 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hokkien Dual Translation by Exploring and Standardizing of Four Writing Systems
Mar 18, 2024Machine translation focuses mainly on high-resource languages (HRLs), while low-resource languages (LRLs) like Taiwanese Hokkien are relatively under-explored. This study aims to address this gap by developing a dual translation model between Taiwanese Hokkien and both Traditional Mandarin Chinese and English. We employ a pre-trained LLaMA2-7B model specialized in Traditional Mandarin Chinese to leverage the orthographic similarities between Taiwanese Hokkien Han and Traditional Mandarin Chinese. Our comprehensive experiments involve translation tasks across various writing systems of Taiwanese Hokkien and between Taiwanese Hokkien and other HRLs. We find that the use of a limited monolingual corpus also further improve the model's Taiwanese Hokkien capabilities. We then utilize our translation model to standardize all Taiwanese Hokkien writing systems into Hokkien Han, resulting in further performance improvements. Additionally, we introduce an evaluation method incorporating back-translation and GPT-4 to ensure reliable translation quality assessment even for LRLs. The study contributes to narrowing the resource gap for Taiwanese Hokkien and empirically investigates the advantages and limitations of pre-training and fine-tuning based on LLaMA 2.
SMUTF: Schema Matching Using Generative Tags and Hybrid Features
Feb 06, 2024



We introduce SMUTF, a unique approach for large-scale tabular data schema matching (SM), which assumes that supervised learning does not affect performance in open-domain tasks, thereby enabling effective cross-domain matching. This system uniquely combines rule-based feature engineering, pre-trained language models, and generative large language models. In an innovative adaptation inspired by the Humanitarian Exchange Language, we deploy 'generative tags' for each data column, enhancing the effectiveness of SM. SMUTF exhibits extensive versatility, working seamlessly with any pre-existing pre-trained embeddings, classification methods, and generative models. Recognizing the lack of extensive, publicly available datasets for SM, we have created and open-sourced the HDXSM dataset from the public humanitarian data. We believe this to be the most exhaustive SM dataset currently available. In evaluations across various public datasets and the novel HDXSM dataset, SMUTF demonstrated exceptional performance, surpassing existing state-of-the-art models in terms of accuracy and efficiency, and} improving the F1 score by 11.84% and the AUC of ROC by 5.08%.
Chat Vector: A Simple Approach to Equip LLMs With New Language Chat Capabilities
Oct 07, 2023
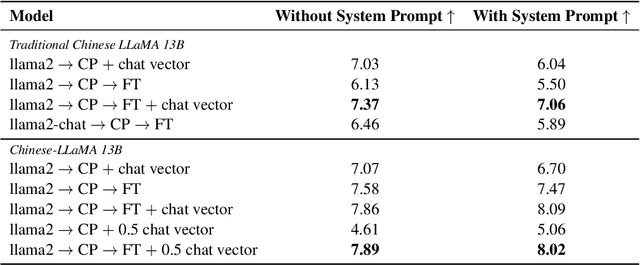

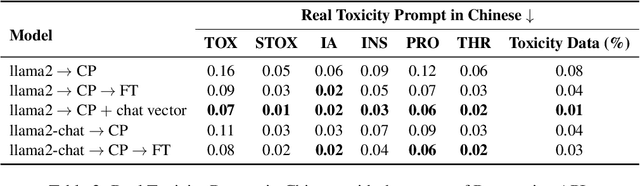
With the advancements in conversational AI, such as ChatGPT, this paper focuses on exploring developing Large Language Models (LLMs) for non-English languages, especially emphasizing alignment with human preferences. We introduce a computationally efficient method, leveraging chat vector, to synergize pre-existing knowledge and behaviors in LLMs, restructuring the conventional training paradigm from continual pre-train -> SFT -> RLHF to continual pre-train + chat vector. Our empirical studies, primarily focused on Traditional Chinese, employ LLaMA2 as the base model and acquire the chat vector by subtracting the pre-trained weights, LLaMA2, from the weights of LLaMA2-chat. Evaluating from three distinct facets, which are toxicity, ability of instruction following, and multi-turn dialogue demonstrates the chat vector's superior efficacy in chatting. To confirm the adaptability of our approach, we extend our experiments to include models pre-trained in both Korean and Simplified Chinese, illustrating the versatility of our methodology. Overall, we present a significant solution in aligning LLMs with human preferences efficiently across various languages, accomplished by the chat vector.
Large Language Models on the Chessboard: A Study on ChatGPT's Formal Language Comprehension and Complex Reasoning Skills
Aug 29, 2023
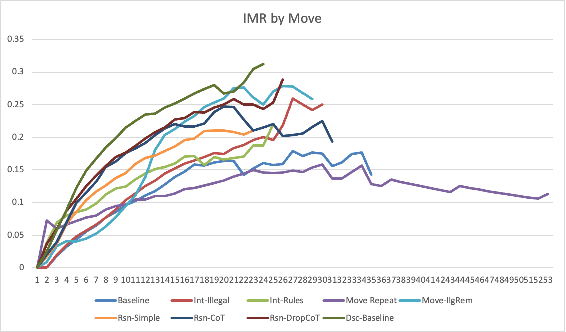

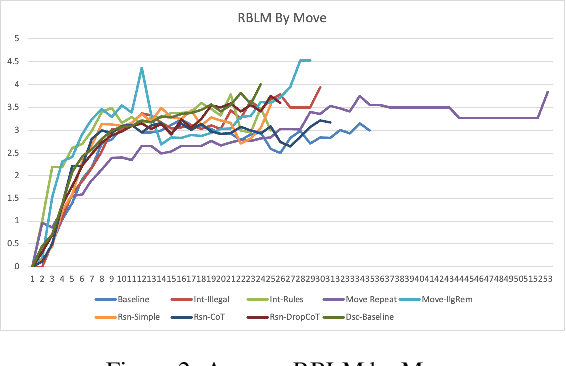
While large language models have made strides in natural language processing, their proficiency in complex reasoning tasks requiring formal language comprehension, such as chess, remains less investigated. This paper probes the performance of ChatGPT, a sophisticated language model by OpenAI in tackling such complex reasoning tasks, using chess as a case study. Through robust metrics examining both the legality and quality of moves, we assess ChatGPT's understanding of the chessboard, adherence to chess rules, and strategic decision-making abilities. Our evaluation identifies limitations within ChatGPT's attention mechanism that affect its formal language comprehension and uncovers the model's underdeveloped self-regulation abilities. Our study also reveals ChatGPT's propensity for a coherent strategy in its gameplay and a noticeable uptick in decision-making assertiveness when the model is presented with a greater volume of natural language or possesses a more lucid understanding of the state of the chessboard. These findings contribute to the growing exploration of language models' abilities beyond natural language processing, providing valuable information for future research towards models demonstrating human-like cognitive abilities.
Exploring Methods for Building Dialects-Mandarin Code-Mixing Corpora: A Case Study in Taiwanese Hokkien
Jan 21, 2023In natural language processing (NLP), code-mixing (CM) is a challenging task, especially when the mixed languages include dialects. In Southeast Asian countries such as Singapore, Indonesia, and Malaysia, Hokkien-Mandarin is the most widespread code-mixed language pair among Chinese immigrants, and it is also common in Taiwan. However, dialects such as Hokkien often have a scarcity of resources and the lack of an official writing system, limiting the development of dialect CM research. In this paper, we propose a method to construct a Hokkien-Mandarin CM dataset to mitigate the limitation, overcome the morphological issue under the Sino-Tibetan language family, and offer an efficient Hokkien word segmentation method through a linguistics-based toolkit. Furthermore, we use our proposed dataset and employ transfer learning to train the XLM (cross-lingual language model) for translation tasks. To fit the code-mixing scenario, we adapt XLM slightly. We found that by using linguistic knowledge, rules, and language tags, the model produces good results on CM data translation while maintaining monolingual translation quality.
EPG2S: Speech Generation and Speech Enhancement based on Electropalatography and Audio Signals using Multimodal Learning
Jun 16, 2022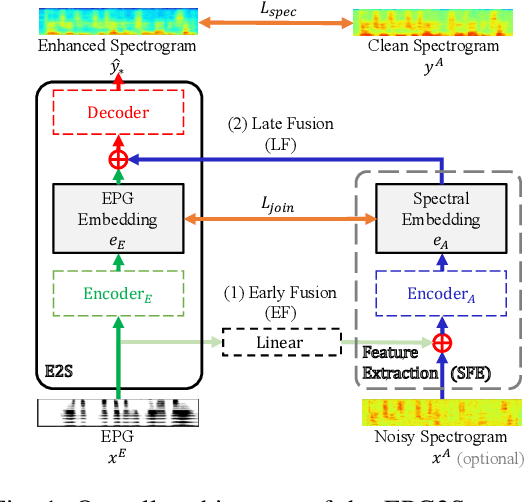
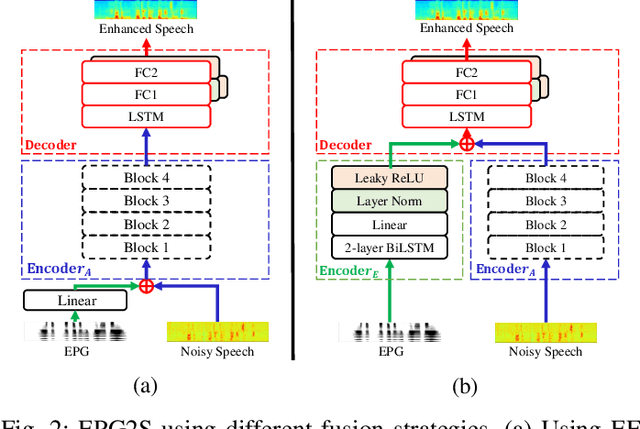
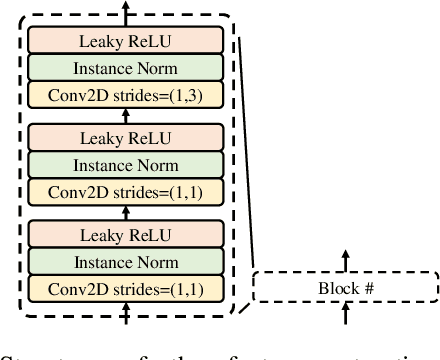
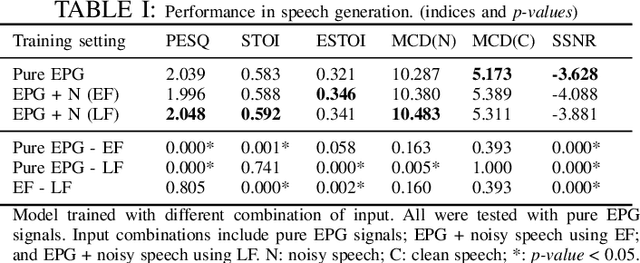
Speech generation and enhancement based on articulatory movements facilitate communication when the scope of verbal communication is absent, e.g., in patients who have lost the ability to speak. Although various techniques have been proposed to this end, electropalatography (EPG), which is a monitoring technique that records contact between the tongue and hard palate during speech, has not been adequately explored. Herein, we propose a novel multimodal EPG-to-speech (EPG2S) system that utilizes EPG and speech signals for speech generation and enhancement. Different fusion strategies based on multiple combinations of EPG and noisy speech signals are examined, and the viability of the proposed method is investigated. Experimental results indicate that EPG2S achieves desirable speech generation outcomes based solely on EPG signals. Further, the addition of noisy speech signals is observed to improve quality and intelligibility. Additionally, EPG2S is observed to achieve high-quality speech enhancement based solely on audio signals, with the addition of EPG signals further improving the performance. The late fusion strategy is deemed to be the most effective approach for simultaneous speech generation and enhancement.
Revised JNLPBA Corpus: A Revised Version of Biomedical NER Corpus for Relation Extraction Task
Jan 29, 2019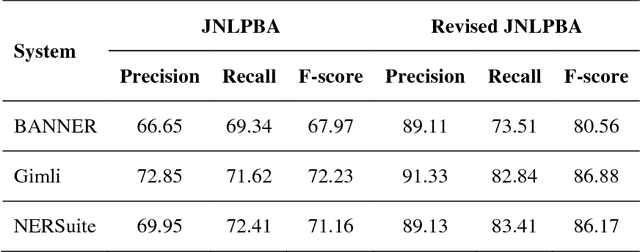
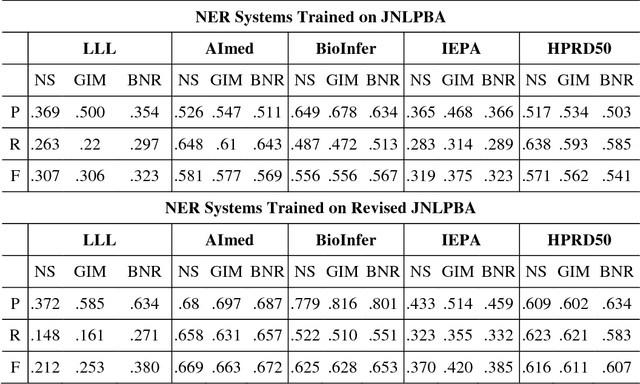
The advancement of biomedical named entity recognition (BNER) and biomedical relation extraction (BRE) researches promotes the development of text mining in biological domains. As a cornerstone of BRE, robust BNER system is required to identify the mentioned NEs in plain texts for further relation extraction stage. However, the current BNER corpora, which play important roles in these tasks, paid less attention to achieve the criteria for BRE task. In this study, we present Revised JNLPBA corpus, the revision of JNLPBA corpus, to broaden the applicability of a NER corpus from BNER to BRE task. We preserve the original entity types including protein, DNA, RNA, cell line and cell type while all the abstracts in JNLPBA corpus are manually curated by domain experts again basis on the new annotation guideline focusing on the specific NEs instead of general terms. Simultaneously, several imperfection issues in JNLPBA are pointed out and made up in the new corpus. To compare the adaptability of different NER systems in Revised JNLPBA and JNLPBA corpora, the F1-measure was measured in three open sources NER systems including BANNER, Gimli and NERSuite. In the same circumstance, all the systems perform average 10% better in Revised JNLPBA than in JNLPBA. Moreover, the cross-validation test is carried out which we train the NER systems on JNLPBA/Revised JNLPBA corpora and access the performance in both protein-protein interaction extraction (PPIE) and biomedical event extraction (BEE) corpora to confirm that the newly refined Revised JNLPBA is a competent NER corpus in biomedical relation application. The revised JNLPBA corpus is freely available at iasl-btm.iis.sinica.edu.tw/BNER/Content/Revised_JNLPBA.zip.
Textual Analysis for Studying Chinese Historical Documents and Literary Novels
Oct 11, 2015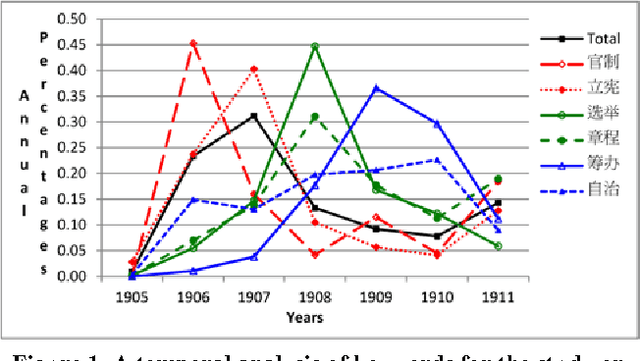
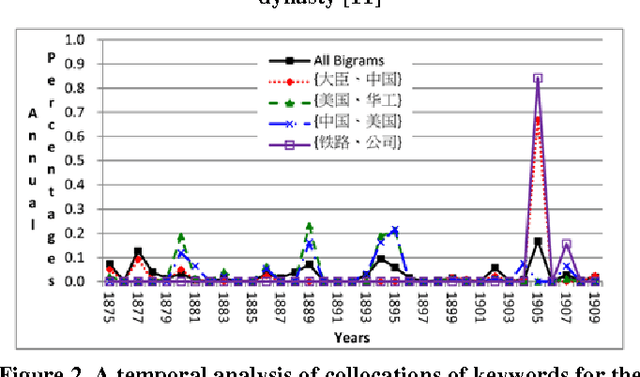
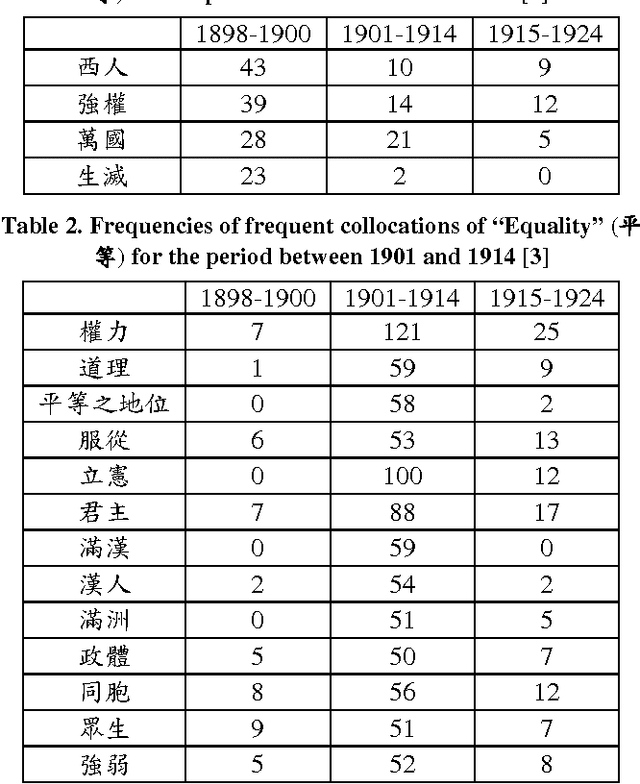
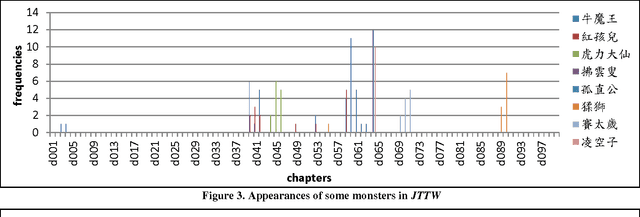
We analyzed historical and literary documents in Chinese to gain insights into research issues, and overview our studies which utilized four different sources of text materials in this paper. We investigated the history of concepts and transliterated words in China with the Database for the Study of Modern China Thought and Literature, which contains historical documents about China between 1830 and 1930. We also attempted to disambiguate names that were shared by multiple government officers who served between 618 and 1912 and were recorded in Chinese local gazetteers. To showcase the potentials and challenges of computer-assisted analysis of Chinese literatures, we explored some interesting yet non-trivial questions about two of the Four Great Classical Novels of China: (1) Which monsters attempted to consume the Buddhist monk Xuanzang in the Journey to the West (JTTW), which was published in the 16th century, (2) Which was the most powerful monster in JTTW, and (3) Which major role smiled the most in the Dream of the Red Chamber, which was published in the 18th century. Similar approaches can be applied to the analysis and study of modern documents, such as the newspaper articles published about the 228 incident that occurred in 1947 in Taiwan.