 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRCenterNet: An Anchorless Approach to Chinese Character Segmentation in Historical Documents
Dec 10, 2020
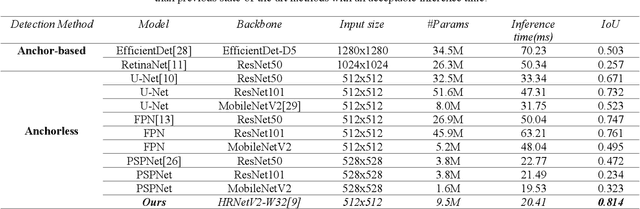

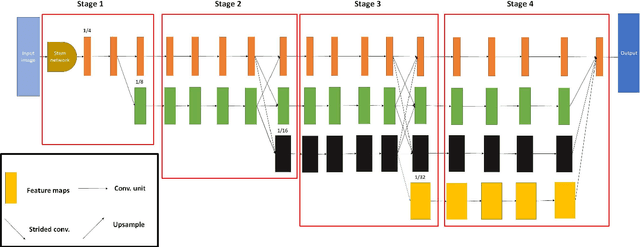
The information provided by historical documents has always been indispensable in the transmission of human civilization, but it has also made these books susceptible to damage due to various factors. Thanks to recent technology, the automatic digitization of these documents are one of the quickest and most effective means of preservation. The main steps of automatic text digitization can be divided into two stages, mainly: character segmentation and character recognition, where the recognition results depend largely on the accuracy of segmentation. Therefore, in this study, we will only focus on the character segmentation of historical Chinese documents. In this research, we propose a model named HRCenterNet, which is combined with an anchorless object detection method and parallelized architecture. The MTHv2 dataset consists of over 3000 Chinese historical document images and over 1 million individual Chinese characters; with these enormous data, the segmentation capability of our model achieves IoU 0.81 on average with the best speed-accuracy trade-off compared to the others. Our source code is available at https://github.com/Tverous/HRCenterNet.