 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGasMono: Geometry-Aided Self-Supervised Monocular Depth Estimation for Indoor Scenes
Paper and Code
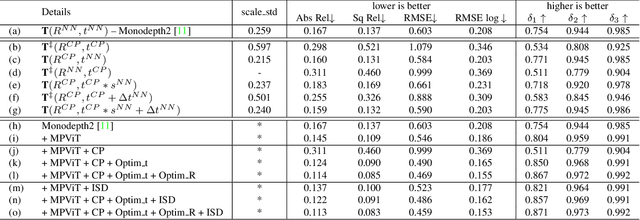

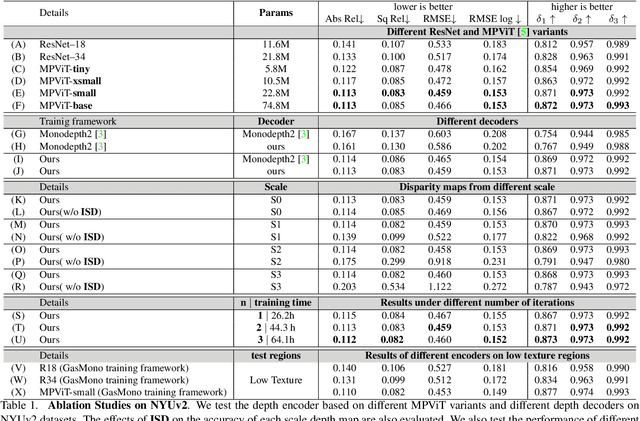

This paper tackles the challenges of self-supervised monocular depth estimation in indoor scenes caused by large rotation between frames and low texture. We ease the learning process by obtaining coarse camera poses from monocular sequences through multi-view geometry to deal with the former. However, we found that limited by the scale ambiguity across different scenes in the training dataset, a na\"ive introduction of geometric coarse poses cannot play a positive role in performance improvement, which is counter-intuitive. To address this problem, we propose to refine those poses during training through rotation and translation/scale optimization. To soften the effect of the low texture, we combine the global reasoning of vision transformers with an overfitting-aware, iterative self-distillation mechanism, providing more accurate depth guidance coming from the network itself. Experiments on NYUv2, ScanNet, 7scenes, and KITTI datasets support the effectiveness of each component in our framework, which sets a new state-of-the-art for indoor self-supervised monocular depth estimation, as well as outstanding generalization ability. Code and models are available at https://github.com/zxcqlf/GasMono