 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzleGPT: Emulating Human Puzzle-Solving Ability for Time and Location Prediction
Jan 24, 2025



The task of predicting time and location from images is challenging and requires complex human-like puzzle-solving ability over different clues. In this work, we formalize this ability into core skills and implement them using different modules in an expert pipeline called PuzzleGPT. PuzzleGPT consists of a perceiver to identify visual clues, a reasoner to deduce prediction candidates, a combiner to combinatorially combine information from different clues, a web retriever to get external knowledge if the task can't be solved locally, and a noise filter for robustness. This results in a zero-shot, interpretable, and robust approach that records state-of-the-art performance on two datasets -- TARA and WikiTilo. PuzzleGPT outperforms large VLMs such as BLIP-2, InstructBLIP, LLaVA, and even GPT-4V, as well as automatically generated reasoning pipelines like VisProg, by at least 32% and 38%, respectively. It even rivals or surpasses finetuned models.
ENTER: Event Based Interpretable Reasoning for VideoQA
Jan 24, 2025



In this paper, we present ENTER, an interpretable Video Question Answering (VideoQA) system based on event graphs. Event graphs convert videos into graphical representations, where video events form the nodes and event-event relationships (temporal/causal/hierarchical) form the edges. This structured representation offers many benefits: 1) Interpretable VideoQA via generated code that parses event-graph; 2) Incorporation of contextual visual information in the reasoning process (code generation) via event graphs; 3) Robust VideoQA via Hierarchical Iterative Update of the event graphs. Existing interpretable VideoQA systems are often top-down, disregarding low-level visual information in the reasoning plan generation, and are brittle. While bottom-up approaches produce responses from visual data, they lack interpretability. Experimental results on NExT-QA, IntentQA, and EgoSchema demonstrate that not only does our method outperform existing top-down approaches while obtaining competitive performance against bottom-up approaches, but more importantly, offers superior interpretability and explainability in the reasoning process.
Detecting Multimodal Situations with Insufficient Context and Abstaining from Baseless Predictions
May 23, 2024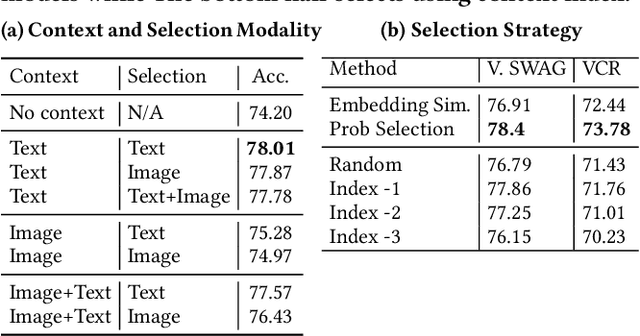
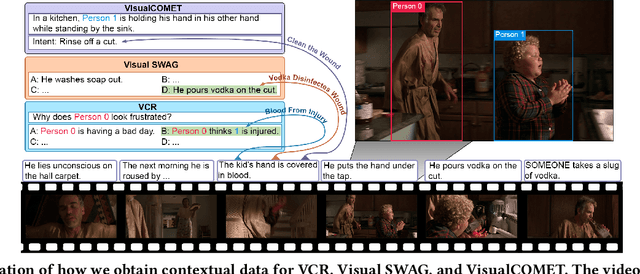
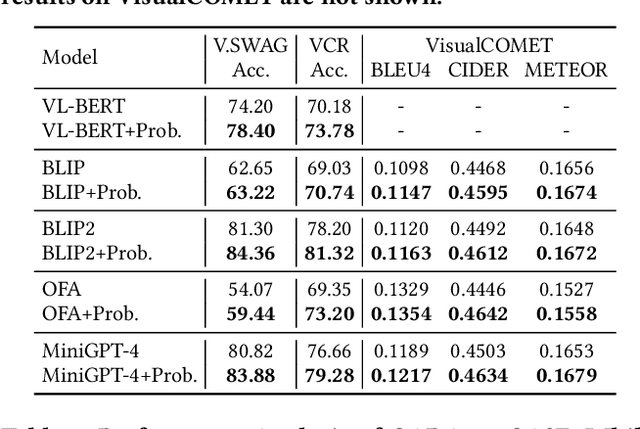
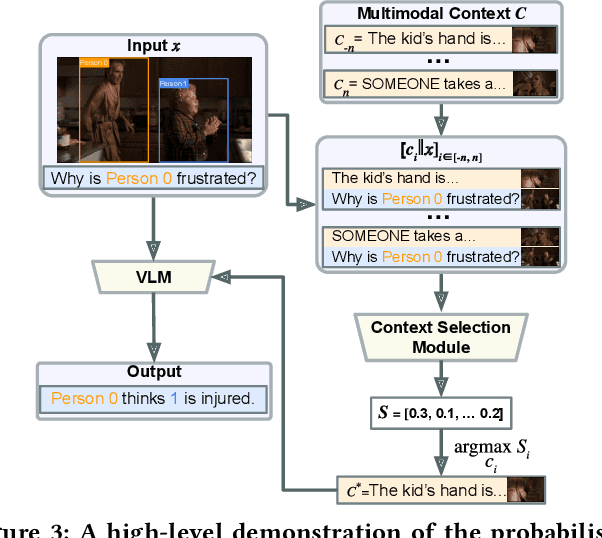
Despite the widespread adoption of Vision-Language Understanding (VLU) benchmarks such as VQA v2, OKVQA, A-OKVQA, GQA, VCR, SWAG, and VisualCOMET, our analysis reveals a pervasive issue affecting their integrity: these benchmarks contain samples where answers rely on assumptions unsupported by the provided context. Training models on such data foster biased learning and hallucinations as models tend to make similar unwarranted assumptions. To address this issue, we collect contextual data for each sample whenever available and train a context selection module to facilitate evidence-based model predictions. Strong improvements across multiple benchmarks demonstrate the effectiveness of our approach. Further, we develop a general-purpose Context-AwaRe Abstention (CARA) detector to identify samples lacking sufficient context and enhance model accuracy by abstaining from responding if the required context is absent. CARA exhibits generalization to new benchmarks it wasn't trained on, underscoring its utility for future VLU benchmarks in detecting or cleaning samples with inadequate context. Finally, we curate a Context Ambiguity and Sufficiency Evaluation (CASE) set to benchmark the performance of insufficient context detectors. Overall, our work represents a significant advancement in ensuring that vision-language models generate trustworthy and evidence-based outputs in complex real-world scenarios.
RAP: Retrieval-Augmented Planner for Adaptive Procedure Planning in Instructional Videos
Mar 27, 2024



Procedure Planning in instructional videos entails generating a sequence of action steps based on visual observations of the initial and target states. Despite the rapid progress in this task, there remain several critical challenges to be solved: (1) Adaptive procedures: Prior works hold an unrealistic assumption that the number of action steps is known and fixed, leading to non-generalizable models in real-world scenarios where the sequence length varies. (2) Temporal relation: Understanding the step temporal relation knowledge is essential in producing reasonable and executable plans. (3) Annotation cost: Annotating instructional videos with step-level labels (i.e., timestamp) or sequence-level labels (i.e., action category) is demanding and labor-intensive, limiting its generalizability to large-scale datasets.In this work, we propose a new and practical setting, called adaptive procedure planning in instructional videos, where the procedure length is not fixed or pre-determined. To address these challenges we introduce Retrieval-Augmented Planner (RAP) model. Specifically, for adaptive procedures, RAP adaptively determines the conclusion of actions using an auto-regressive model architecture. For temporal relation, RAP establishes an external memory module to explicitly retrieve the most relevant state-action pairs from the training videos and revises the generated procedures. To tackle high annotation cost, RAP utilizes a weakly-supervised learning manner to expand the training dataset to other task-relevant, unannotated videos by generating pseudo labels for action steps. Experiments on CrossTask and COIN benchmarks show the superiority of RAP over traditional fixed-length models, establishing it as a strong baseline solution for adaptive procedure planning.