 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevised JNLPBA Corpus: A Revised Version of Biomedical NER Corpus for Relation Extraction Task
Jan 29, 2019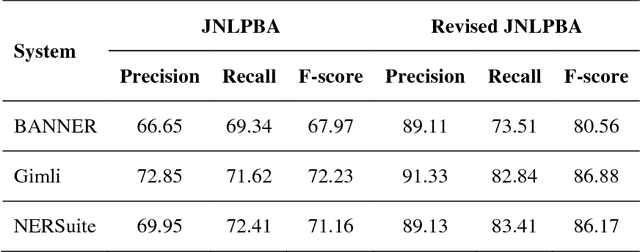
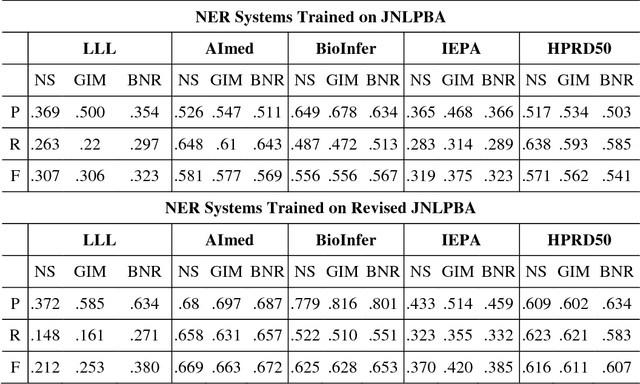
The advancement of biomedical named entity recognition (BNER) and biomedical relation extraction (BRE) researches promotes the development of text mining in biological domains. As a cornerstone of BRE, robust BNER system is required to identify the mentioned NEs in plain texts for further relation extraction stage. However, the current BNER corpora, which play important roles in these tasks, paid less attention to achieve the criteria for BRE task. In this study, we present Revised JNLPBA corpus, the revision of JNLPBA corpus, to broaden the applicability of a NER corpus from BNER to BRE task. We preserve the original entity types including protein, DNA, RNA, cell line and cell type while all the abstracts in JNLPBA corpus are manually curated by domain experts again basis on the new annotation guideline focusing on the specific NEs instead of general terms. Simultaneously, several imperfection issues in JNLPBA are pointed out and made up in the new corpus. To compare the adaptability of different NER systems in Revised JNLPBA and JNLPBA corpora, the F1-measure was measured in three open sources NER systems including BANNER, Gimli and NERSuite. In the same circumstance, all the systems perform average 10% better in Revised JNLPBA than in JNLPBA. Moreover, the cross-validation test is carried out which we train the NER systems on JNLPBA/Revised JNLPBA corpora and access the performance in both protein-protein interaction extraction (PPIE) and biomedical event extraction (BEE) corpora to confirm that the newly refined Revised JNLPBA is a competent NER corpus in biomedical relation application. The revised JNLPBA corpus is freely available at iasl-btm.iis.sinica.edu.tw/BNER/Content/Revised_JNLPBA.zip.