 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeling Case Similarity based on Co-Citation of Legal Articles in Judgment Documents with Empirical Dispute-Based Evaluation
Apr 29, 2025
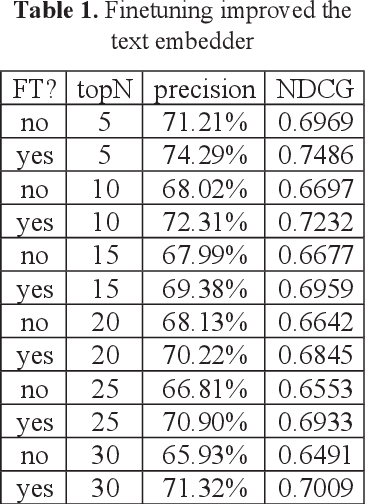


This report addresses the challenge of limited labeled datasets for developing legal recommender systems, particularly in specialized domains like labor disputes. We propose a new approach leveraging the co-citation of legal articles within cases to establish similarity and enable algorithmic annotation. This method draws a parallel to the concept of case co-citation, utilizing cited precedents as indicators of shared legal issues. To evaluate the labeled results, we employ a system that recommends similar cases based on plaintiffs' accusations, defendants' rebuttals, and points of disputes. The evaluation demonstrates that the recommender, with finetuned text embedding models and a reasonable BiLSTM module can recommend labor cases whose similarity was measured by the co-citation of the legal articles. This research contributes to the development of automated annotation techniques for legal documents, particularly in areas with limited access to comprehensive legal databases.
* 16 pages, 9 figures, 2 tables, the Nineteenth International Workshop on Juris-Informatics (JURISIN 2025), associated with the Seventeenth JSAI International Symposium on AI (JSAI-isAI 2025)
Similar Phrases for Cause of Actions of Civil Cases
Oct 11, 2024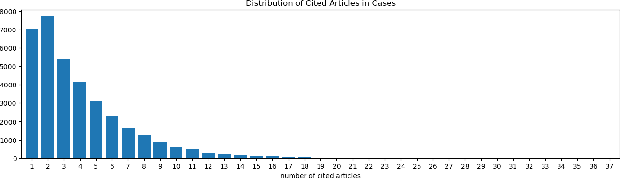
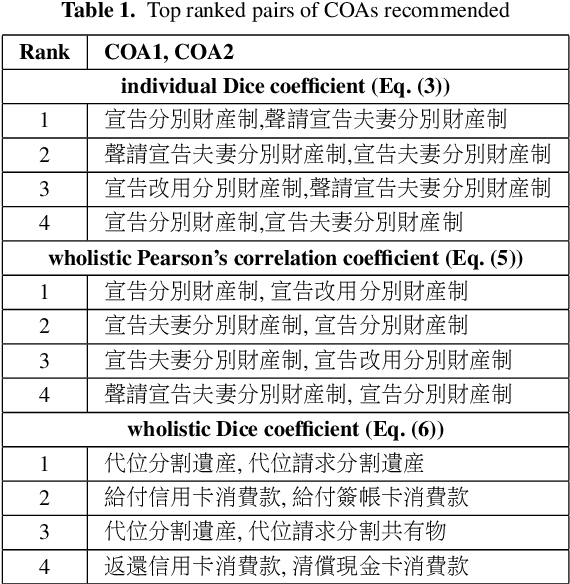


In the Taiwanese judicial system, Cause of Actions (COAs) are essential for identifying relevant legal judgments. However, the lack of standardized COA labeling creates challenges in filtering cases using basic methods. This research addresses this issue by leveraging embedding and clustering techniques to analyze the similarity between COAs based on cited legal articles. The study implements various similarity measures, including Dice coefficient and Pearson's correlation coefficient. An ensemble model combines rankings, and social network analysis identifies clusters of related COAs. This approach enhances legal analysis by revealing inconspicuous connections between COAs, offering potential applications in legal research beyond civil law.
An empirical evaluation of using ChatGPT to summarize disputes for recommending similar labor and employment cases in Chinese
Sep 14, 2024We present a hybrid mechanism for recommending similar cases of labor and employment litigations. The classifier determines the similarity based on the itemized disputes of the two cases, that the courts prepared. We cluster the disputes, compute the cosine similarity between the disputes, and use the results as the features for the classification tasks. Experimental results indicate that this hybrid approach outperformed our previous system, which considered only the information about the clusters of the disputes. We replaced the disputes that were prepared by the courts with the itemized disputes that were generated by GPT-3.5 and GPT-4, and repeated the same experiments. Using the disputes generated by GPT-4 led to better results. Although our classifier did not perform as well when using the disputes that the ChatGPT generated, the results were satisfactory. Hence, we hope that the future large-language models will become practically useful.
HRCenterNet: An Anchorless Approach to Chinese Character Segmentation in Historical Documents
Dec 10, 2020
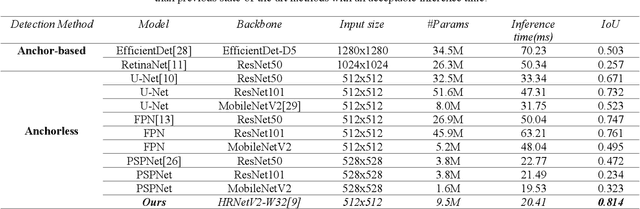

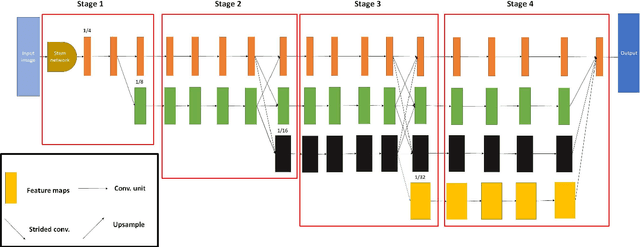
The information provided by historical documents has always been indispensable in the transmission of human civilization, but it has also made these books susceptible to damage due to various factors. Thanks to recent technology, the automatic digitization of these documents are one of the quickest and most effective means of preservation. The main steps of automatic text digitization can be divided into two stages, mainly: character segmentation and character recognition, where the recognition results depend largely on the accuracy of segmentation. Therefore, in this study, we will only focus on the character segmentation of historical Chinese documents. In this research, we propose a model named HRCenterNet, which is combined with an anchorless object detection method and parallelized architecture. The MTHv2 dataset consists of over 3000 Chinese historical document images and over 1 million individual Chinese characters; with these enormous data, the segmentation capability of our model achieves IoU 0.81 on average with the best speed-accuracy trade-off compared to the others. Our source code is available at https://github.com/Tverous/HRCenterNet.
When Classical Chinese Meets Machine Learning: Explaining the Relative Performances of Word and Sentence Segmentation Tasks
Jul 22, 2020
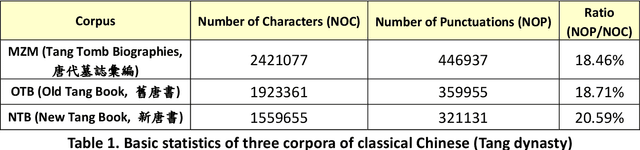

We consider three major text sources about the Tang Dynasty of China in our experiments that aim to segment text written in classical Chinese. These corpora include a collection of Tang Tomb Biographies, the New Tang Book, and the Old Tang Book. We show that it is possible to achieve satisfactory segmentation results with the deep learning approach. More interestingly, we found that some of the relative superiority that we observed among different designs of experiments may be explainable. The relative relevance among the training corpora provides hints/explanation for the observed differences in segmentation results that were achieved when we employed different combinations of corpora to train the classifiers.
Onto Word Segmentation of the Complete Tang Poems
Aug 28, 2019We aim at segmenting words in the Complete Tang Poems (CTP). Although it is possible to do some research about CTP without doing full-scale word segmentation, we must move forward to word-level analysis of CTP for conducting advanced research topics. In November 2018 when we submitted the manuscript for DH 2019 (ADHO), we collected only 2433 poems that were segmented by trained experts, and used the segmented poems to evaluate the segmenter that considered domain knowledge of Chinese poetry. We trained pointwise mutual information (PMI) between Chinese characters based on the CTP poems (excluding the 2433 poems, which were used exclusively only for testing) and the domain knowledge. The segmenter relied on the PMI information to the recover 85.7% of words in the test poems. We could segment a poem completely correct only 17.8% of the time, however. When we presented our work at DH 2019, we have annotated more than 20000 poems. With a much larger amount of data, we were able to apply biLSTM models for this word segmentation task, and we segmented a poem completely correct above 20% of the time. In contrast, human annotators completely agreed on their annotations about 40% of the time.
Classical Chinese Sentence Segmentation for Tomb Biographies of Tang Dynasty
Aug 28, 2019
Tomb biographies of the Tang dynasty provide invaluable information about Chinese history. The original biographies are classical Chinese texts which contain neither word boundaries nor sentence boundaries. Relying on three published books of tomb biographies of the Tang dynasty, we investigated the effectiveness of employing machine-learning methods for algorithmically identifying the pauses and terminals of sentences in the biographies. We consider the segmentation task as a classification problem. Chinese characters that are and are not followed by a punctuation mark are classified into two categories. We applied a machine-learning-based mechanism, the conditional random fields (CRF), to classify the characters (and words) in the texts, and we studied the contributions of selected types of lexical information to the resulting quality of the segmentation recommendations. This proposal presented at the DH 2018 conference discussed some of the basic experiments and their evaluations. By considering the contextual information and employing the heuristics provided by experts of Chinese literature, we achieved F1 measures that were better than 80%. More complex experiments that employ deep neural networks helped us further improve the results in recent work.
Tracking Words in Chinese Poetry of Tang and Song Dynasties with the China Biographical Database
Oct 29, 2017


Large-scale comparisons between the poetry of Tang and Song dynasties shed light on how words, collocations, and expressions were used and shared among the poets. That some words were used only in the Tang poetry and some only in the Song poetry could lead to interesting research in linguistics. That the most frequent colors are different in the Tang and Song poetry provides a trace of the changing social circumstances in the dynasties. Results of the current work link to research topics of lexicography, semantics, and social transitions. We discuss our findings and present our algorithms for efficient comparisons among the poems, which are crucial for completing billion times of comparisons within acceptable time.
Flexible Computing Services for Comparisons and Analyses of Classical Chinese Poetry
Sep 18, 2017
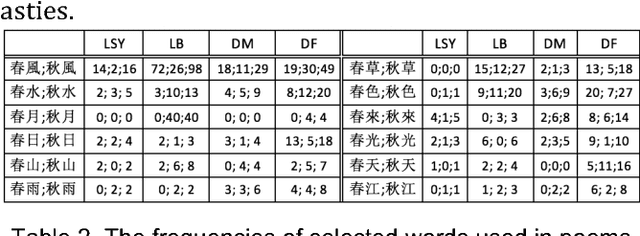

We collect nine corpora of representative Chinese poetry for the time span of 1046 BCE and 1644 CE for studying the history of Chinese words, collocations, and patterns. By flexibly integrating our own tools, we are able to provide new perspectives for approaching our goals. We illustrate the ideas with two examples. The first example show a new way to compare word preferences of poets, and the second example demonstrates how we can utilize our corpora in historical studies of the Chinese words. We show the viability of the tools for academic research, and we wish to make it helpful for enriching existing Chinese dictionary as well.
Character Distributions of Classical Chinese Literary Texts: Zipf's Law, Genres, and Epochs
Sep 17, 2017
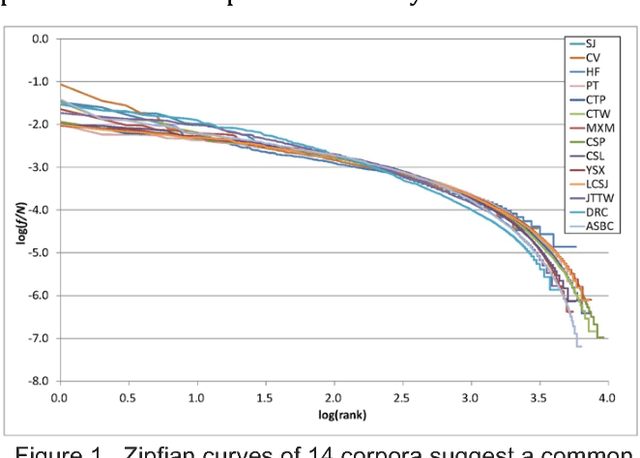
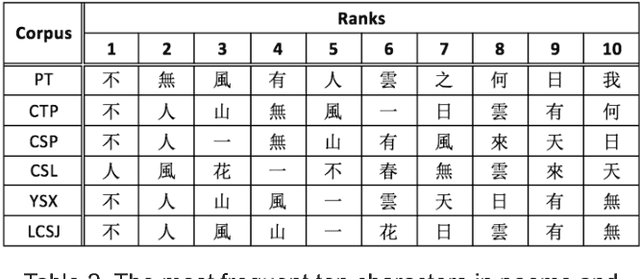
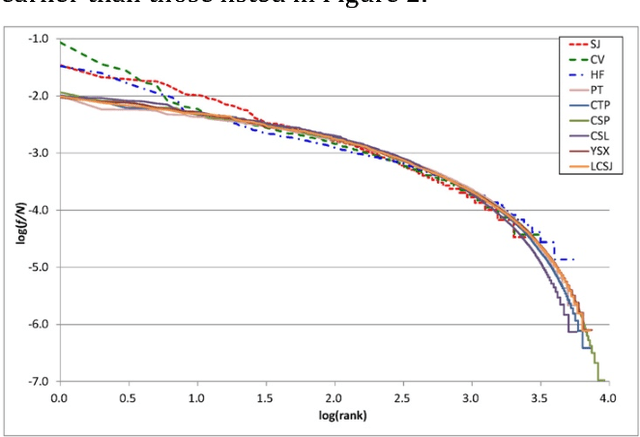
We collect 14 representative corpora for major periods in Chinese history in this study. These corpora include poetic works produced in several dynasties, novels of the Ming and Qing dynasties, and essays and news reports written in modern Chinese. The time span of these corpora ranges between 1046 BCE and 2007 CE. We analyze their character and word distributions from the viewpoint of the Zipf's law, and look for factors that affect the deviations and similarities between their Zipfian curves. Genres and epochs demonstrated their influences in our analyses. Specifically, the character distributions for poetic works of between 618 CE and 1644 CE exhibit striking similarity. In addition, although texts of the same dynasty may tend to use the same set of characters, their character distributions still deviate from each other.