annotations. Extensive human evaluations across multiple datasets show that our method produces captions preferred over those from baseline models, particularly in cases where the baseline models fail to provide correct and natural captions. Furthermore, our framework achieves performance comparable to supervised approaches with ground-truth data, demonstrating its effectiveness in aligning audio captioning with human preferences and its scalability in real-world scenarios.
Confidence Calibration for Audio Captioning Models
Sep 13, 2024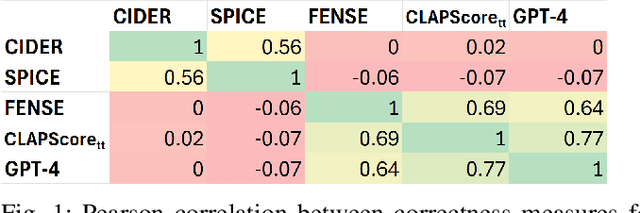
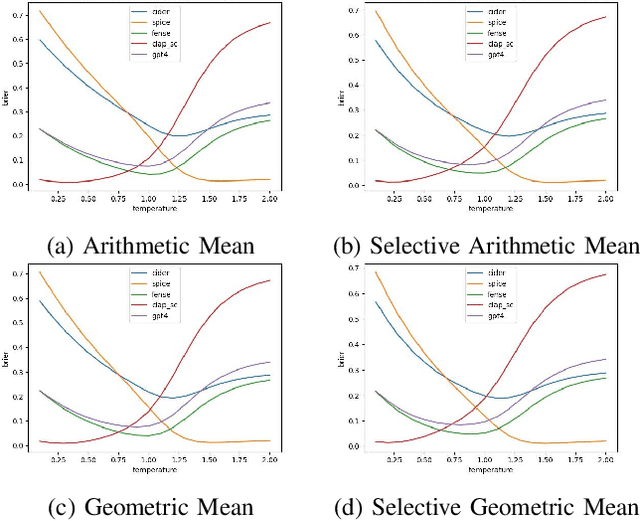
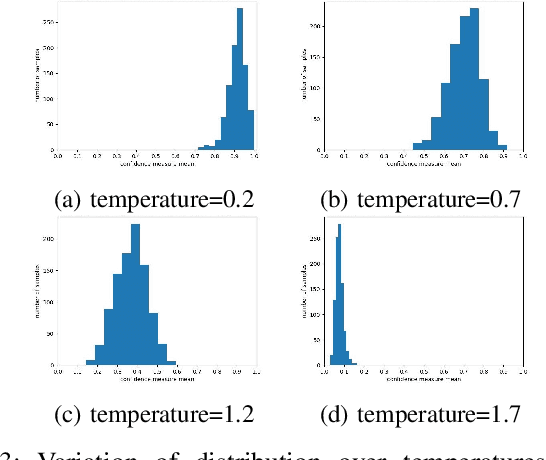
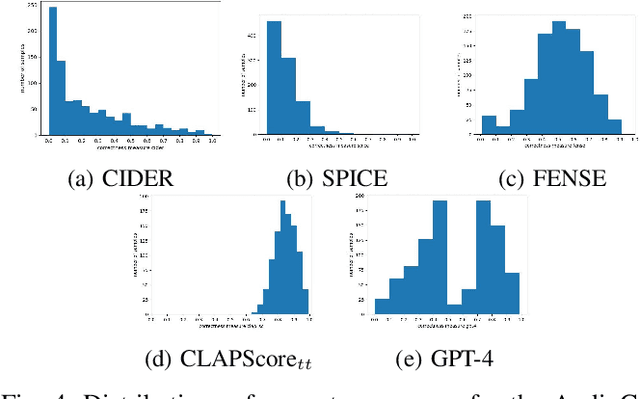
Systems that automatically generate text captions for audio, images and video lack a confidence indicator of the relevance and correctness of the generated sequences. To address this, we build on existing methods of confidence measurement for text by introduce selective pooling of token probabilities, which aligns better with traditional correctness measures than conventional pooling does. Further, we propose directly measuring the similarity between input audio and text in a shared embedding space. To measure self-consistency, we adapt semantic entropy for audio captioning, and find that these two methods align even better than pooling-based metrics with the correctness measure that calculates acoustic similarity between captions. Finally, we explain why temperature scaling of confidences improves calibration.
Parameter Efficient Audio Captioning With Faithful Guidance Using Audio-text Shared Latent Representation
Sep 06, 2023
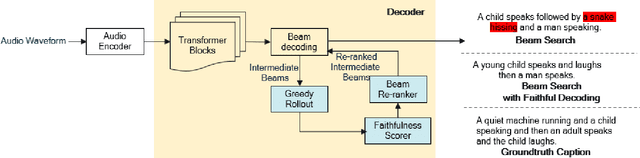


There has been significant research on developing pretrained transformer architectures for multimodal-to-text generation tasks. Albeit performance improvements, such models are frequently overparameterized, hence suffer from hallucination and large memory footprint making them challenging to deploy on edge devices. In this paper, we address both these issues for the application of automated audio captioning. First, we propose a data augmentation technique for generating hallucinated audio captions and show that similarity based on an audio-text shared latent space is suitable for detecting hallucination. Then, we propose a parameter efficient inference time faithful decoding algorithm that enables smaller audio captioning models with performance equivalent to larger models trained with more data. During the beam decoding step, the smaller model utilizes an audio-text shared latent representation to semantically align the generated text with corresponding input audio. Faithful guidance is introduced into the beam probability by incorporating the cosine similarity between latent representation projections of greedy rolled out intermediate beams and audio clip. We show the efficacy of our algorithm on benchmark datasets and evaluate the proposed scheme against baselines using conventional audio captioning and semantic similarity metrics while illustrating tradeoffs between performance and complexity.
Mitigating Gradient-based Adversarial Attacks via Denoising and Compression
Apr 03, 2021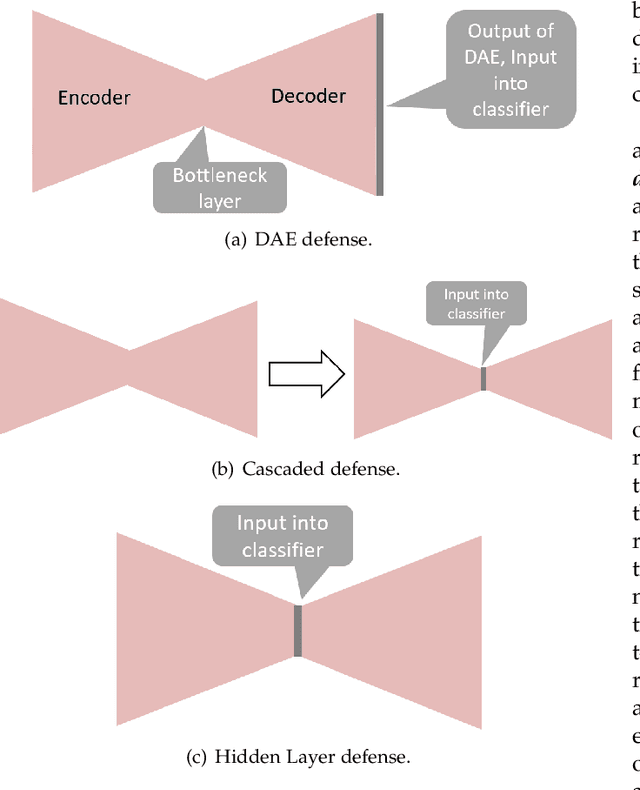
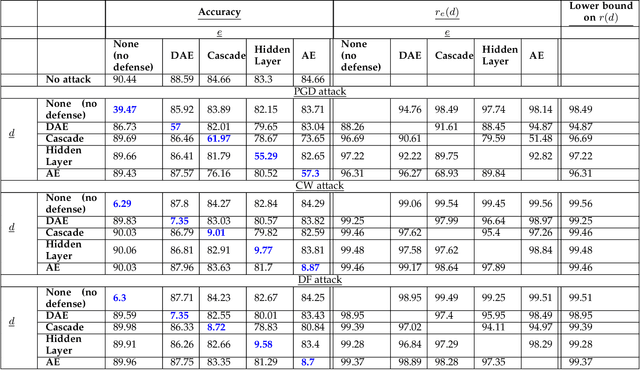

Gradient-based adversarial attacks on deep neural networks pose a serious threat, since they can be deployed by adding imperceptible perturbations to the test data of any network, and the risk they introduce cannot be assessed through the network's original training performance. Denoising and dimensionality reduction are two distinct methods that have been independently investigated to combat such attacks. While denoising offers the ability to tailor the defense to the specific nature of the attack, dimensionality reduction offers the advantage of potentially removing previously unseen perturbations, along with reducing the training time of the network being defended. We propose strategies to combine the advantages of these two defense mechanisms. First, we propose the cascaded defense, which involves denoising followed by dimensionality reduction. To reduce the training time of the defense for a small trade-off in performance, we propose the hidden layer defense, which involves feeding the output of the encoder of a denoising autoencoder into the network. Further, we discuss how adaptive attacks against these defenses could become significantly weak when an alternative defense is used, or when no defense is used. In this light, we propose a new metric to evaluate a defense which measures the sensitivity of the adaptive attack to modifications in the defense. Finally, we present a guideline for building an ordered repertoire of defenses, a.k.a. a defense infrastructure, that adjusts to limited computational resources in presence of uncertainty about the attack strategy.
Ensemble Noise Simulation to Handle Uncertainty about Gradient-based Adversarial Attacks
Jan 26, 2020

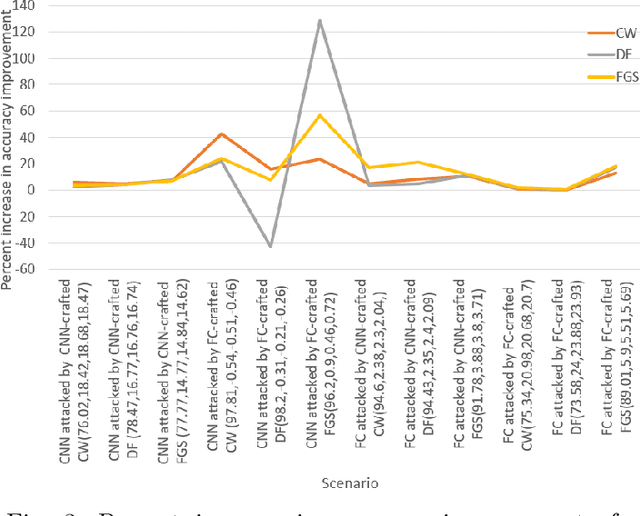
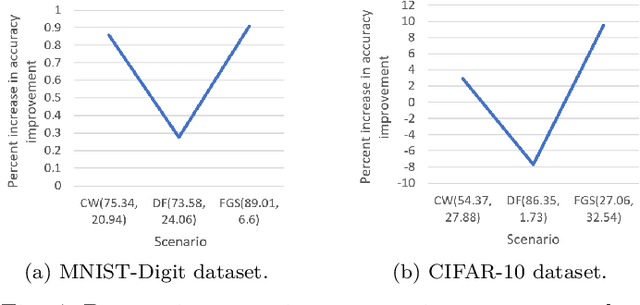
Gradient-based adversarial attacks on neural networks can be crafted in a variety of ways by varying either how the attack algorithm relies on the gradient, the network architecture used for crafting the attack, or both. Most recent work has focused on defending classifiers in a case where there is no uncertainty about the attacker's behavior (i.e., the attacker is expected to generate a specific attack using a specific network architecture). However, if the attacker is not guaranteed to behave in a certain way, the literature lacks methods in devising a strategic defense. We fill this gap by simulating the attacker's noisy perturbation using a variety of attack algorithms based on gradients of various classifiers. We perform our analysis using a pre-processing Denoising Autoencoder (DAE) defense that is trained with the simulated noise. We demonstrate significant improvements in post-attack accuracy, using our proposed ensemble-trained defense, compared to a situation where no effort is made to handle uncertainty.
A Computationally Efficient Method for Defending Adversarial Deep Learning Attacks
Jun 13, 2019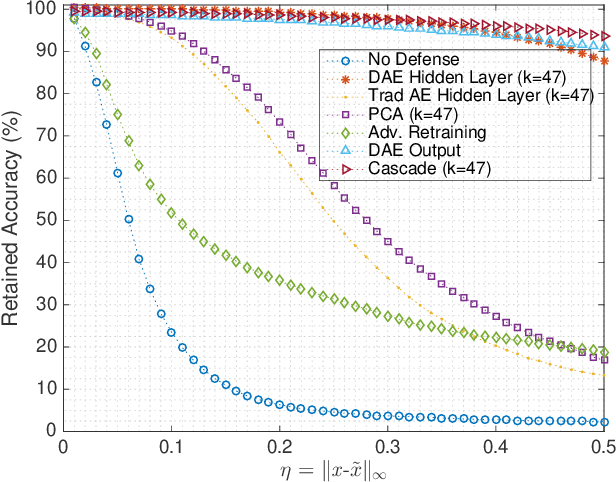
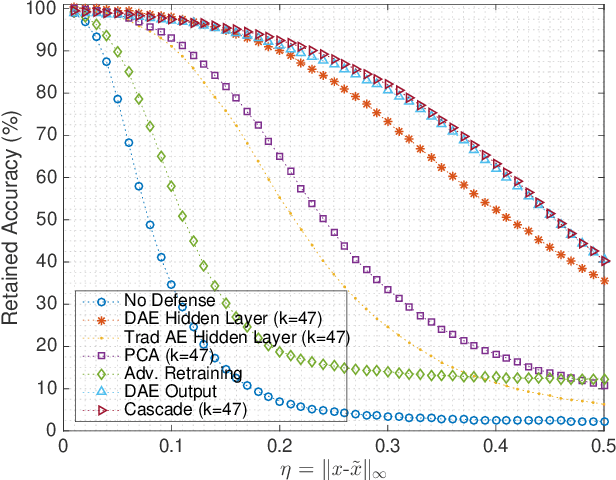
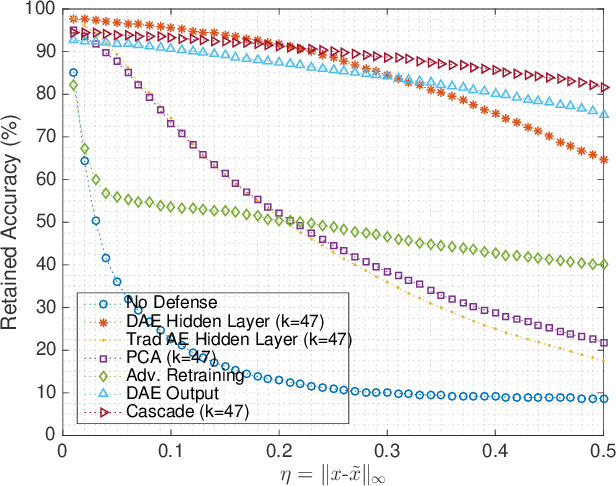
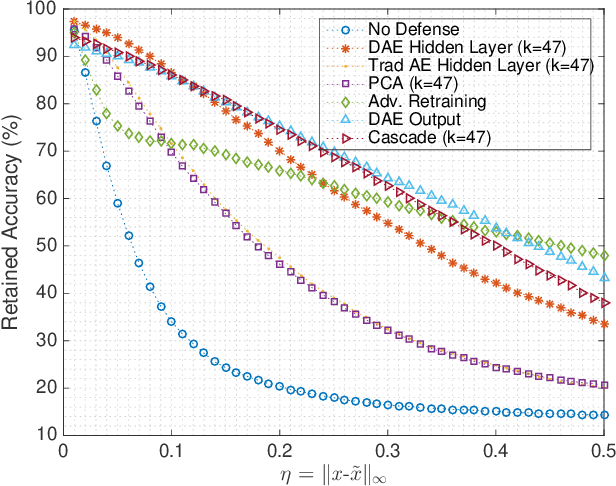
The reliance on deep learning algorithms has grown significantly in recent years. Yet, these models are highly vulnerable to adversarial attacks, which introduce visually imperceptible perturbations into testing data to induce misclassifications. The literature has proposed several methods to combat such adversarial attacks, but each method either fails at high perturbation values, requires excessive computing power, or both. This letter proposes a computationally efficient method for defending the Fast Gradient Sign (FGS) adversarial attack by simultaneously denoising and compressing data. Specifically, our proposed defense relies on training a fully connected multi-layer Denoising Autoencoder (DAE) and using its encoder as a defense against the adversarial attack. Our results show that using this dimensionality reduction scheme is not only highly effective in mitigating the effect of the FGS attack in multiple threat models, but it also provides a 2.43x speedup in comparison to defense strategies providing similar robustness against the same attack.
Combatting Adversarial Attacks through Denoising and Dimensionality Reduction: A Cascaded Autoencoder Approach
Dec 07, 2018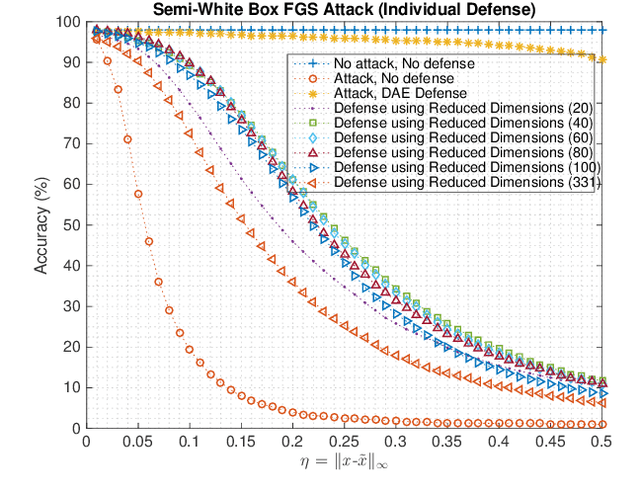
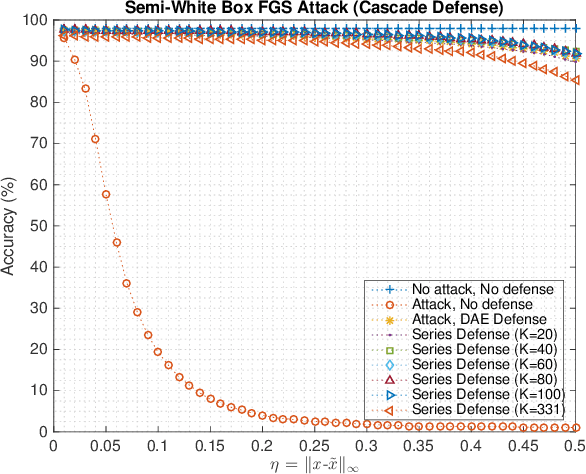
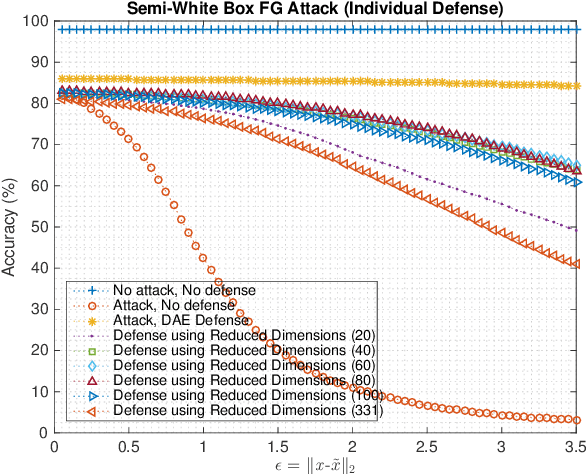
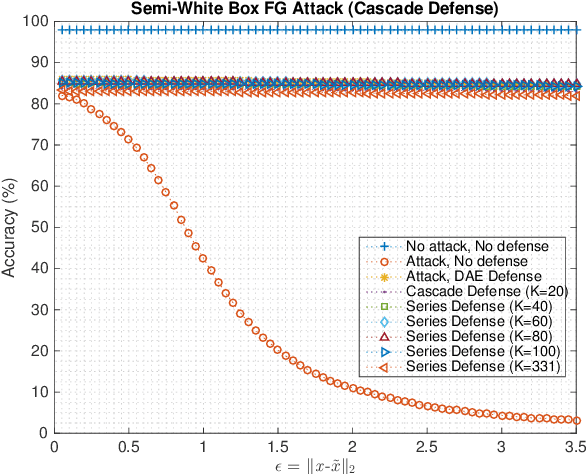
Machine Learning models are vulnerable to adversarial attacks that rely on perturbing the input data. This work proposes a novel strategy using Autoencoder Deep Neural Networks to defend a machine learning model against two gradient-based attacks: The Fast Gradient Sign attack and Fast Gradient attack. First we use an autoencoder to denoise the test data, which is trained with both clean and corrupted data. Then, we reduce the dimension of the denoised data using the hidden layer representation of another autoencoder. We perform this experiment for multiple values of the bound of adversarial perturbations, and consider different numbers of reduced dimensions. When the test data is preprocessed using this cascaded pipeline, the tested deep neural network classifier yields a much higher accuracy, thus mitigating the effect of the adversarial perturbation.