 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAP: Retrieval-Augmented Planner for Adaptive Procedure Planning in Instructional Videos
Mar 27, 2024



Procedure Planning in instructional videos entails generating a sequence of action steps based on visual observations of the initial and target states. Despite the rapid progress in this task, there remain several critical challenges to be solved: (1) Adaptive procedures: Prior works hold an unrealistic assumption that the number of action steps is known and fixed, leading to non-generalizable models in real-world scenarios where the sequence length varies. (2) Temporal relation: Understanding the step temporal relation knowledge is essential in producing reasonable and executable plans. (3) Annotation cost: Annotating instructional videos with step-level labels (i.e., timestamp) or sequence-level labels (i.e., action category) is demanding and labor-intensive, limiting its generalizability to large-scale datasets.In this work, we propose a new and practical setting, called adaptive procedure planning in instructional videos, where the procedure length is not fixed or pre-determined. To address these challenges we introduce Retrieval-Augmented Planner (RAP) model. Specifically, for adaptive procedures, RAP adaptively determines the conclusion of actions using an auto-regressive model architecture. For temporal relation, RAP establishes an external memory module to explicitly retrieve the most relevant state-action pairs from the training videos and revises the generated procedures. To tackle high annotation cost, RAP utilizes a weakly-supervised learning manner to expand the training dataset to other task-relevant, unannotated videos by generating pseudo labels for action steps. Experiments on CrossTask and COIN benchmarks show the superiority of RAP over traditional fixed-length models, establishing it as a strong baseline solution for adaptive procedure planning.
Multimodal Adaptive Distillation for Leveraging Unimodal Encoders for Vision-Language Tasks
Apr 28, 2022


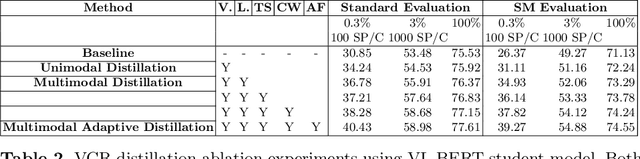
Cross-modal encoders for vision-language (VL) tasks are often pretrained with carefully curated vision-language datasets. While these datasets reach an order of 10 million samples, the labor cost is prohibitive to scale further. Conversely, unimodal encoders are pretrained with simpler annotations that are less cost-prohibitive, achieving scales of hundreds of millions to billions. As a result, unimodal encoders have achieved state-of-art (SOTA) on many downstream tasks. However, challenges remain when applying to VL tasks. The pretraining data is not optimal for cross-modal architectures and requires heavy computational resources. In addition, unimodal architectures lack cross-modal interactions that have demonstrated significant benefits for VL tasks. Therefore, how to best leverage pretrained unimodal encoders for VL tasks is still an area of active research. In this work, we propose a method to leverage unimodal vision and text encoders for VL tasks that augment existing VL approaches while conserving computational complexity. Specifically, we propose Multimodal Adaptive Distillation (MAD), which adaptively distills useful knowledge from pretrained encoders to cross-modal VL encoders. Second, to better capture nuanced impacts on VL task performance, we introduce an evaluation protocol that includes Visual Commonsense Reasoning (VCR), Visual Entailment (SNLI-VE), and Visual Question Answering (VQA), across a variety of data constraints and conditions of domain shift. Experiments demonstrate that MAD leads to consistent gains in the low-shot, domain-shifted, and fully-supervised conditions on VCR, SNLI-VE, and VQA, achieving SOTA performance on VCR compared to other single models pretrained with image-text data. Finally, MAD outperforms concurrent works utilizing pretrained vision encoder from CLIP. Code will be made available.