 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Monocular Depth Estimation in the Dark: Towards Data Distribution Compensation
Apr 22, 2024



Nighttime self-supervised monocular depth estimation has received increasing attention in recent years. However, using night images for self-supervision is unreliable because the photometric consistency assumption is usually violated in the videos taken under complex lighting conditions. Even with domain adaptation or photometric loss repair, performance is still limited by the poor supervision of night images on trainable networks. In this paper, we propose a self-supervised nighttime monocular depth estimation method that does not use any night images during training. Our framework utilizes day images as a stable source for self-supervision and applies physical priors (e.g., wave optics, reflection model and read-shot noise model) to compensate for some key day-night differences. With day-to-night data distribution compensation, our framework can be trained in an efficient one-stage self-supervised manner. Though no nighttime images are considered during training, qualitative and quantitative results demonstrate that our method achieves SoTA depth estimating results on the challenging nuScenes-Night and RobotCar-Night compared with existing methods.
GasMono: Geometry-Aided Self-Supervised Monocular Depth Estimation for Indoor Scenes
Sep 26, 2023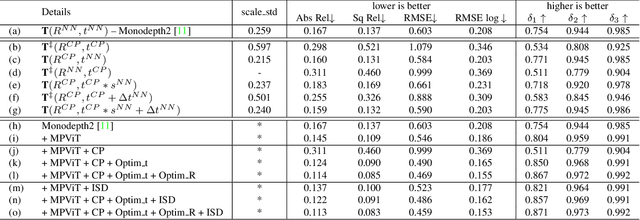

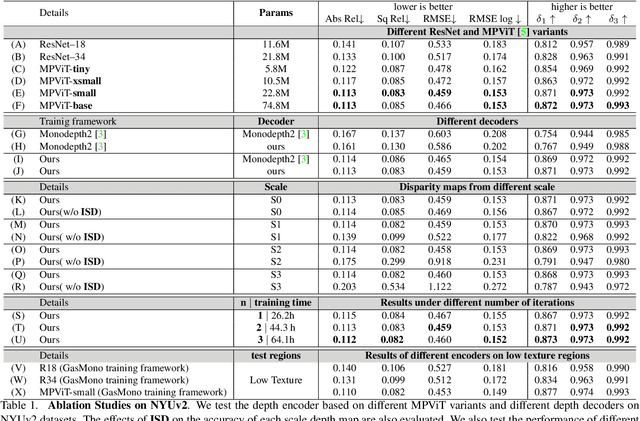

This paper tackles the challenges of self-supervised monocular depth estimation in indoor scenes caused by large rotation between frames and low texture. We ease the learning process by obtaining coarse camera poses from monocular sequences through multi-view geometry to deal with the former. However, we found that limited by the scale ambiguity across different scenes in the training dataset, a na\"ive introduction of geometric coarse poses cannot play a positive role in performance improvement, which is counter-intuitive. To address this problem, we propose to refine those poses during training through rotation and translation/scale optimization. To soften the effect of the low texture, we combine the global reasoning of vision transformers with an overfitting-aware, iterative self-distillation mechanism, providing more accurate depth guidance coming from the network itself. Experiments on NYUv2, ScanNet, 7scenes, and KITTI datasets support the effectiveness of each component in our framework, which sets a new state-of-the-art for indoor self-supervised monocular depth estimation, as well as outstanding generalization ability. Code and models are available at https://github.com/zxcqlf/GasMono
Causal reasoning in typical computer vision tasks
Jul 31, 2023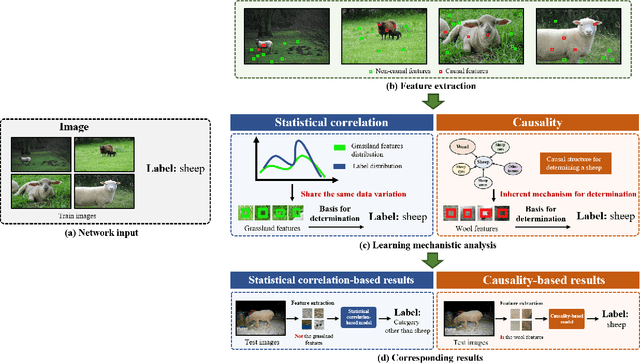



Deep learning has revolutionized the field of artificial intelligence. Based on the statistical correlations uncovered by deep learning-based methods, computer vision has contributed to tremendous growth in areas like autonomous driving and robotics. Despite being the basis of deep learning, such correlation is not stable and is susceptible to uncontrolled factors. In the absence of the guidance of prior knowledge, statistical correlations can easily turn into spurious correlations and cause confounders. As a result, researchers are now trying to enhance deep learning methods with causal theory. Causal theory models the intrinsic causal structure unaffected by data bias and is effective in avoiding spurious correlations. This paper aims to comprehensively review the existing causal methods in typical vision and vision-language tasks such as semantic segmentation, object detection, and image captioning. The advantages of causality and the approaches for building causal paradigms will be summarized. Future roadmaps are also proposed, including facilitating the development of causal theory and its application in other complex scenes and systems.
CMDA: Cross-Modality Domain Adaptation for Nighttime Semantic Segmentation
Jul 29, 2023



Most nighttime semantic segmentation studies are based on domain adaptation approaches and image input. However, limited by the low dynamic range of conventional cameras, images fail to capture structural details and boundary information in low-light conditions. Event cameras, as a new form of vision sensors, are complementary to conventional cameras with their high dynamic range. To this end, we propose a novel unsupervised Cross-Modality Domain Adaptation (CMDA) framework to leverage multi-modality (Images and Events) information for nighttime semantic segmentation, with only labels on daytime images. In CMDA, we design the Image Motion-Extractor to extract motion information and the Image Content-Extractor to extract content information from images, in order to bridge the gap between different modalities (Images to Events) and domains (Day to Night). Besides, we introduce the first image-event nighttime semantic segmentation dataset. Extensive experiments on both the public image dataset and the proposed image-event dataset demonstrate the effectiveness of our proposed approach. We open-source our code, models, and dataset at https://github.com/XiaRho/CMDA.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023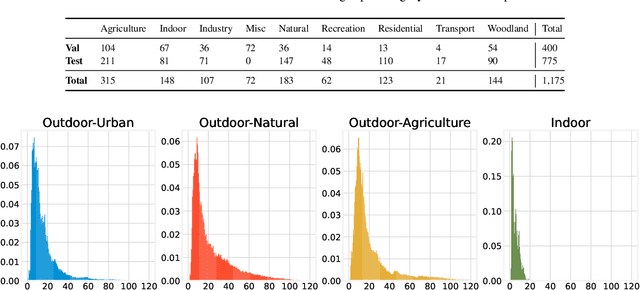
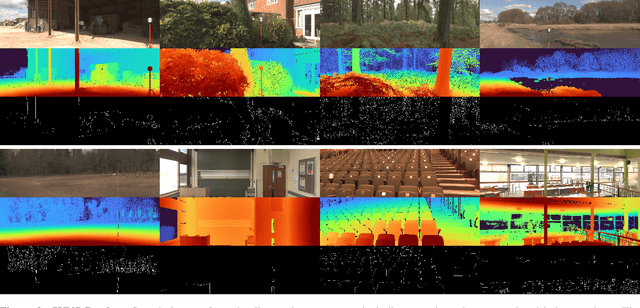
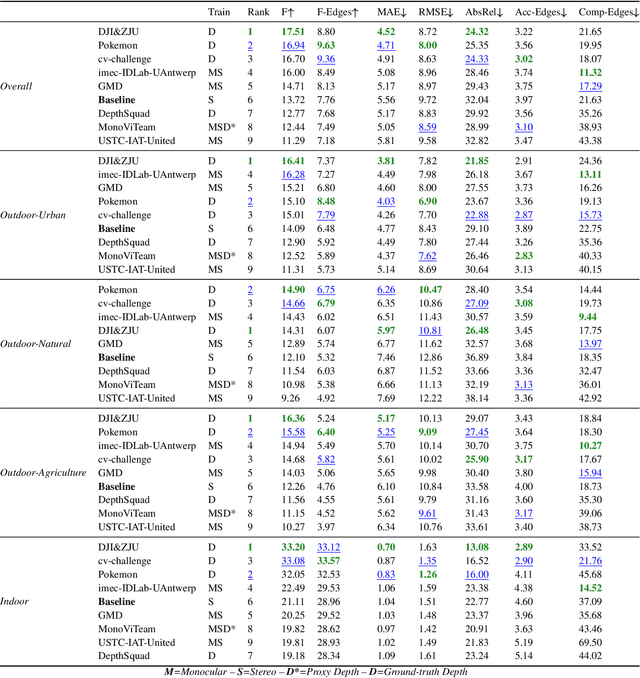
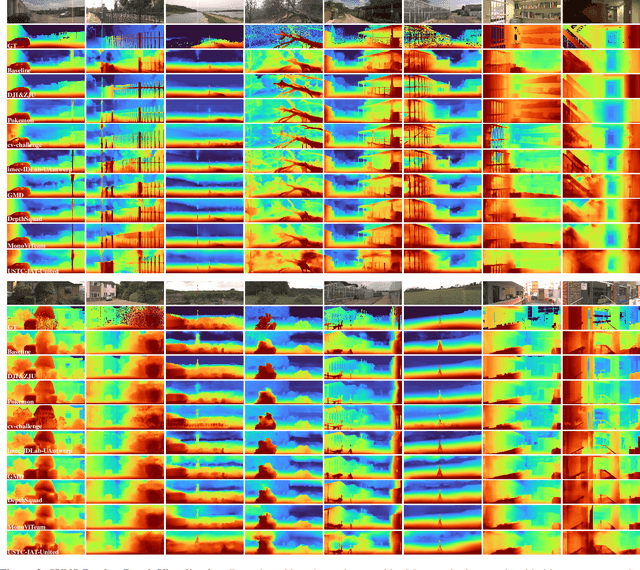
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
The Monocular Depth Estimation Challenge
Nov 22, 2022



This paper summarizes the results of the first Monocular Depth Estimation Challenge (MDEC) organized at WACV2023. This challenge evaluated the progress of self-supervised monocular depth estimation on the challenging SYNS-Patches dataset. The challenge was organized on CodaLab and received submissions from 4 valid teams. Participants were provided a devkit containing updated reference implementations for 16 State-of-the-Art algorithms and 4 novel techniques. The threshold for acceptance for novel techniques was to outperform every one of the 16 SotA baselines. All participants outperformed the baseline in traditional metrics such as MAE or AbsRel. However, pointcloud reconstruction metrics were challenging to improve upon. We found predictions were characterized by interpolation artefacts at object boundaries and errors in relative object positioning. We hope this challenge is a valuable contribution to the community and encourage authors to participate in future editions.
Towards Generalization on Real Domain for Single Image Dehazing via Meta-Learning
Nov 14, 2022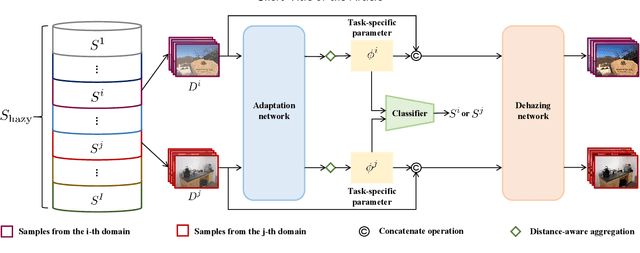

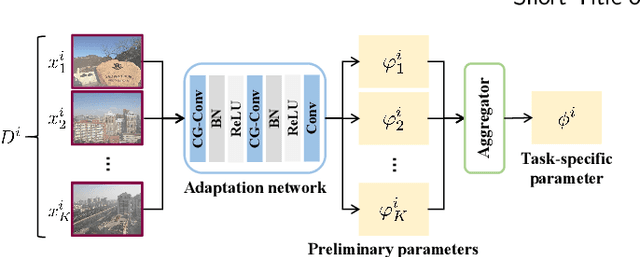
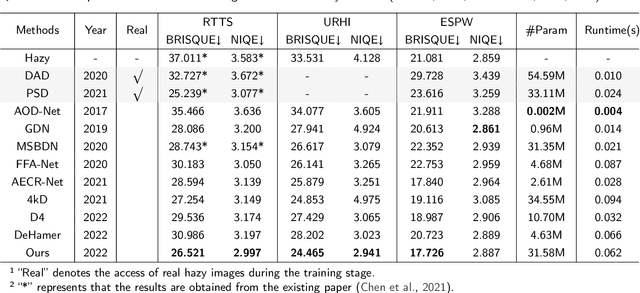
Learning-based image dehazing methods are essential to assist autonomous systems in enhancing reliability. Due to the domain gap between synthetic and real domains, the internal information learned from synthesized images is usually sub-optimal in real domains, leading to severe performance drop of dehaizing models. Driven by the ability on exploring internal information from a few unseen-domain samples, meta-learning is commonly adopted to address this issue via test-time training, which is hyperparameter-sensitive and time-consuming. In contrast, we present a domain generalization framework based on meta-learning to dig out representative and discriminative internal properties of real hazy domains without test-time training. To obtain representative domain-specific information, we attach two entities termed adaptation network and distance-aware aggregator to our dehazing network. The adaptation network assists in distilling domain-relevant information from a few hazy samples and caching it into a collection of features. The distance-aware aggregator strives to summarize the generated features and filter out misleading information for more representative internal properties. To enhance the discrimination of distilled internal information, we present a novel loss function called domain-relevant contrastive regularization, which encourages the internal features generated from the same domain more similar and that from diverse domains more distinct. The generated representative and discriminative features are regarded as some external variables of our dehazing network to regress a particular and powerful function for a given domain. The extensive experiments on real hazy datasets, such as RTTS and URHI, validate that our proposed method has superior generalization ability than the state-of-the-art competitors.
Visual Semantic Segmentation Based on Few/Zero-Shot Learning: An Overview
Nov 13, 2022Visual semantic segmentation aims at separating a visual sample into diverse blocks with specific semantic attributes and identifying the category for each block, and it plays a crucial role in environmental perception. Conventional learning-based visual semantic segmentation approaches count heavily on large-scale training data with dense annotations and consistently fail to estimate accurate semantic labels for unseen categories. This obstruction spurs a craze for studying visual semantic segmentation with the assistance of few/zero-shot learning. The emergence and rapid progress of few/zero-shot visual semantic segmentation make it possible to learn unseen-category from a few labeled or zero-labeled samples, which advances the extension to practical applications. Therefore, this paper focuses on the recently published few/zero-shot visual semantic segmentation methods varying from 2D to 3D space and explores the commonalities and discrepancies of technical settlements under different segmentation circumstances. Specifically, the preliminaries on few/zero-shot visual semantic segmentation, including the problem definitions, typical datasets, and technical remedies, are briefly reviewed and discussed. Moreover, three typical instantiations are involved to uncover the interactions of few/zero-shot learning with visual semantic segmentation, including image semantic segmentation, video object segmentation, and 3D segmentation. Finally, the future challenges of few/zero-shot visual semantic segmentation are discussed.
MonoViT: Self-Supervised Monocular Depth Estimation with a Vision Transformer
Aug 06, 2022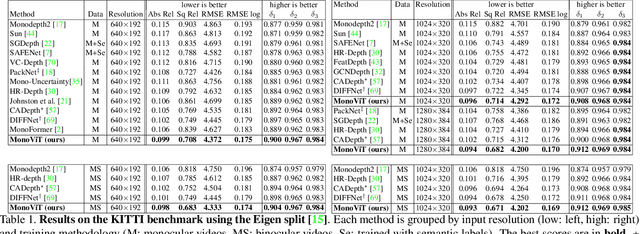
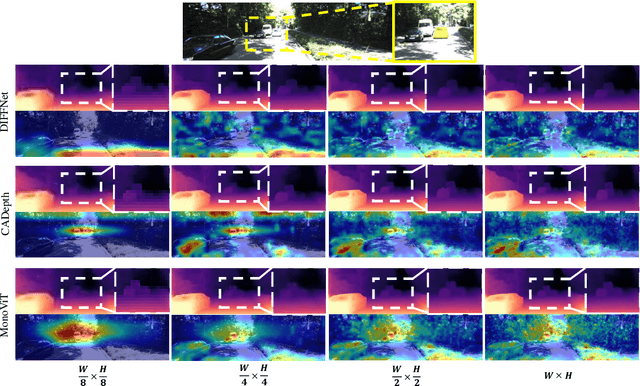
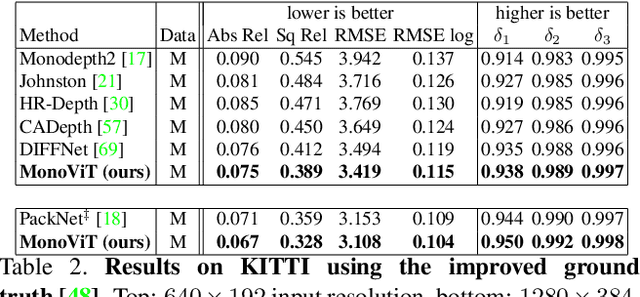
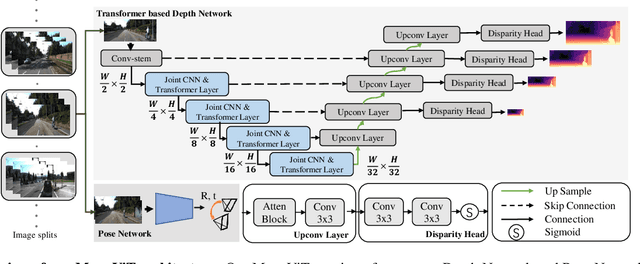
Self-supervised monocular depth estimation is an attractive solution that does not require hard-to-source depth labels for training. Convolutional neural networks (CNNs) have recently achieved great success in this task. However, their limited receptive field constrains existing network architectures to reason only locally, dampening the effectiveness of the self-supervised paradigm. In the light of the recent successes achieved by Vision Transformers (ViTs), we propose MonoViT, a brand-new framework combining the global reasoning enabled by ViT models with the flexibility of self-supervised monocular depth estimation. By combining plain convolutions with Transformer blocks, our model can reason locally and globally, yielding depth prediction at a higher level of detail and accuracy, allowing MonoViT to achieve state-of-the-art performance on the established KITTI dataset. Moreover, MonoViT proves its superior generalization capacities on other datasets such as Make3D and DrivingStereo.
Learn to Adapt for Monocular Depth Estimation
Mar 26, 2022
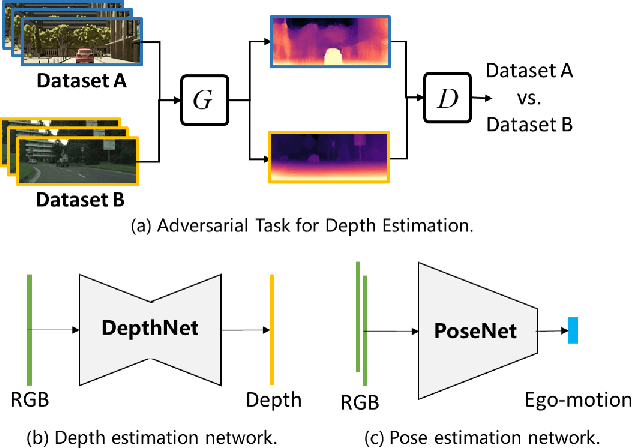
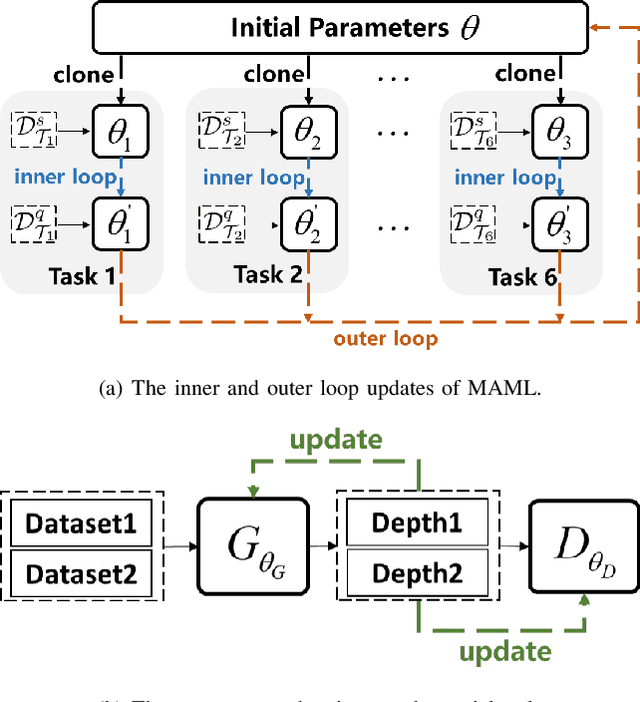

Monocular depth estimation is one of the fundamental tasks in environmental perception and has achieved tremendous progress in virtue of deep learning. However, the performance of trained models tends to degrade or deteriorate when employed on other new datasets due to the gap between different datasets. Though some methods utilize domain adaptation technologies to jointly train different domains and narrow the gap between them, the trained models cannot generalize to new domains that are not involved in training. To boost the transferability of depth estimation models, we propose an adversarial depth estimation task and train the model in the pipeline of meta-learning. Our proposed adversarial task mitigates the issue of meta-overfitting, since the network is trained in an adversarial manner and aims to extract domain invariant representations. In addition, we propose a constraint to impose upon cross-task depth consistency to compel the depth estimation to be identical in different adversarial tasks, which improves the performance of our method and smoothens the training process. Experiments demonstrate that our method adapts well to new datasets after few training steps during the test procedure.