 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Audio Question Answering and Reasoning on Dynamic Source Movements
Feb 18, 2026Spatial audio understanding aims to enable machines to interpret complex auditory scenes, particularly when sound sources move over time. In this work, we study Spatial Audio Question Answering (Spatial AQA) with a focus on movement reasoning, where a model must infer object motion, position, and directional changes directly from stereo audio. First, we introduce a movement-centric spatial audio augmentation framework that synthesizes diverse motion patterns from isolated mono audio events, enabling controlled and scalable training data generation. Second, we propose an end-to-end multimodal finetuning approach with a thinking mode, which allows audio-language models to produce explicit intermediate reasoning steps before predicting an answer. Third, we investigate the impact of query-conditioned source separation as a preprocessing stage and compare three inference regimes: no masking, an audio grounding model (AGM), and ground-truth masks. Our results show that reasoning amplifies the benefits of source separation, with thinking mode showing significant improvement of +5.1% when a single event is present in the question. These findings highlight the interplay between movement modeling, reasoning, and separation quality, offering new insights for advancing spatial audio understanding.
LongAudio-RAG: Event-Grounded Question Answering over Multi-Hour Long Audio
Feb 16, 2026Long-duration audio is increasingly common in industrial and consumer settings, yet reviewing multi-hour recordings is impractical, motivating systems that answer natural-language queries with precise temporal grounding and minimal hallucination. Existing audio-language models show promise, but long-audio question answering remains difficult due to context-length limits. We introduce LongAudio-RAG (LA-RAG), a hybrid framework that grounds Large Language Model (LLM) outputs in retrieved, timestamped acoustic event detections rather than raw audio. Multi-hour streams are converted into structured event records stored in an SQL database, and at inference time the system resolves natural-language time references, classifies intent, retrieves only the relevant events, and generates answers using this constrained evidence. To evaluate performance, we construct a synthetic long-audio benchmark by concatenating recordings with preserved timestamps and generating template-based question-answer pairs for detection, counting, and summarization tasks. Finally, we demonstrate the practicality of our approach by deploying it in a hybrid edge-cloud environment, where the audio grounding model runs on-device on IoT-class hardware while the LLM is hosted on a GPU-backed server. This architecture enables low-latency event extraction at the edge and high-quality language reasoning in the cloud. Experiments show that structured, event-level retrieval significantly improves accuracy compared to vanilla Retrieval-Augmented Generation (RAG) or text-to-SQL approaches.
Spatial Audio Motion Understanding and Reasoning
Sep 18, 2025Spatial audio reasoning enables machines to interpret auditory scenes by understanding events and their spatial attributes. In this work, we focus on spatial audio understanding with an emphasis on reasoning about moving sources. First, we introduce a spatial audio encoder that processes spatial audio to detect multiple overlapping events and estimate their spatial attributes, Direction of Arrival (DoA) and source distance, at the frame level. To generalize to unseen events, we incorporate an audio grounding model that aligns audio features with semantic audio class text embeddings via a cross-attention mechanism. Second, to answer complex queries about dynamic audio scenes involving moving sources, we condition a large language model (LLM) on structured spatial attributes extracted by our model. Finally, we introduce a spatial audio motion understanding and reasoning benchmark dataset and demonstrate our framework's performance against the baseline model.
Comprehensive Audio Query Handling System with Integrated Expert Models and Contextual Understanding
Dec 05, 2024



This paper presents a comprehensive chatbot system designed to handle a wide range of audio-related queries by integrating multiple specialized audio processing models. The proposed system uses an intent classifier, trained on a diverse audio query dataset, to route queries about audio content to expert models such as Automatic Speech Recognition (ASR), Speaker Diarization, Music Identification, and Text-to-Audio generation. A 3.8 B LLM model then takes inputs from an Audio Context Detection (ACD) module extracting audio event information from the audio and post processes text domain outputs from the expert models to compute the final response to the user. We evaluated the system on custom audio tasks and MMAU sound set benchmarks. The custom datasets were motivated by target use cases not covered in industry benchmarks and included ACD-timestamp-QA (Question Answering) as well as ACD-temporal-QA datasets to evaluate timestamp and temporal reasoning questions, respectively. First we determined that a BERT based Intent Classifier outperforms LLM-fewshot intent classifier in routing queries. Experiments further show that our approach significantly improves accuracy on some custom tasks compared to state-of-the-art Large Audio Language Models and outperforms models in the 7B parameter size range on the sound testset of the MMAU benchmark, thereby offering an attractive option for on device deployment.
Enhancing Temporal Understanding in Audio Question Answering for Large Audio Language Models
Sep 10, 2024The Audio Question Answering task includes audio event classification, audio captioning, and open ended reasoning. Recently, Audio Question Answering has garnered attention due to the advent of Large Audio Language Models. Current literature focuses on constructing LALMs by integrating audio encoders with text only Large Language Models through a projection module. While Large Audio Language Models excel in general audio understanding, they are limited in temporal reasoning which may hinder their commercial applications and on device deployment. This paper addresses these challenges and limitations in audio temporal reasoning. First, we introduce a data augmentation technique for generating reliable audio temporal questions and answers using an LLM. Second, we propose a continued finetuning curriculum learning strategy to specialize in temporal reasoning without compromising performance on finetuned tasks. Finally, we develop a reliable and transparent automated metric, assisted by an LLM, to measure the correlation between Large Audio Language Model responses and ground truth data intelligently. We demonstrate the effectiveness of our proposed techniques using SOTA LALMs on public audio benchmark datasets.
Parameter Efficient Audio Captioning With Faithful Guidance Using Audio-text Shared Latent Representation
Sep 06, 2023
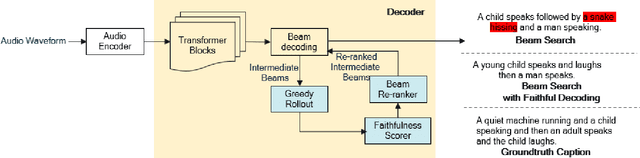


There has been significant research on developing pretrained transformer architectures for multimodal-to-text generation tasks. Albeit performance improvements, such models are frequently overparameterized, hence suffer from hallucination and large memory footprint making them challenging to deploy on edge devices. In this paper, we address both these issues for the application of automated audio captioning. First, we propose a data augmentation technique for generating hallucinated audio captions and show that similarity based on an audio-text shared latent space is suitable for detecting hallucination. Then, we propose a parameter efficient inference time faithful decoding algorithm that enables smaller audio captioning models with performance equivalent to larger models trained with more data. During the beam decoding step, the smaller model utilizes an audio-text shared latent representation to semantically align the generated text with corresponding input audio. Faithful guidance is introduced into the beam probability by incorporating the cosine similarity between latent representation projections of greedy rolled out intermediate beams and audio clip. We show the efficacy of our algorithm on benchmark datasets and evaluate the proposed scheme against baselines using conventional audio captioning and semantic similarity metrics while illustrating tradeoffs between performance and complexity.
Improved Beam Search for Hallucination Mitigation in Abstractive Summarization
Dec 06, 2022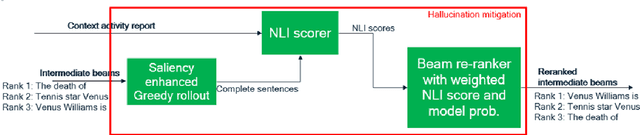
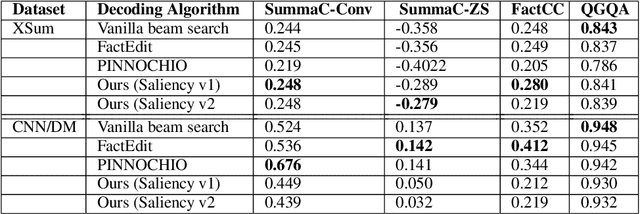

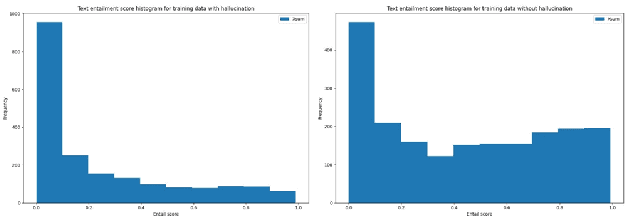
Advancement in large pretrained language models has significantly improved their performance for conditional language generation tasks including summarization albeit with hallucinations. To reduce hallucinations, conventional methods proposed improving beam search or using a fact checker as a postprocessing step. In this paper, we investigate the use of the Natural Language Inference (NLI) entailment metric to detect and prevent hallucinations in summary generation. We propose an NLI-assisted beam re-ranking mechanism by computing entailment probability scores between the input context and summarization model-generated beams during saliency-enhanced greedy decoding. Moreover, a diversity metric is introduced to compare its effectiveness against vanilla beam search. Our proposed algorithm significantly outperforms vanilla beam decoding on XSum and CNN/DM datasets.
Activity report analysis with automatic single or multispan answer extraction
Sep 09, 2022
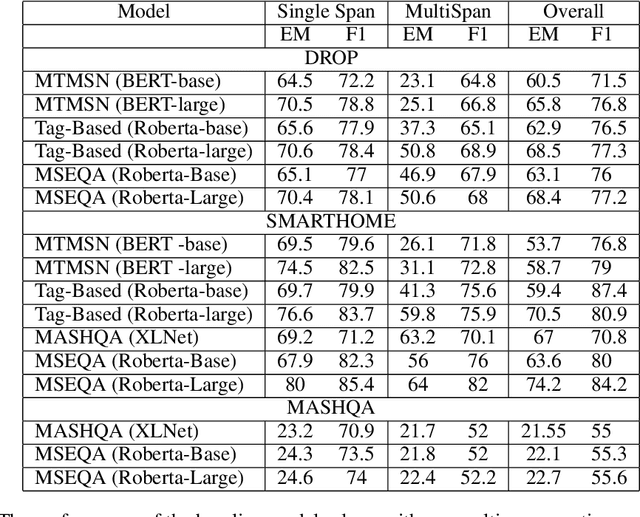
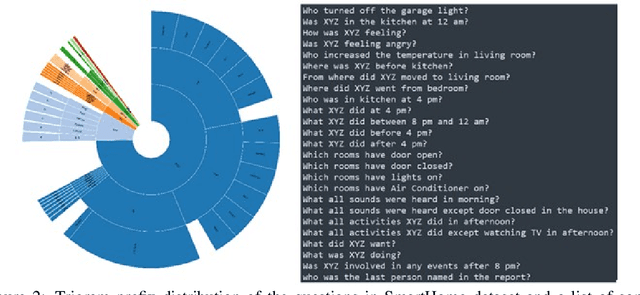
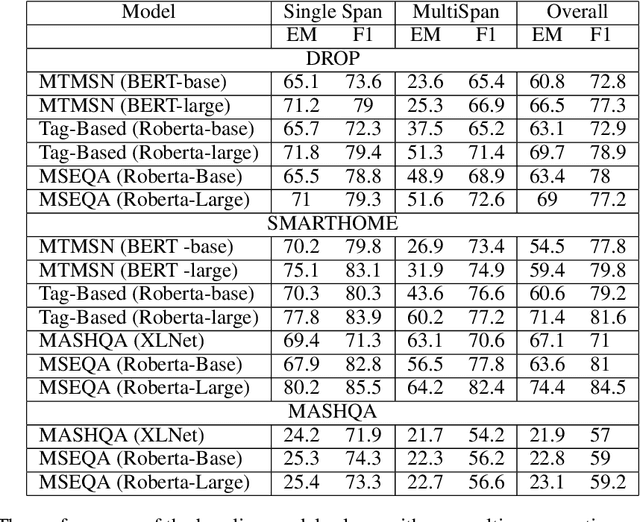
In the era of loT (Internet of Things) we are surrounded by a plethora of Al enabled devices that can transcribe images, video, audio, and sensors signals into text descriptions. When such transcriptions are captured in activity reports for monitoring, life logging and anomaly detection applications, a user would typically request a summary or ask targeted questions about certain sections of the report they are interested in. Depending on the context and the type of question asked, a question answering (QA) system would need to automatically determine whether the answer covers single-span or multi-span text components. Currently available QA datasets primarily focus on single span responses only (such as SQuAD[4]) or contain a low proportion of examples with multiple span answers (such as DROP[3]). To investigate automatic selection of single/multi-span answers in the use case described, we created a new smart home environment dataset comprised of questions paired with single-span or multi-span answers depending on the question and context queried. In addition, we propose a RoBERTa[6]-based multiple span extraction question answering (MSEQA) model returning the appropriate answer span for a given question. Our experiments show that the proposed model outperforms state-of-the-art QA models on our dataset while providing comparable performance on published individual single/multi-span task datasets.