 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Deconvolution of Nonstationary Graph Signals over Shift-Invariant Channels
Aug 24, 2025In this paper, we investigate blind deconvolution of nonstationary graph signals from noisy observations, transmitted through an unknown shift-invariant channel. The deconvolution process assumes that the observer has access to the covariance structure of the original graph signals. To evaluate the effectiveness of our channel estimation and blind deconvolution method, we conduct numerical experiments using a temperature dataset in the Brest region of France.
RAP: Retrieval-Augmented Planner for Adaptive Procedure Planning in Instructional Videos
Mar 27, 2024



Procedure Planning in instructional videos entails generating a sequence of action steps based on visual observations of the initial and target states. Despite the rapid progress in this task, there remain several critical challenges to be solved: (1) Adaptive procedures: Prior works hold an unrealistic assumption that the number of action steps is known and fixed, leading to non-generalizable models in real-world scenarios where the sequence length varies. (2) Temporal relation: Understanding the step temporal relation knowledge is essential in producing reasonable and executable plans. (3) Annotation cost: Annotating instructional videos with step-level labels (i.e., timestamp) or sequence-level labels (i.e., action category) is demanding and labor-intensive, limiting its generalizability to large-scale datasets.In this work, we propose a new and practical setting, called adaptive procedure planning in instructional videos, where the procedure length is not fixed or pre-determined. To address these challenges we introduce Retrieval-Augmented Planner (RAP) model. Specifically, for adaptive procedures, RAP adaptively determines the conclusion of actions using an auto-regressive model architecture. For temporal relation, RAP establishes an external memory module to explicitly retrieve the most relevant state-action pairs from the training videos and revises the generated procedures. To tackle high annotation cost, RAP utilizes a weakly-supervised learning manner to expand the training dataset to other task-relevant, unannotated videos by generating pseudo labels for action steps. Experiments on CrossTask and COIN benchmarks show the superiority of RAP over traditional fixed-length models, establishing it as a strong baseline solution for adaptive procedure planning.
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
Jul 23, 2021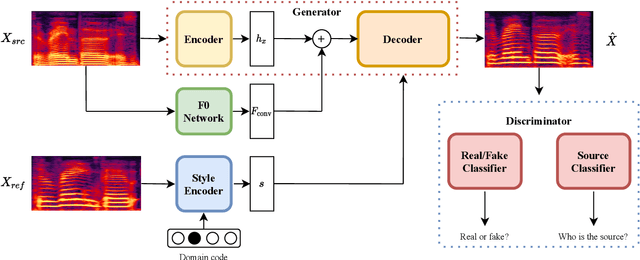

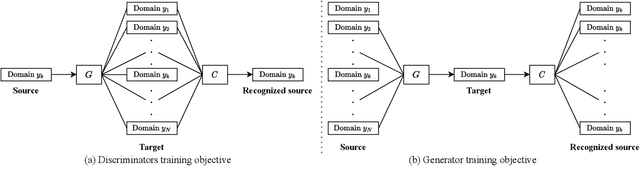
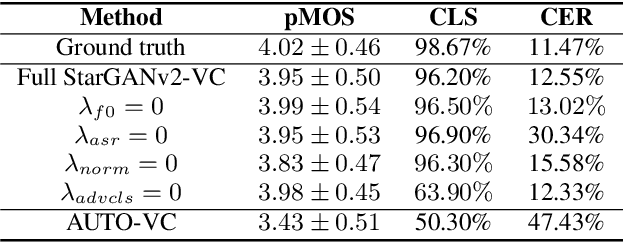
We present an unsupervised non-parallel many-to-many voice conversion (VC) method using a generative adversarial network (GAN) called StarGAN v2. Using a combination of adversarial source classifier loss and perceptual loss, our model significantly outperforms previous VC models. Although our model is trained only with 20 English speakers, it generalizes to a variety of voice conversion tasks, such as any-to-many, cross-lingual, and singing conversion. Using a style encoder, our framework can also convert plain reading speech into stylistic speech, such as emotional and falsetto speech. Subjective and objective evaluation experiments on a non-parallel many-to-many voice conversion task revealed that our model produces natural sounding voices, close to the sound quality of state-of-the-art text-to-speech (TTS) based voice conversion methods without the need for text labels. Moreover, our model is completely convolutional and with a faster-than-real-time vocoder such as Parallel WaveGAN can perform real-time voice conversion.