 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShift-invariant spaces on finite undirected graphs
Feb 22, 2026Shift-invariant spaces (SISs) on the real line provide a natural framework for representing, analyzing and processing signals with inherent shift-invariant structure. In this paper, we extend this framework to the finite undirected graph setting by introducing the concept of graph shift-invariant spaces (GSISs). We examine several properties of GSISs, including their characterization via range functions and fiber functions in the Fourier domain, their connections to shift-invariant filters and polynomial filters, the frame and Riesz basis structures of finitely generated GSISs, and their intricate relationships with bandlimited spaces, finitely generated GSISs, and graph reproducing kernel Hilbert spaces with shift-invariant reproducing kernels (SIGRKHSs). Our analysis reveals several distinctions between SISs on the line and GSISs, such as the shift-invariance of the frame operator, the existence of shift-invariant dual frames, the emergence of fractional shift-invariance, and the interrelationships among GSISs, finitely generated GSISs, SIGRKHSs and bandlimited spaces. In this paper, we also introduce a spectral decomposition of the identity associated with graph shifts and propose a novel definition of the graph Fourier transform (GFT) of spectral type, together with explicit formulations for the GFTs on complete graphs and circulant graphs. In addition, we establish a clear connection between polynomial filters and shift-invariant filters, and we derive a graph uncertainty principle governing the essential supports of a nonzero graph signal and its GFT.
inversedMixup: Data Augmentation via Inverting Mixed Embeddings
Jan 29, 2026Mixup generates augmented samples by linearly interpolating inputs and labels with a controllable ratio. However, since it operates in the latent embedding level, the resulting samples are not human-interpretable. In contrast, LLM-based augmentation methods produce sentences via prompts at the token level, yielding readable outputs but offering limited control over the generation process. Inspired by recent advances in LLM inversion, which reconstructs natural language from embeddings and helps bridge the gap between latent embedding space and discrete token space, we propose inversedMixup, a unified framework that combines the controllability of Mixup with the interpretability of LLM-based generation. Specifically, inversedMixup adopts a three-stage training procedure to align the output embedding space of a task-specific model with the input embedding space of an LLM. Upon successful alignment, inversedMixup can reconstruct mixed embeddings with a controllable mixing ratio into human-interpretable augmented sentences, thereby improving the augmentation performance. Additionally, inversedMixup provides the first empirical evidence of the manifold intrusion phenomenon in text Mixup and introduces a simple yet effective strategy to mitigate it. Extensive experiments demonstrate the effectiveness and generalizability of our approach in both few-shot and fully supervised scenarios.
Kalman Filtering of Stationary Graph Signals
Sep 16, 2025In this paper, we propose a novel definition of stationary graph signals, formulated with respect to a symmetric graph shift, such as the graph Laplacian. We show that stationary graph signals can be generated by transmitting white noise through polynomial graph channels, and that their stationarity is preserved under polynomial channel transmission. In this paper, we also investigate Kalman filtering to dynamical systems characterized by polynomial state and observation matrices. We demonstrate that Kalman filtering maintains the stationarity of graph signals, while effectively incorporating both system dynamics and noise structure. In comparison to the static inverse filtering method and naive zero-signal strategy, the Kalman filtering procedure yields more accurate and adaptive signal estimates, highlighting its robustness and versatility in graph signal processing.
Blind Deconvolution of Nonstationary Graph Signals over Shift-Invariant Channels
Aug 24, 2025In this paper, we investigate blind deconvolution of nonstationary graph signals from noisy observations, transmitted through an unknown shift-invariant channel. The deconvolution process assumes that the observer has access to the covariance structure of the original graph signals. To evaluate the effectiveness of our channel estimation and blind deconvolution method, we conduct numerical experiments using a temperature dataset in the Brest region of France.
Iterative Polynomial Approximation Algorithms for Inverse Graph Filters
Apr 19, 2025Chebyshev interpolation polynomials exhibit the exponential approximation property to analytic functions on a cube. Based on the Chebyshev interpolation polynomial approximation, we propose iterative polynomial approximation algorithms to implement the inverse filter with a polynomial graph filter of commutative graph shifts in a distributed manner. The proposed algorithms exhibit exponential convergence properties, and they can be implemented on distributed networks in which agents are equipped with a data processing subsystem for limited data storage and computation power, and with a one-hop communication subsystem for direct data exchange only with their adjacent agents. Our simulations show that the proposed polynomial approximation algorithms may converge faster than the Chebyshev polynomial approximation algorithm and the conventional gradient descent algorithm do.
Causal Learning for Heterogeneous Subgroups Based on Nonlinear Causal Kernel Clustering
Jan 20, 2025Due to the challenge posed by multi-source and heterogeneous data collected from diverse environments, causal relationships among features can exhibit variations influenced by different time spans, regions, or strategies. This diversity makes a single causal model inadequate for accurately representing complex causal relationships in all observational data, a crucial consideration in causal learning. To address this challenge, we introduce the nonlinear Causal Kernel Clustering method designed for heterogeneous subgroup causal learning, illuminating variations in causal relationships across diverse subgroups. It comprises two primary components. First, the construction of a sample mapping function forms the basis of the subsequent nonlinear causal kernel. This function assesses the differences in potential nonlinear causal relationships in various samples, supported by our causal identifiability theory. Second, a nonlinear causal kernel is proposed for clustering heterogeneous subgroups. Experimental results showcase the exceptional performance of our method in accurately identifying heterogeneous subgroups and effectively enhancing causal learning, leading to a great reduction in prediction error.
Shift-invariant spaces, bandlimited spaces and reproducing kernel spaces with shift-invariant kernels on undirected finite graphs
Dec 17, 2024In this paper, we introduce the concept of graph shift-invariant space (GSIS) on an undirected finite graph, which is the linear space of graph signals being invariant under graph shifts, and we study its bandlimiting, kernel reproducing and sampling properties. Graph bandlimited spaces have been widely applied where large datasets on networks need to be handled efficiently. In this paper, we show that every GSIS is a bandlimited space, and every bandlimited space is a principal GSIS. Functions in a reproducing kernel Hilbert space with shift-invariant kernel could be learnt with significantly low computational cost. In this paper, we demonstrate that every GSIS is a reproducing kernel Hilbert space with a shift-invariant kernel. Based on the nested Krylov structure of GSISs in the spatial domain, we propose a novel sampling and reconstruction algorithm with finite steps, with its performance tested for well-localized signals on circulant graphs and flight delay dataset of the 50 busiest airports in the USA.
Computer vision tasks for intelligent aerospace missions: An overview
Jul 09, 2024

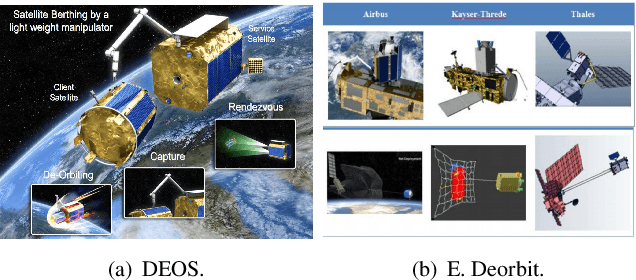
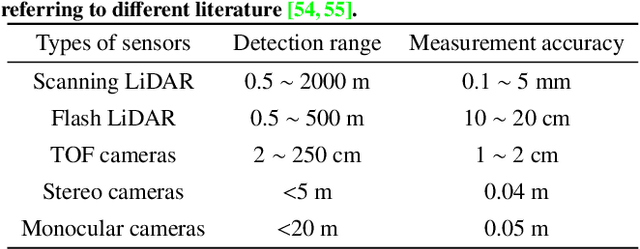
Computer vision tasks are crucial for aerospace missions as they help spacecraft to understand and interpret the space environment, such as estimating position and orientation, reconstructing 3D models, and recognizing objects, which have been extensively studied to successfully carry out the missions. However, traditional methods like Kalman Filtering, Structure from Motion, and Multi-View Stereo are not robust enough to handle harsh conditions, leading to unreliable results. In recent years, deep learning (DL)-based perception technologies have shown great potential and outperformed traditional methods, especially in terms of their robustness to changing environments. To further advance DL-based aerospace perception, various frameworks, datasets, and strategies have been proposed, indicating significant potential for future applications. In this survey, we aim to explore the promising techniques used in perception tasks and emphasize the importance of DL-based aerospace perception. We begin by providing an overview of aerospace perception, including classical space programs developed in recent years, commonly used sensors, and traditional perception methods. Subsequently, we delve into three fundamental perception tasks in aerospace missions: pose estimation, 3D reconstruction, and recognition, as they are basic and crucial for subsequent decision-making and control. Finally, we discuss the limitations and possibilities in current research and provide an outlook on future developments, including the challenges of working with limited datasets, the need for improved algorithms, and the potential benefits of multi-source information fusion.
Scalable Networked Feature Selection with Randomized Algorithm for Robot Navigation
Mar 18, 2024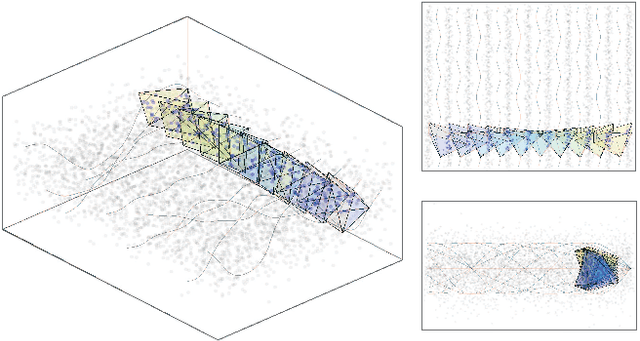
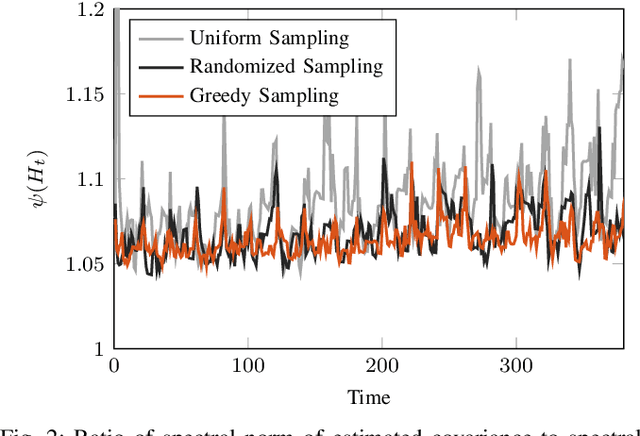
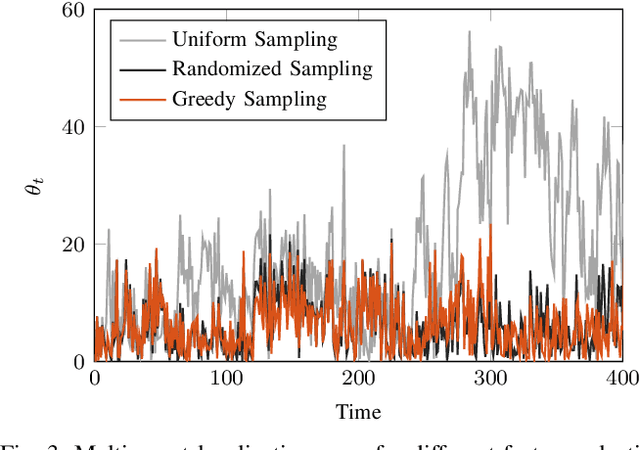
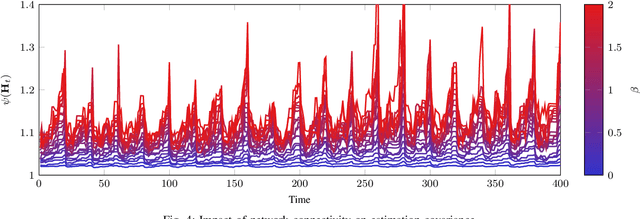
We address the problem of sparse selection of visual features for localizing a team of robots navigating an unknown environment, where robots can exchange relative position measurements with neighbors. We select a set of the most informative features by anticipating their importance in robots localization by simulating trajectories of robots over a prediction horizon. Through theoretical proofs, we establish a crucial connection between graph Laplacian and the importance of features. We show that strong network connectivity translates to uniformity in feature importance, which enables uniform random sampling of features and reduces the overall computational complexity. We leverage a scalable randomized algorithm for sparse sums of positive semidefinite matrices to efficiently select the set of the most informative features and significantly improve the probabilistic performance bounds. Finally, we support our findings with extensive simulations.
Barron Space for Graph Convolution Neural Networks
Nov 06, 2023


Graph convolutional neural network (GCNN) operates on graph domain and it has achieved a superior performance to accomplish a wide range of tasks. In this paper, we introduce a Barron space of functions on a compact domain of graph signals. We prove that the proposed Barron space is a reproducing kernel Banach space, it can be decomposed into the union of a family of reproducing kernel Hilbert spaces with neuron kernels, and it could be dense in the space of continuous functions on the domain. Approximation property is one of the main principles to design neural networks. In this paper, we show that outputs of GCNNs are contained in the Barron space and functions in the Barron space can be well approximated by outputs of some GCNNs in the integrated square and uniform measurements. We also estimate the Rademacher complexity of functions with bounded Barron norm and conclude that functions in the Barron space could be learnt from their random samples efficiently.