 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Distributions of Classical Chinese Literary Texts: Zipf's Law, Genres, and Epochs
Sep 17, 2017
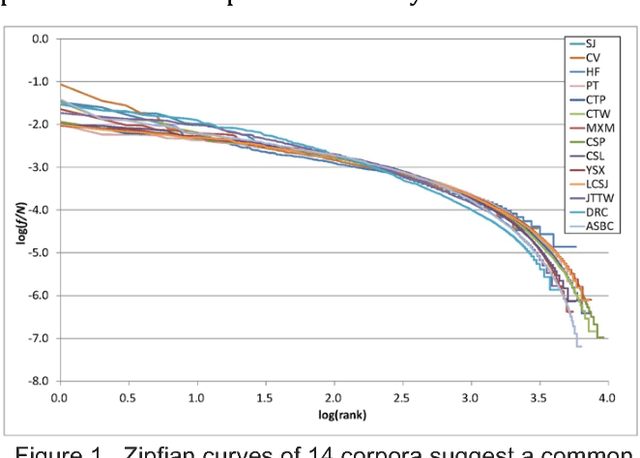
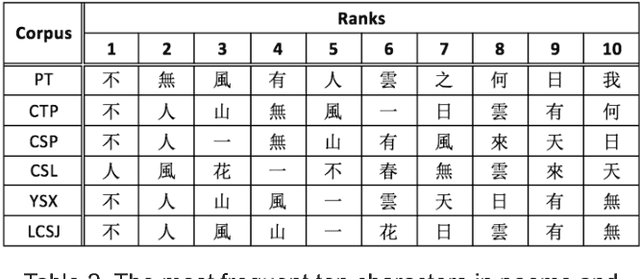
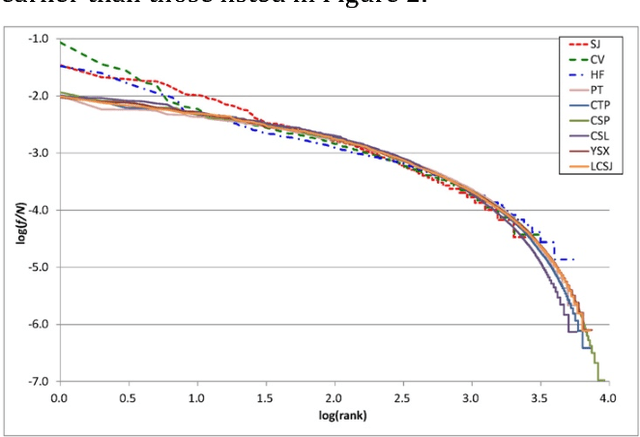
We collect 14 representative corpora for major periods in Chinese history in this study. These corpora include poetic works produced in several dynasties, novels of the Ming and Qing dynasties, and essays and news reports written in modern Chinese. The time span of these corpora ranges between 1046 BCE and 2007 CE. We analyze their character and word distributions from the viewpoint of the Zipf's law, and look for factors that affect the deviations and similarities between their Zipfian curves. Genres and epochs demonstrated their influences in our analyses. Specifically, the character distributions for poetic works of between 618 CE and 1644 CE exhibit striking similarity. In addition, although texts of the same dynasty may tend to use the same set of characters, their character distributions still deviate from each other.
Matrix and Graph Operations for Relationship Inference: An Illustration with the Kinship Inference in the China Biographical Database
Sep 09, 2017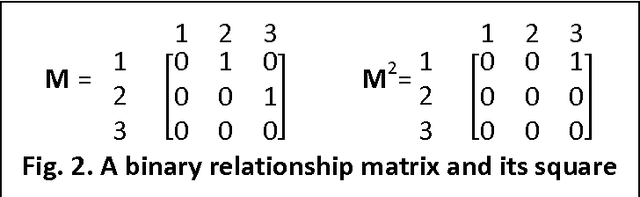
Biographical databases contain diverse information about individuals. Person names, birth information, career, friends, family and special achievements are some possible items in the record for an individual. The relationships between individuals, such as kinship and friendship, provide invaluable insights about hidden communities which are not directly recorded in databases. We show that some simple matrix and graph-based operations are effective for inferring relationships among individuals, and illustrate the main ideas with the China Biographical Database (CBDB).
Color Aesthetics and Social Networks in Complete Tang Poems: Explorations and Discoveries
Nov 05, 2015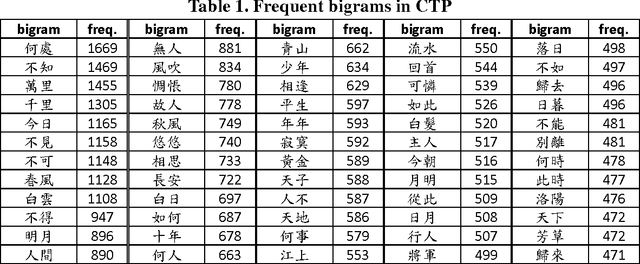
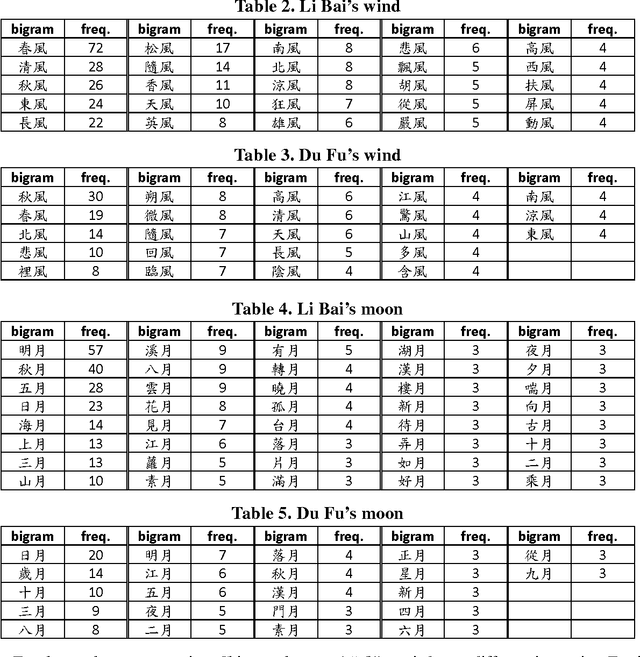
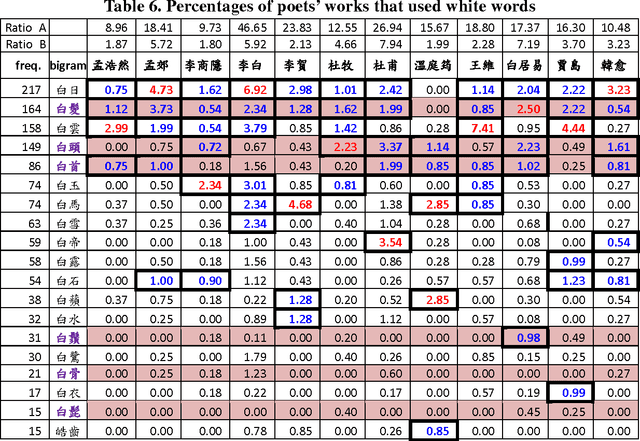
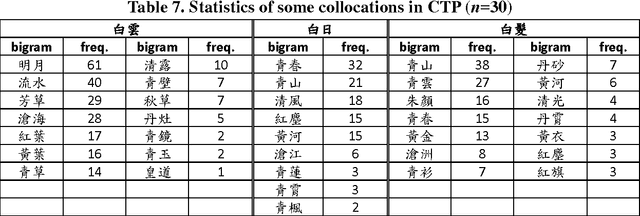
The Complete Tang Poems (CTP) is the most important source to study Tang poems. We look into CTP with computational tools from specific linguistic perspectives, including distributional semantics and collocational analysis. From such quantitative viewpoints, we compare the usage of "wind" and "moon" in the poems of Li Bai and Du Fu. Colors in poems function like sounds in movies, and play a crucial role in the imageries of poems. Thus, words for colors are studied, and "white" is the main focus because it is the most frequent color in CTP. We also explore some cases of using colored words in antithesis pairs that were central for fostering the imageries of the poems. CTP also contains useful historical information, and we extract person names in CTP to study the social networks of the Tang poets. Such information can then be integrated with the China Biographical Database of Harvard University.
Mining Local Gazetteers of Literary Chinese with CRF and Pattern based Methods for Biographical Information in Chinese History
Nov 04, 2015
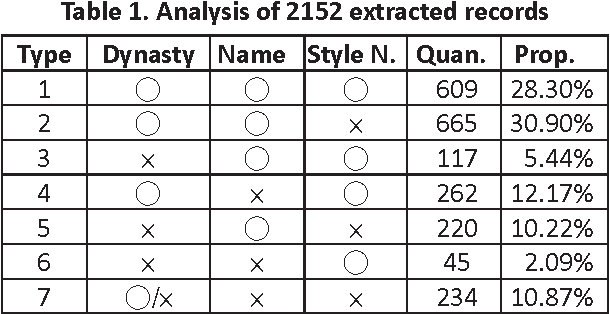

Person names and location names are essential building blocks for identifying events and social networks in historical documents that were written in literary Chinese. We take the lead to explore the research on algorithmically recognizing named entities in literary Chinese for historical studies with language-model based and conditional-random-field based methods, and extend our work to mining the document structures in historical documents. Practical evaluations were conducted with texts that were extracted from more than 220 volumes of local gazetteers (Difangzhi). Difangzhi is a huge and the single most important collection that contains information about officers who served in local government in Chinese history. Our methods performed very well on these realistic tests. Thousands of names and addresses were identified from the texts. A good portion of the extracted names match the biographical information currently recorded in the China Biographical Database (CBDB) of Harvard University, and many others can be verified by historians and will become as new additions to CBDB.
Textual Analysis for Studying Chinese Historical Documents and Literary Novels
Oct 11, 2015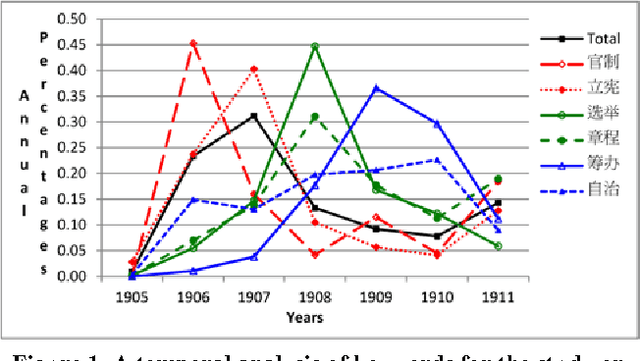
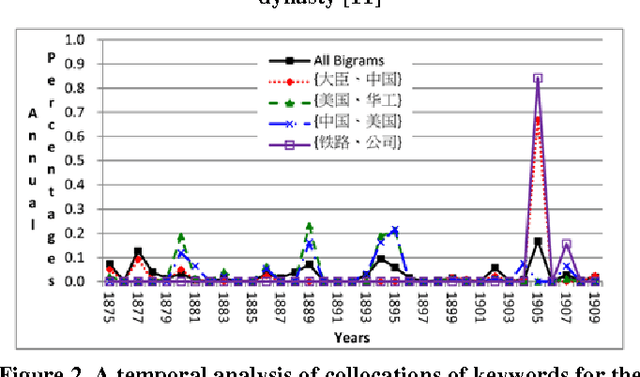
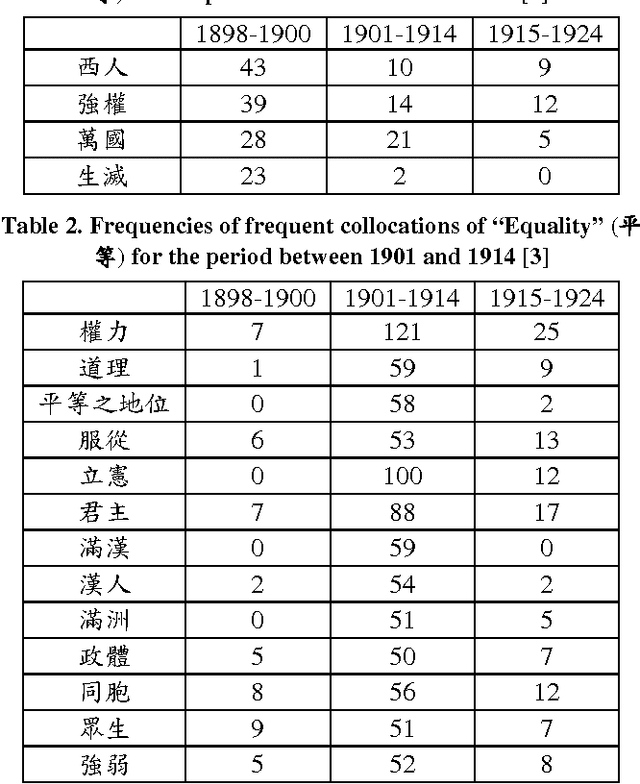
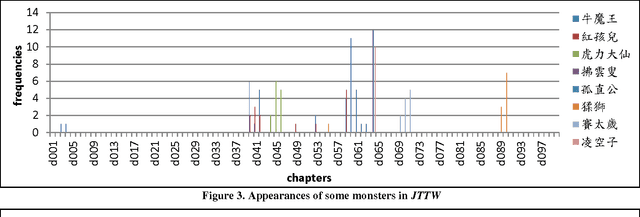
We analyzed historical and literary documents in Chinese to gain insights into research issues, and overview our studies which utilized four different sources of text materials in this paper. We investigated the history of concepts and transliterated words in China with the Database for the Study of Modern China Thought and Literature, which contains historical documents about China between 1830 and 1930. We also attempted to disambiguate names that were shared by multiple government officers who served between 618 and 1912 and were recorded in Chinese local gazetteers. To showcase the potentials and challenges of computer-assisted analysis of Chinese literatures, we explored some interesting yet non-trivial questions about two of the Four Great Classical Novels of China: (1) Which monsters attempted to consume the Buddhist monk Xuanzang in the Journey to the West (JTTW), which was published in the 16th century, (2) Which was the most powerful monster in JTTW, and (3) Which major role smiled the most in the Dream of the Red Chamber, which was published in the 18th century. Similar approaches can be applied to the analysis and study of modern documents, such as the newspaper articles published about the 228 incident that occurred in 1947 in Taiwan.
Mining and discovering biographical information in Difangzhi with a language-model-based approach
Apr 08, 2015
We present results of expanding the contents of the China Biographical Database by text mining historical local gazetteers, difangzhi. The goal of the database is to see how people are connected together, through kinship, social connections, and the places and offices in which they served. The gazetteers are the single most important collection of names and offices covering the Song through Qing periods. Although we begin with local officials we shall eventually include lists of local examination candidates, people from the locality who served in government, and notable local figures with biographies. The more data we collect the more connections emerge. The value of doing systematic text mining work is that we can identify relevant connections that are either directly informative or can become useful without deep historical research. Academia Sinica is developing a name database for officials in the central governments of the Ming and Qing dynasties.