 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal-Guided Visual Foundation Models for Event-Based Vision
Nov 09, 2025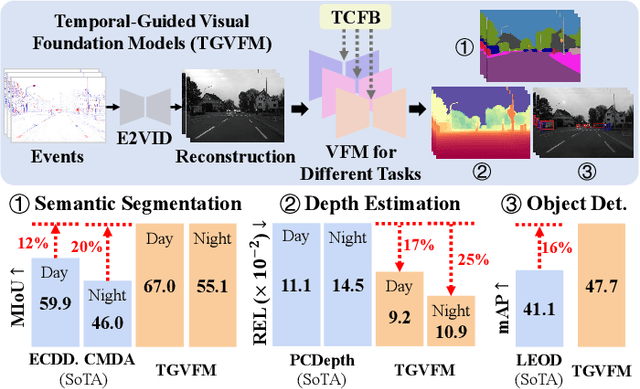
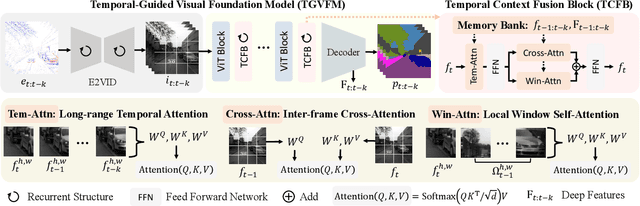


Event cameras offer unique advantages for vision tasks in challenging environments, yet processing asynchronous event streams remains an open challenge. While existing methods rely on specialized architectures or resource-intensive training, the potential of leveraging modern Visual Foundation Models (VFMs) pretrained on image data remains under-explored for event-based vision. To address this, we propose Temporal-Guided VFM (TGVFM), a novel framework that integrates VFMs with our temporal context fusion block seamlessly to bridge this gap. Our temporal block introduces three key components: (1) Long-Range Temporal Attention to model global temporal dependencies, (2) Dual Spatiotemporal Attention for multi-scale frame correlation, and (3) Deep Feature Guidance Mechanism to fuse semantic-temporal features. By retraining event-to-video models on real-world data and leveraging transformer-based VFMs, TGVFM preserves spatiotemporal dynamics while harnessing pretrained representations. Experiments demonstrate SoTA performance across semantic segmentation, depth estimation, and object detection, with improvements of 16%, 21%, and 16% over existing methods, respectively. Overall, this work unlocks the cross-modality potential of image-based VFMs for event-based vision with temporal reasoning. Code is available at https://github.com/XiaRho/TGVFM.
DidSee: Diffusion-Based Depth Completion for Material-Agnostic Robotic Perception and Manipulation
Jun 26, 2025Commercial RGB-D cameras often produce noisy, incomplete depth maps for non-Lambertian objects. Traditional depth completion methods struggle to generalize due to the limited diversity and scale of training data. Recent advances exploit visual priors from pre-trained text-to-image diffusion models to enhance generalization in dense prediction tasks. However, we find that biases arising from training-inference mismatches in the vanilla diffusion framework significantly impair depth completion performance. Additionally, the lack of distinct visual features in non-Lambertian regions further hinders precise prediction. To address these issues, we propose \textbf{DidSee}, a diffusion-based framework for depth completion on non-Lambertian objects. First, we integrate a rescaled noise scheduler enforcing a zero terminal signal-to-noise ratio to eliminate signal leakage bias. Second, we devise a noise-agnostic single-step training formulation to alleviate error accumulation caused by exposure bias and optimize the model with a task-specific loss. Finally, we incorporate a semantic enhancer that enables joint depth completion and semantic segmentation, distinguishing objects from backgrounds and yielding precise, fine-grained depth maps. DidSee achieves state-of-the-art performance on multiple benchmarks, demonstrates robust real-world generalization, and effectively improves downstream tasks such as category-level pose estimation and robotic grasping.Project page: https://wenzhoulyu.github.io/DidSee/
DreamCS: Geometry-Aware Text-to-3D Generation with Unpaired 3D Reward Supervision
Jun 11, 2025While text-to-3D generation has attracted growing interest, existing methods often struggle to produce 3D assets that align well with human preferences. Current preference alignment techniques for 3D content typically rely on hardly-collected preference-paired multi-view 2D images to train 2D reward models, when then guide 3D generation -- leading to geometric artifacts due to their inherent 2D bias. To address these limitations, we construct 3D-MeshPref, the first large-scale unpaired 3D preference dataset, featuring diverse 3D meshes annotated by a large language model and refined by human evaluators. We then develop RewardCS, the first reward model trained directly on unpaired 3D-MeshPref data using a novel Cauchy-Schwarz divergence objective, enabling effective learning of human-aligned 3D geometric preferences without requiring paired comparisons. Building on this, we propose DreamCS, a unified framework that integrates RewardCS into text-to-3D pipelines -- enhancing both implicit and explicit 3D generation with human preference feedback. Extensive experiments show DreamCS outperforms prior methods, producing 3D assets that are both geometrically faithful and human-preferred. Code and models will be released publicly.
Unsupervised Modality Adaptation with Text-to-Image Diffusion Models for Semantic Segmentation
Oct 29, 2024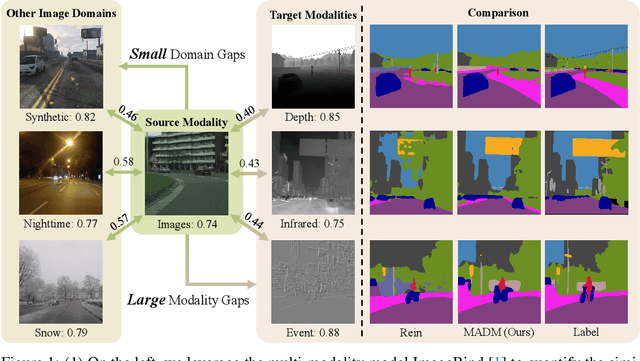
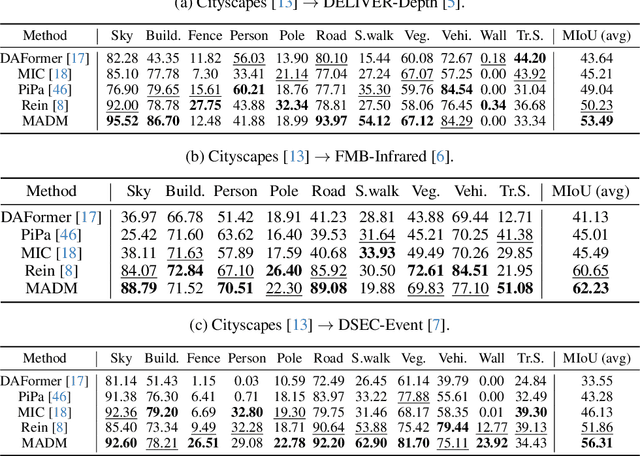

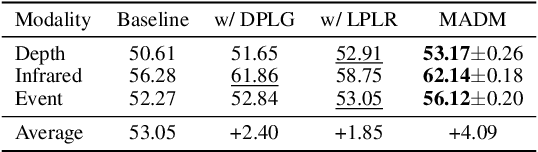
Despite their success, unsupervised domain adaptation methods for semantic segmentation primarily focus on adaptation between image domains and do not utilize other abundant visual modalities like depth, infrared and event. This limitation hinders their performance and restricts their application in real-world multimodal scenarios. To address this issue, we propose Modality Adaptation with text-to-image Diffusion Models (MADM) for semantic segmentation task which utilizes text-to-image diffusion models pre-trained on extensive image-text pairs to enhance the model's cross-modality capabilities. Specifically, MADM comprises two key complementary components to tackle major challenges. First, due to the large modality gap, using one modal data to generate pseudo labels for another modality suffers from a significant drop in accuracy. To address this, MADM designs diffusion-based pseudo-label generation which adds latent noise to stabilize pseudo-labels and enhance label accuracy. Second, to overcome the limitations of latent low-resolution features in diffusion models, MADM introduces the label palette and latent regression which converts one-hot encoded labels into the RGB form by palette and regresses them in the latent space, thus ensuring the pre-trained decoder for up-sampling to obtain fine-grained features. Extensive experimental results demonstrate that MADM achieves state-of-the-art adaptation performance across various modality tasks, including images to depth, infrared, and event modalities. We open-source our code and models at https://github.com/XiaRho/MADM.
Towards Natural Image Matting in the Wild via Real-Scenario Prior
Oct 09, 2024



Recent approaches attempt to adapt powerful interactive segmentation models, such as SAM, to interactive matting and fine-tune the models based on synthetic matting datasets. However, models trained on synthetic data fail to generalize to complex and occlusion scenes. We address this challenge by proposing a new matting dataset based on the COCO dataset, namely COCO-Matting. Specifically, the construction of our COCO-Matting includes accessory fusion and mask-to-matte, which selects real-world complex images from COCO and converts semantic segmentation masks to matting labels. The built COCO-Matting comprises an extensive collection of 38,251 human instance-level alpha mattes in complex natural scenarios. Furthermore, existing SAM-based matting methods extract intermediate features and masks from a frozen SAM and only train a lightweight matting decoder by end-to-end matting losses, which do not fully exploit the potential of the pre-trained SAM. Thus, we propose SEMat which revamps the network architecture and training objectives. For network architecture, the proposed feature-aligned transformer learns to extract fine-grained edge and transparency features. The proposed matte-aligned decoder aims to segment matting-specific objects and convert coarse masks into high-precision mattes. For training objectives, the proposed regularization and trimap loss aim to retain the prior from the pre-trained model and push the matting logits extracted from the mask decoder to contain trimap-based semantic information. Extensive experiments across seven diverse datasets demonstrate the superior performance of our method, proving its efficacy in interactive natural image matting. We open-source our code, models, and dataset at https://github.com/XiaRho/SEMat.
Motion Planning and Control of Hybrid Flying-Crawling Quadrotors
Dec 14, 2023Hybrid Flying-Crawling Quadrotors (HyFCQs) are transformable robots with the ability of terrestrial and aerial hybrid motion. This article presents a motion planning and control framework designed for HyFCQs. A kinodynamic path-searching method with the crawling limitation of HyFCQs is proposed to guarantee the dynamical feasibility of trajectories. Subsequently, a hierarchical motion controller is designed to map the execution of the flight autopilot to both crawling and flying modes. Considering the distinct driving methods for crawling and flying, we introduce a motion state machine for autonomous locomotion regulation. Real-world experiments in diverse scenarios validate the exceptional performance of the proposed approach.
Motion Planning and Control of A Morphing Quadrotor in Restricted Scenarios
Dec 12, 2023



Morphing quadrotors with four external actuators can adapt to different restricted scenarios by changing their geometric structure. However, previous works mainly focus on the improvements in structures and controllers, and existing planning algorithms don't consider the morphological modifications, which leads to safety and dynamic feasibility issues. In this paper, we propose a unified planning and control framework for morphing quadrotors to deform autonomously and efficiently. The framework consists of a milliseconds-level spatial-temporal trajectory optimizer that takes into account the morphological modifications of quadrotors. The optimizer can generate full-body safety trajectories including position and attitude. Additionally, it incorporates a nonlinear attitude controller that accounts for aerodynamic drag and dynamically adjusts dynamic parameters such as the inertia tensor and Center of Gravity. The controller can also online compute the thrust coefficient during morphing. Benchmark experiments compared with existing methods validate the robustness of the proposed controller. Extensive simulations and real-world experiments are performed to demonstrate the effectiveness of the proposed framework.
CMDA: Cross-Modality Domain Adaptation for Nighttime Semantic Segmentation
Jul 29, 2023



Most nighttime semantic segmentation studies are based on domain adaptation approaches and image input. However, limited by the low dynamic range of conventional cameras, images fail to capture structural details and boundary information in low-light conditions. Event cameras, as a new form of vision sensors, are complementary to conventional cameras with their high dynamic range. To this end, we propose a novel unsupervised Cross-Modality Domain Adaptation (CMDA) framework to leverage multi-modality (Images and Events) information for nighttime semantic segmentation, with only labels on daytime images. In CMDA, we design the Image Motion-Extractor to extract motion information and the Image Content-Extractor to extract content information from images, in order to bridge the gap between different modalities (Images to Events) and domains (Day to Night). Besides, we introduce the first image-event nighttime semantic segmentation dataset. Extensive experiments on both the public image dataset and the proposed image-event dataset demonstrate the effectiveness of our proposed approach. We open-source our code, models, and dataset at https://github.com/XiaRho/CMDA.