 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Intra-Speaker Variability in Diarization with Style-Controllable Speech Augmentation
Sep 18, 2025Speaker diarization systems often struggle with high intrinsic intra-speaker variability, such as shifts in emotion, health, or content. This can cause segments from the same speaker to be misclassified as different individuals, for example, when one raises their voice or speaks faster during conversation. To address this, we propose a style-controllable speech generation model that augments speech across diverse styles while preserving the target speaker's identity. The proposed system starts with diarized segments from a conventional diarizer. For each diarized segment, it generates augmented speech samples enriched with phonetic and stylistic diversity. And then, speaker embeddings from both the original and generated audio are blended to enhance the system's robustness in grouping segments with high intrinsic intra-speaker variability. We validate our approach on a simulated emotional speech dataset and the truncated AMI dataset, demonstrating significant improvements, with error rate reductions of 49% and 35% on each dataset, respectively.
Deep learning radiomics for assessment of gastroesophageal varices in people with compensated advanced chronic liver disease
Jun 13, 2023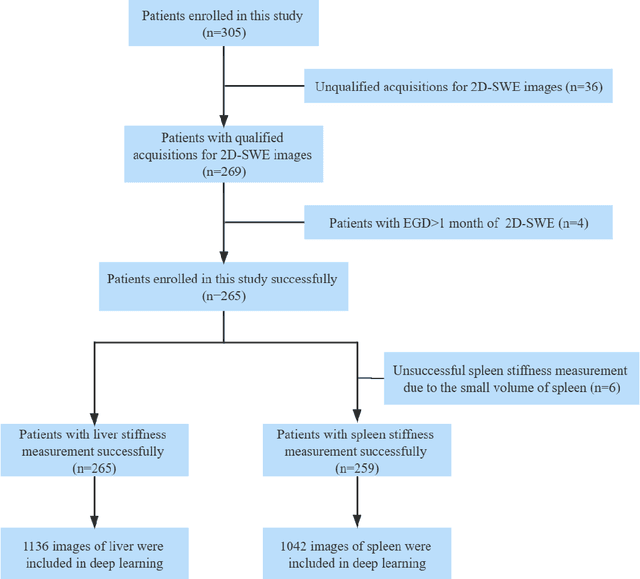
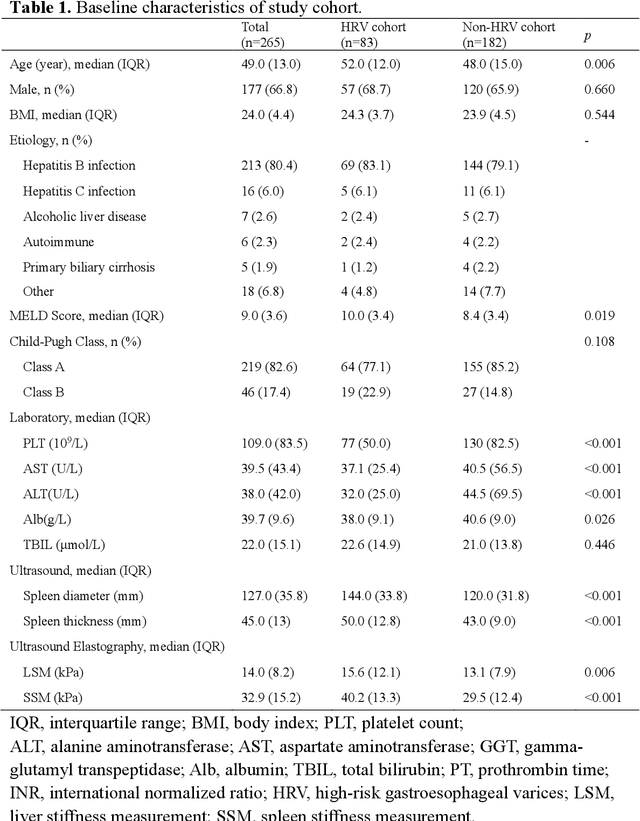
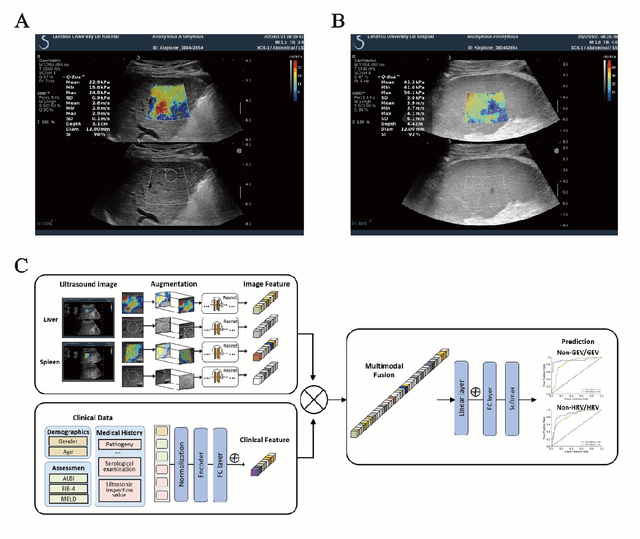
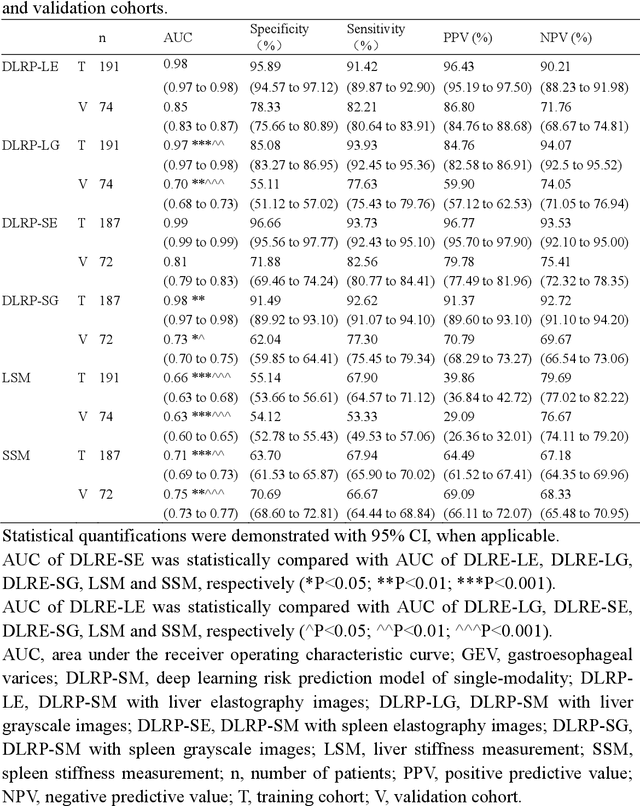
Objective: Bleeding from gastroesophageal varices (GEV) is a medical emergency associated with high mortality. We aim to construct an artificial intelligence-based model of two-dimensional shear wave elastography (2D-SWE) of the liver and spleen to precisely assess the risk of GEV and high-risk gastroesophageal varices (HRV). Design: A prospective multicenter study was conducted in patients with compensated advanced chronic liver disease. 305 patients were enrolled from 12 hospitals, and finally 265 patients were included, with 1136 liver stiffness measurement (LSM) images and 1042 spleen stiffness measurement (SSM) images generated by 2D-SWE. We leveraged deep learning methods to uncover associations between image features and patient risk, and thus conducted models to predict GEV and HRV. Results: A multi-modality Deep Learning Risk Prediction model (DLRP) was constructed to assess GEV and HRV, based on LSM and SSM images, and clinical information. Validation analysis revealed that the AUCs of DLRP were 0.91 for GEV (95% CI 0.90 to 0.93, p < 0.05) and 0.88 for HRV (95% CI 0.86 to 0.89, p < 0.01), which were significantly and robustly better than canonical risk indicators, including the value of LSM and SSM. Moreover, DLPR was better than the model using individual parameters, including LSM and SSM images. In HRV prediction, the 2D-SWE images of SSM outperform LSM (p < 0.01). Conclusion: DLRP shows excellent performance in predicting GEV and HRV over canonical risk indicators LSM and SSM. Additionally, the 2D-SWE images of SSM provided more information for better accuracy in predicting HRV than the LSM.
Application of Knowledge Distillation to Multi-task Speech Representation Learning
Oct 29, 2022Model architectures such as wav2vec 2.0 and HuBERT have been proposed to learn speech representations from audio waveforms in a self-supervised manner. When these models are combined with downstream tasks such as speech recognition, they have been shown to provide state-of-the-art performance. However, these models use a large number of parameters, the smallest version of which has about 95 million parameters. This constitutes a challenge for edge AI device deployments. In this paper, we use knowledge distillation to reduce the original model size by about 75% while maintaining similar performance levels. Moreover, we use wav2vec 2.0 and HuBERT models for distillation and present a comprehensive performance analysis through our experiments where we fine-tune the distilled models on single task and multi-task frameworks separately. In particular, our experiments show that fine-tuning the distilled models on keyword spotting and speaker verification tasks result in only 0.1% accuracy and 0.9% equal error rate degradations, respectively.
Multi-task Voice Activated Framework using Self-supervised Learning
Oct 12, 2021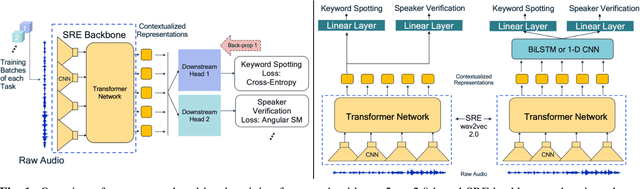
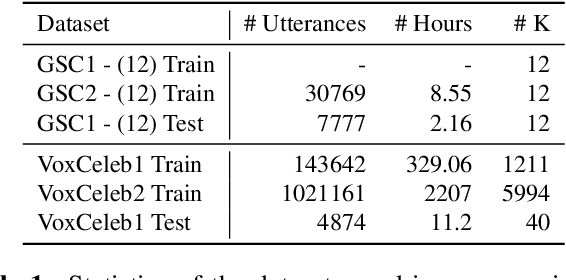
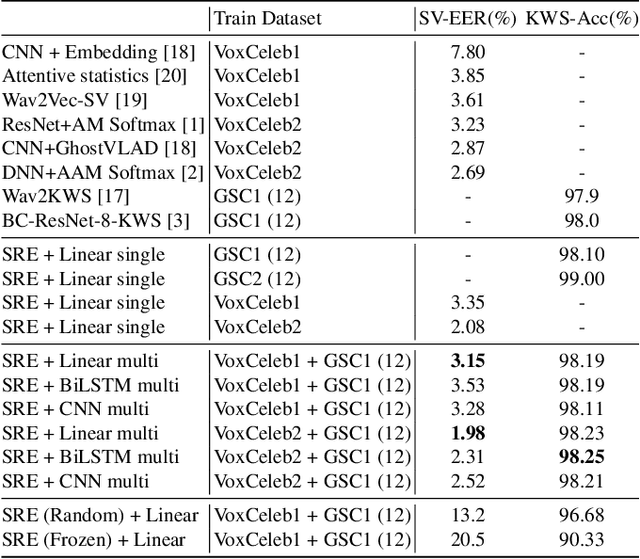
Self-supervised learning methods such as wav2vec 2.0 have shown promising results in learning speech representations from unlabelled and untranscribed speech data that are useful for speech recognition. Since these representations are learned without any task-specific supervision, they can also be useful for other voice-activated tasks like speaker verification, keyword spotting, emotion classification etc. In our work, we propose a general purpose framework for adapting a pre-trained wav2vec 2.0 model for different voice-activated tasks. We develop downstream network architectures that operate on the contextualized speech representations of wav2vec 2.0 to adapt the representations for solving a given task. Finally, we extend our framework to perform multi-task learning by jointly optimizing the network parameters on multiple voice activated tasks using a shared transformer backbone. Both of our single and multi-task frameworks achieve state-of-the-art results in speaker verification and keyword spotting benchmarks. Our best performing models achieve 1.98% and 3.15% EER on VoxCeleb1 test set when trained on VoxCeleb2 and VoxCeleb1 respectively, and 98.23% accuracy on Google Speech Commands v1.0 keyword spotting dataset.
Character Distributions of Classical Chinese Literary Texts: Zipf's Law, Genres, and Epochs
Sep 17, 2017
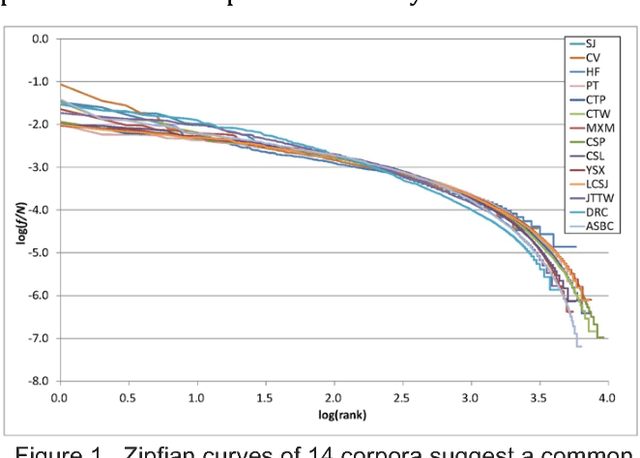
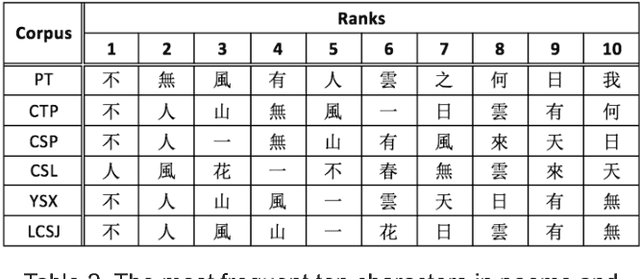
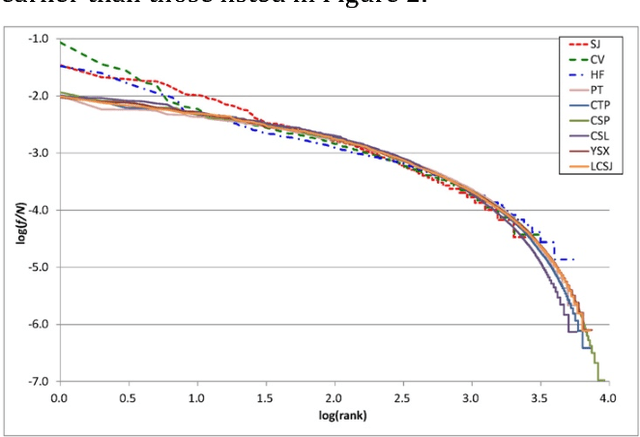
We collect 14 representative corpora for major periods in Chinese history in this study. These corpora include poetic works produced in several dynasties, novels of the Ming and Qing dynasties, and essays and news reports written in modern Chinese. The time span of these corpora ranges between 1046 BCE and 2007 CE. We analyze their character and word distributions from the viewpoint of the Zipf's law, and look for factors that affect the deviations and similarities between their Zipfian curves. Genres and epochs demonstrated their influences in our analyses. Specifically, the character distributions for poetic works of between 618 CE and 1644 CE exhibit striking similarity. In addition, although texts of the same dynasty may tend to use the same set of characters, their character distributions still deviate from each other.