 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeENTER: Event Based Interpretable Reasoning for VideoQA
Jan 24, 2025



In this paper, we present ENTER, an interpretable Video Question Answering (VideoQA) system based on event graphs. Event graphs convert videos into graphical representations, where video events form the nodes and event-event relationships (temporal/causal/hierarchical) form the edges. This structured representation offers many benefits: 1) Interpretable VideoQA via generated code that parses event-graph; 2) Incorporation of contextual visual information in the reasoning process (code generation) via event graphs; 3) Robust VideoQA via Hierarchical Iterative Update of the event graphs. Existing interpretable VideoQA systems are often top-down, disregarding low-level visual information in the reasoning plan generation, and are brittle. While bottom-up approaches produce responses from visual data, they lack interpretability. Experimental results on NExT-QA, IntentQA, and EgoSchema demonstrate that not only does our method outperform existing top-down approaches while obtaining competitive performance against bottom-up approaches, but more importantly, offers superior interpretability and explainability in the reasoning process.
MetaSumPerceiver: Multimodal Multi-Document Evidence Summarization for Fact-Checking
Jul 18, 2024Fact-checking real-world claims often requires reviewing multiple multimodal documents to assess a claim's truthfulness, which is a highly laborious and time-consuming task. In this paper, we present a summarization model designed to generate claim-specific summaries useful for fact-checking from multimodal, multi-document datasets. The model takes inputs in the form of documents, images, and a claim, with the objective of assisting in fact-checking tasks. We introduce a dynamic perceiver-based model that can handle inputs from multiple modalities of arbitrary lengths. To train our model, we leverage a novel reinforcement learning-based entailment objective to generate summaries that provide evidence distinguishing between different truthfulness labels. To assess the efficacy of our approach, we conduct experiments on both an existing benchmark and a new dataset of multi-document claims that we contribute. Our approach outperforms the SOTA approach by 4.6% in the claim verification task on the MOCHEG dataset and demonstrates strong performance on our new Multi-News-Fact-Checking dataset.
HRCenterNet: An Anchorless Approach to Chinese Character Segmentation in Historical Documents
Dec 10, 2020
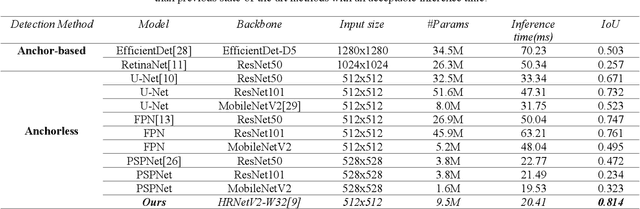

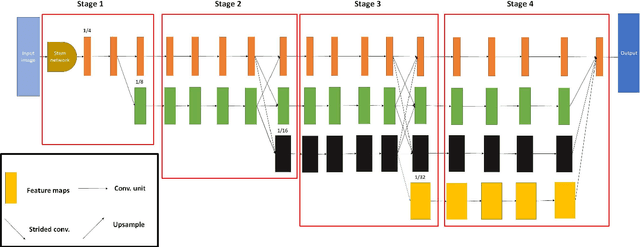
The information provided by historical documents has always been indispensable in the transmission of human civilization, but it has also made these books susceptible to damage due to various factors. Thanks to recent technology, the automatic digitization of these documents are one of the quickest and most effective means of preservation. The main steps of automatic text digitization can be divided into two stages, mainly: character segmentation and character recognition, where the recognition results depend largely on the accuracy of segmentation. Therefore, in this study, we will only focus on the character segmentation of historical Chinese documents. In this research, we propose a model named HRCenterNet, which is combined with an anchorless object detection method and parallelized architecture. The MTHv2 dataset consists of over 3000 Chinese historical document images and over 1 million individual Chinese characters; with these enormous data, the segmentation capability of our model achieves IoU 0.81 on average with the best speed-accuracy trade-off compared to the others. Our source code is available at https://github.com/Tverous/HRCenterNet.