Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Classical Chinese Meets Machine Learning: Explaining the Relative Performances of Word and Sentence Segmentation Tasks
Jul 22, 2020
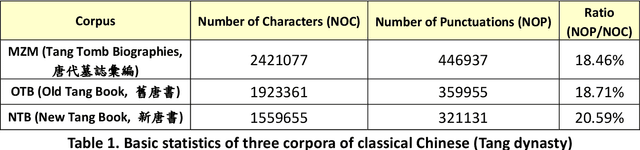

We consider three major text sources about the Tang Dynasty of China in our experiments that aim to segment text written in classical Chinese. These corpora include a collection of Tang Tomb Biographies, the New Tang Book, and the Old Tang Book. We show that it is possible to achieve satisfactory segmentation results with the deep learning approach. More interestingly, we found that some of the relative superiority that we observed among different designs of experiments may be explainable. The relative relevance among the training corpora provides hints/explanation for the observed differences in segmentation results that were achieved when we employed different combinations of corpora to train the classifiers.
* 4 pages, 1 figure, 2 tables, 2020 International Conference on Digital
Humanities (Alliance of Digital Humanities Organizations, ADHO)
Via