 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Adversarial Sentence Generation with Gradient-based Perturbation
Sep 06, 2019



This work proposes a novel algorithm to generate natural language adversarial input for text classification models, in order to investigate the robustness of these models. It involves applying gradient-based perturbation on the sentence embeddings that are used as the features for the classifier, and learning a decoder for generation. We employ this method to a sentiment analysis model and verify its effectiveness in inducing incorrect predictions by the model. We also conduct quantitative and qualitative analysis on these examples and demonstrate that our approach can generate more natural adversaries. In addition, it can be used to successfully perform black-box attacks, which involves attacking other existing models whose parameters are not known. On a public sentiment analysis API, the proposed method introduces a 20% relative decrease in average accuracy and 74% relative increase in absolute error.
Revised JNLPBA Corpus: A Revised Version of Biomedical NER Corpus for Relation Extraction Task
Jan 29, 2019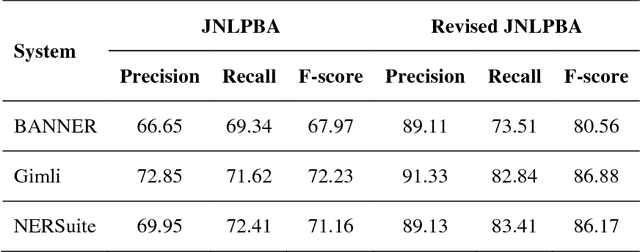
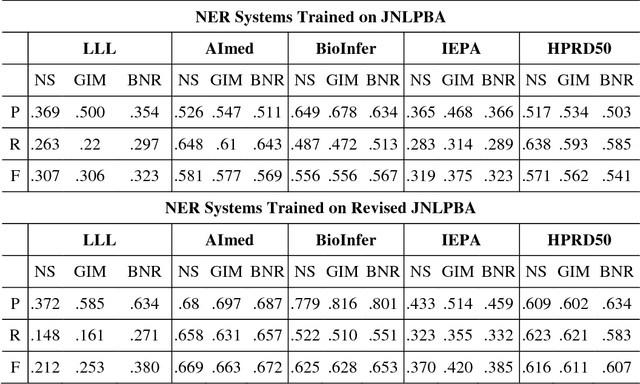
The advancement of biomedical named entity recognition (BNER) and biomedical relation extraction (BRE) researches promotes the development of text mining in biological domains. As a cornerstone of BRE, robust BNER system is required to identify the mentioned NEs in plain texts for further relation extraction stage. However, the current BNER corpora, which play important roles in these tasks, paid less attention to achieve the criteria for BRE task. In this study, we present Revised JNLPBA corpus, the revision of JNLPBA corpus, to broaden the applicability of a NER corpus from BNER to BRE task. We preserve the original entity types including protein, DNA, RNA, cell line and cell type while all the abstracts in JNLPBA corpus are manually curated by domain experts again basis on the new annotation guideline focusing on the specific NEs instead of general terms. Simultaneously, several imperfection issues in JNLPBA are pointed out and made up in the new corpus. To compare the adaptability of different NER systems in Revised JNLPBA and JNLPBA corpora, the F1-measure was measured in three open sources NER systems including BANNER, Gimli and NERSuite. In the same circumstance, all the systems perform average 10% better in Revised JNLPBA than in JNLPBA. Moreover, the cross-validation test is carried out which we train the NER systems on JNLPBA/Revised JNLPBA corpora and access the performance in both protein-protein interaction extraction (PPIE) and biomedical event extraction (BEE) corpora to confirm that the newly refined Revised JNLPBA is a competent NER corpus in biomedical relation application. The revised JNLPBA corpus is freely available at iasl-btm.iis.sinica.edu.tw/BNER/Content/Revised_JNLPBA.zip.