 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Audio Question Answering and Reasoning on Dynamic Source Movements
Feb 18, 2026Spatial audio understanding aims to enable machines to interpret complex auditory scenes, particularly when sound sources move over time. In this work, we study Spatial Audio Question Answering (Spatial AQA) with a focus on movement reasoning, where a model must infer object motion, position, and directional changes directly from stereo audio. First, we introduce a movement-centric spatial audio augmentation framework that synthesizes diverse motion patterns from isolated mono audio events, enabling controlled and scalable training data generation. Second, we propose an end-to-end multimodal finetuning approach with a thinking mode, which allows audio-language models to produce explicit intermediate reasoning steps before predicting an answer. Third, we investigate the impact of query-conditioned source separation as a preprocessing stage and compare three inference regimes: no masking, an audio grounding model (AGM), and ground-truth masks. Our results show that reasoning amplifies the benefits of source separation, with thinking mode showing significant improvement of +5.1% when a single event is present in the question. These findings highlight the interplay between movement modeling, reasoning, and separation quality, offering new insights for advancing spatial audio understanding.
Proactive Conversational Assistant for a Procedural Manual Task based on Audio and IMU
Feb 17, 2026Real-time conversational assistants for procedural tasks often depend on video input, which can be computationally expensive and compromise user privacy. For the first time, we propose a real-time conversational assistant that provides comprehensive guidance for a procedural task using only lightweight privacy-preserving modalities such as audio and IMU inputs from a user's wearable device to understand the context. This assistant proactively communicates step-by-step instructions to a user performing a furniture assembly task, and answers user questions. We construct a dataset containing conversations where the assistant guides the user in performing the task. On observing that an off-the-shelf language model is a very talkative assistant, we design a novel User Whim Agnostic (UWA) LoRA finetuning method which improves the model's ability to suppress less informative dialogues, while maintaining its tendency to communicate important instructions. This leads to >30% improvement in the F-score. Finetuning the model also results in a 16x speedup by eliminating the need to provide in-context examples in the prompt. We further describe how such an assistant is implemented on edge devices with no dependence on the cloud.
LongAudio-RAG: Event-Grounded Question Answering over Multi-Hour Long Audio
Feb 16, 2026Long-duration audio is increasingly common in industrial and consumer settings, yet reviewing multi-hour recordings is impractical, motivating systems that answer natural-language queries with precise temporal grounding and minimal hallucination. Existing audio-language models show promise, but long-audio question answering remains difficult due to context-length limits. We introduce LongAudio-RAG (LA-RAG), a hybrid framework that grounds Large Language Model (LLM) outputs in retrieved, timestamped acoustic event detections rather than raw audio. Multi-hour streams are converted into structured event records stored in an SQL database, and at inference time the system resolves natural-language time references, classifies intent, retrieves only the relevant events, and generates answers using this constrained evidence. To evaluate performance, we construct a synthetic long-audio benchmark by concatenating recordings with preserved timestamps and generating template-based question-answer pairs for detection, counting, and summarization tasks. Finally, we demonstrate the practicality of our approach by deploying it in a hybrid edge-cloud environment, where the audio grounding model runs on-device on IoT-class hardware while the LLM is hosted on a GPU-backed server. This architecture enables low-latency event extraction at the edge and high-quality language reasoning in the cloud. Experiments show that structured, event-level retrieval significantly improves accuracy compared to vanilla Retrieval-Augmented Generation (RAG) or text-to-SQL approaches.
Mitigating Intra-Speaker Variability in Diarization with Style-Controllable Speech Augmentation
Sep 18, 2025Speaker diarization systems often struggle with high intrinsic intra-speaker variability, such as shifts in emotion, health, or content. This can cause segments from the same speaker to be misclassified as different individuals, for example, when one raises their voice or speaks faster during conversation. To address this, we propose a style-controllable speech generation model that augments speech across diverse styles while preserving the target speaker's identity. The proposed system starts with diarized segments from a conventional diarizer. For each diarized segment, it generates augmented speech samples enriched with phonetic and stylistic diversity. And then, speaker embeddings from both the original and generated audio are blended to enhance the system's robustness in grouping segments with high intrinsic intra-speaker variability. We validate our approach on a simulated emotional speech dataset and the truncated AMI dataset, demonstrating significant improvements, with error rate reductions of 49% and 35% on each dataset, respectively.
Spatial Audio Motion Understanding and Reasoning
Sep 18, 2025Spatial audio reasoning enables machines to interpret auditory scenes by understanding events and their spatial attributes. In this work, we focus on spatial audio understanding with an emphasis on reasoning about moving sources. First, we introduce a spatial audio encoder that processes spatial audio to detect multiple overlapping events and estimate their spatial attributes, Direction of Arrival (DoA) and source distance, at the frame level. To generalize to unseen events, we incorporate an audio grounding model that aligns audio features with semantic audio class text embeddings via a cross-attention mechanism. Second, to answer complex queries about dynamic audio scenes involving moving sources, we condition a large language model (LLM) on structured spatial attributes extracted by our model. Finally, we introduce a spatial audio motion understanding and reasoning benchmark dataset and demonstrate our framework's performance against the baseline model.
Aligning Audio Captions with Human Preferences
Sep 18, 2025Current audio captioning systems rely heavily on supervised learning with paired audio-caption datasets, which are expensive to curate and may not reflect human preferences in real-world scenarios. To address this limitation, we propose a preference-aligned audio captioning framework based on Reinforcement Learning from Human Feedback (RLHF). To effectively capture nuanced human preferences, we train a Contrastive Language-Audio Pretraining (CLAP)-based reward model using human-labeled pairwise preference data. This reward model is integrated into a reinforcement learning framework to fine-tune any baseline captioning system without relying on ground-truth caption annotations. Extensive human evaluations across multiple datasets show that our method produces captions preferred over those from baseline models, particularly in cases where the baseline models fail to provide correct and natural captions. Furthermore, our framework achieves performance comparable to supervised approaches with ground-truth data, demonstrating its effectiveness in aligning audio captioning with human preferences and its scalability in real-world scenarios.
Voice-ENHANCE: Speech Restoration using a Diffusion-based Voice Conversion Framework
May 21, 2025



We propose a speech enhancement system that combines speaker-agnostic speech restoration with voice conversion (VC) to obtain a studio-level quality speech signal. While voice conversion models are typically used to change speaker characteristics, they can also serve as a means of speech restoration when the target speaker is the same as the source speaker. However, since VC models are vulnerable to noisy conditions, we have included a generative speech restoration (GSR) model at the front end of our proposed system. The GSR model performs noise suppression and restores speech damage incurred during that process without knowledge about the target speaker. The VC stage then uses guidance from clean speaker embeddings to further restore the output speech. By employing this two-stage approach, we have achieved speech quality objective metric scores comparable to state-of-the-art (SOTA) methods across multiple datasets.
Comprehensive Audio Query Handling System with Integrated Expert Models and Contextual Understanding
Dec 05, 2024



This paper presents a comprehensive chatbot system designed to handle a wide range of audio-related queries by integrating multiple specialized audio processing models. The proposed system uses an intent classifier, trained on a diverse audio query dataset, to route queries about audio content to expert models such as Automatic Speech Recognition (ASR), Speaker Diarization, Music Identification, and Text-to-Audio generation. A 3.8 B LLM model then takes inputs from an Audio Context Detection (ACD) module extracting audio event information from the audio and post processes text domain outputs from the expert models to compute the final response to the user. We evaluated the system on custom audio tasks and MMAU sound set benchmarks. The custom datasets were motivated by target use cases not covered in industry benchmarks and included ACD-timestamp-QA (Question Answering) as well as ACD-temporal-QA datasets to evaluate timestamp and temporal reasoning questions, respectively. First we determined that a BERT based Intent Classifier outperforms LLM-fewshot intent classifier in routing queries. Experiments further show that our approach significantly improves accuracy on some custom tasks compared to state-of-the-art Large Audio Language Models and outperforms models in the 7B parameter size range on the sound testset of the MMAU benchmark, thereby offering an attractive option for on device deployment.
Confidence Calibration for Audio Captioning Models
Sep 13, 2024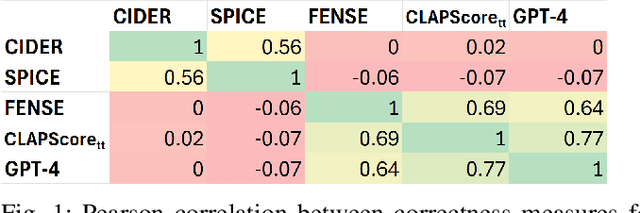
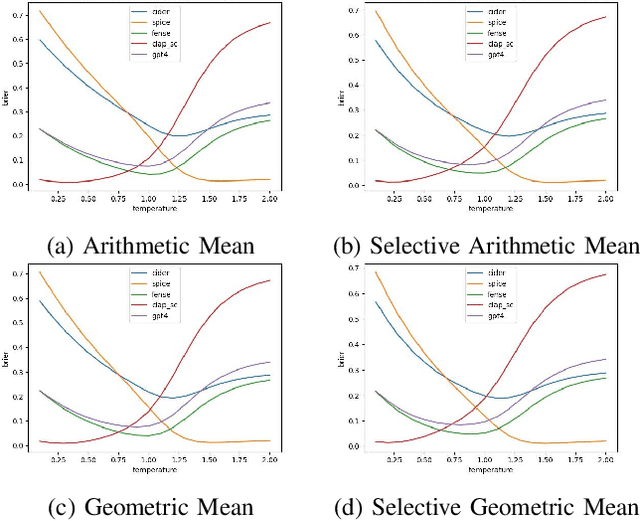
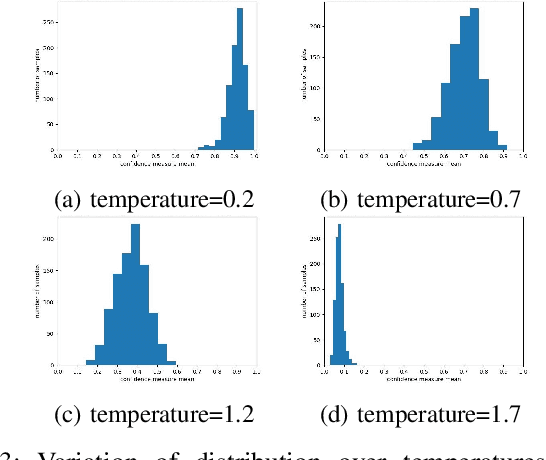
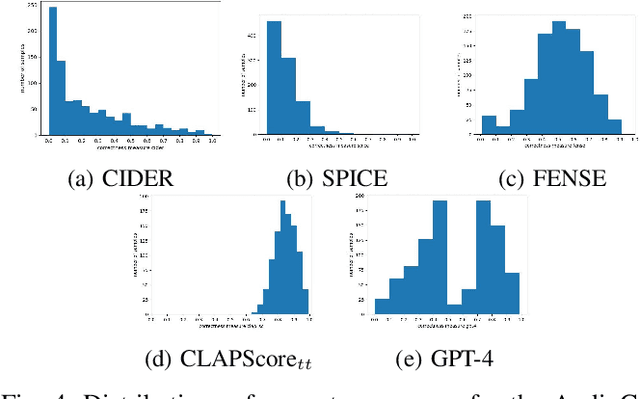
Systems that automatically generate text captions for audio, images and video lack a confidence indicator of the relevance and correctness of the generated sequences. To address this, we build on existing methods of confidence measurement for text by introduce selective pooling of token probabilities, which aligns better with traditional correctness measures than conventional pooling does. Further, we propose directly measuring the similarity between input audio and text in a shared embedding space. To measure self-consistency, we adapt semantic entropy for audio captioning, and find that these two methods align even better than pooling-based metrics with the correctness measure that calculates acoustic similarity between captions. Finally, we explain why temperature scaling of confidences improves calibration.
Enhancing Temporal Understanding in Audio Question Answering for Large Audio Language Models
Sep 10, 2024The Audio Question Answering task includes audio event classification, audio captioning, and open ended reasoning. Recently, Audio Question Answering has garnered attention due to the advent of Large Audio Language Models. Current literature focuses on constructing LALMs by integrating audio encoders with text only Large Language Models through a projection module. While Large Audio Language Models excel in general audio understanding, they are limited in temporal reasoning which may hinder their commercial applications and on device deployment. This paper addresses these challenges and limitations in audio temporal reasoning. First, we introduce a data augmentation technique for generating reliable audio temporal questions and answers using an LLM. Second, we propose a continued finetuning curriculum learning strategy to specialize in temporal reasoning without compromising performance on finetuned tasks. Finally, we develop a reliable and transparent automated metric, assisted by an LLM, to measure the correlation between Large Audio Language Model responses and ground truth data intelligently. We demonstrate the effectiveness of our proposed techniques using SOTA LALMs on public audio benchmark datasets.