 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Amplification for Federated Learning via User Sampling and Wireless Aggregation
Mar 02, 2021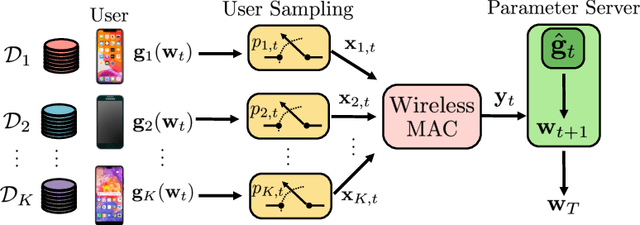
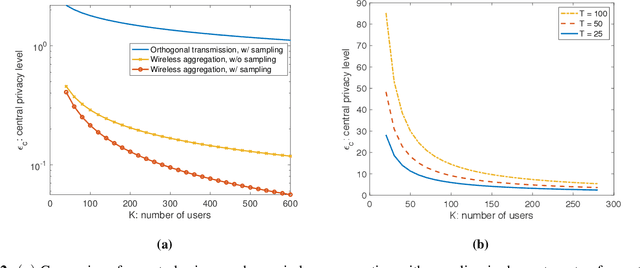

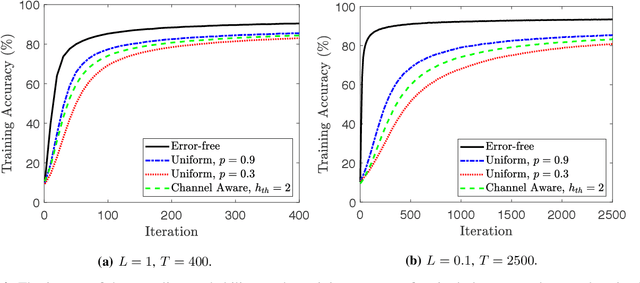
In this paper, we study the problem of federated learning over a wireless channel with user sampling, modeled by a Gaussian multiple access channel, subject to central and local differential privacy (DP/LDP) constraints. It has been shown that the superposition nature of the wireless channel provides a dual benefit of bandwidth efficient gradient aggregation, in conjunction with strong DP guarantees for the users. Specifically, the central DP privacy leakage has been shown to scale as $\mathcal{O}(1/K^{1/2})$, where $K$ is the number of users. It has also been shown that user sampling coupled with orthogonal transmission can enhance the central DP privacy leakage with the same scaling behavior. In this work, we show that, by join incorporating both wireless aggregation and user sampling, one can obtain even stronger privacy guarantees. We propose a private wireless gradient aggregation scheme, which relies on independently randomized participation decisions by each user. The central DP leakage of our proposed scheme scales as $\mathcal{O}(1/K^{3/4})$. In addition, we show that LDP is also boosted by user sampling. We also present analysis for the convergence rate of the proposed scheme and study the tradeoffs between wireless resources, convergence, and privacy theoretically and empirically for two scenarios when the number of sampled participants are $(a)$ known, or $(b)$ unknown at the parameter server.
When Classical Chinese Meets Machine Learning: Explaining the Relative Performances of Word and Sentence Segmentation Tasks
Jul 22, 2020
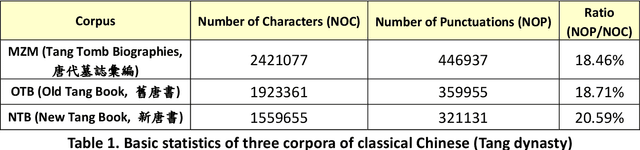

We consider three major text sources about the Tang Dynasty of China in our experiments that aim to segment text written in classical Chinese. These corpora include a collection of Tang Tomb Biographies, the New Tang Book, and the Old Tang Book. We show that it is possible to achieve satisfactory segmentation results with the deep learning approach. More interestingly, we found that some of the relative superiority that we observed among different designs of experiments may be explainable. The relative relevance among the training corpora provides hints/explanation for the observed differences in segmentation results that were achieved when we employed different combinations of corpora to train the classifiers.
Communication Efficient Federated Learning over Multiple Access Channels
Jan 23, 2020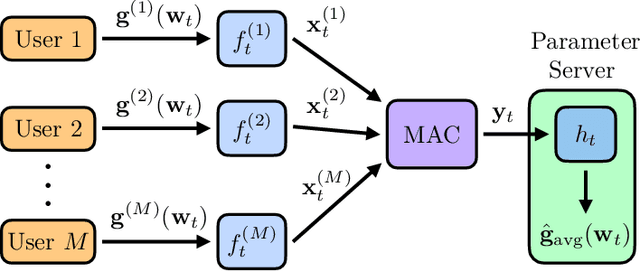
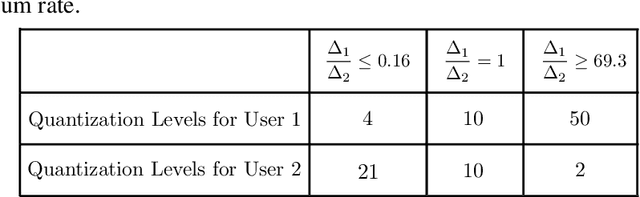

In this work, we study the problem of federated learning (FL), where distributed users aim to jointly train a machine learning model with the help of a parameter server (PS). In each iteration of FL, users compute local gradients, followed by transmission of the quantized gradients for subsequent aggregation and model updates at PS. One of the challenges of FL is that of communication overhead due to FL's iterative nature and large model sizes. One recent direction to alleviate communication bottleneck in FL is to let users communicate simultaneously over a multiple access channel (MAC), possibly making better use of the communication resources. In this paper, we consider the problem of FL learning over a MAC. In particular, we focus on the design of digital gradient transmission schemes over a MAC, where gradients at each user are first quantized, and then transmitted over a MAC to be decoded individually at the PS. When designing digital FL schemes over MACs, there are new opportunities to assign different amount of resources (such as rate or bandwidth) to different users based on a) the informativeness of the gradients at each user, and b) the underlying channel conditions. We propose a stochastic gradient quantization scheme, where the quantization parameters are optimized based on the capacity region of the MAC. We show that such channel aware quantization for FL outperforms uniform quantization, particularly when users experience different channel conditions, and when have gradients with varying levels of informativeness.
Random Sampling for Distributed Coded Matrix Multiplication
May 16, 2019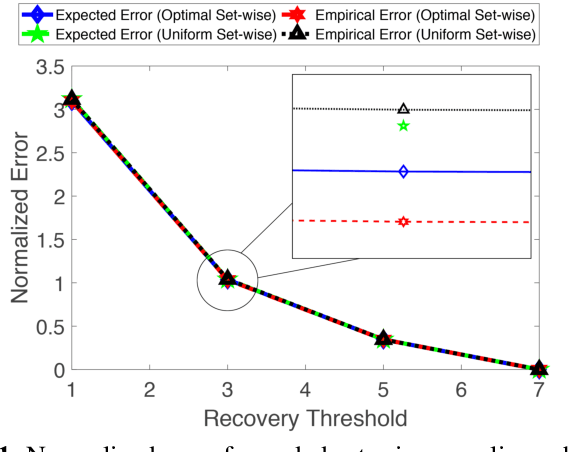

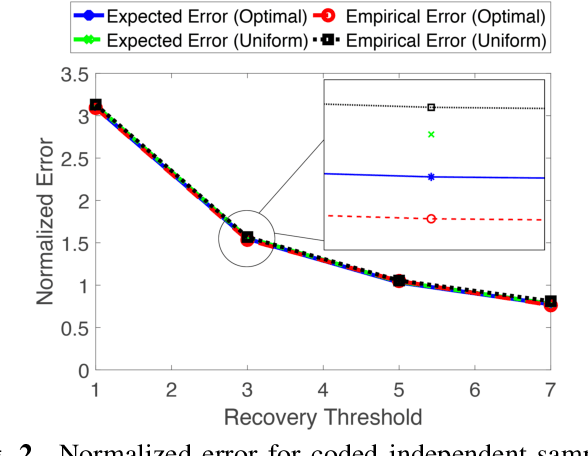
Matrix multiplication is a fundamental building block for large scale computations arising in various applications, including machine learning. There has been significant recent interest in using coding to speed up distributed matrix multiplication, that are robust to stragglers (i.e., machines that may perform slower computations). In many scenarios, instead of exact computation, approximate matrix multiplication, i.e., allowing for a tolerable error is also sufficient. Such approximate schemes make use of randomization techniques to speed up the computation process. In this paper, we initiate the study of approximate coded matrix multiplication, and investigate the joint synergies offered by randomization and coding. Specifically, we propose two coded randomized sampling schemes that use (a) codes to achieve a desired recovery threshold and (b) random sampling to obtain approximation of the matrix multiplication. Tradeoffs between the recovery threshold and approximation error obtained through random sampling are investigated for a class of coded matrix multiplication schemes.